
在 NVIDIA RTX 4090 GPU 服务器上使用 Ollama 对大型语言模型(LLMs)进行性能基准测试:深入分析
在优化大型语言模型(LLM)性能的竞赛中,硬件效率起着至关重要的作用。NVIDIA RTX 4090 是一款配备 24GB GDDR6X 显存的高性能 GPU,当它与 Ollama——一款用于运行 LLM 的前沿平台——结合使用时,为开发者和企业提供了极具吸引力的解决方案。本文将深入探讨 RTX 4090 性能测试及 Ollama 性能测试,评估其在 GPU 服务器上托管和运行各类大型语言模型(如 deepseek-r1、LLaMA、Qwen、Gemma 等)的能力
服务器规格
服务器配置:
- 价格:409.00美元/月
- CPU:双18核E5-2697v4(36核,72线程)
- 内存:256GB
- 存储:240GB SSD + 2TB NVMe + 8TB SATA
- 网络:100Mbps-1Gbps连接
- 操作系统:Windows 11 Pro
- 软件:Ollama 版本 0.5.4
GPU详细信息:
- 显卡:Nvidia GeForce RTX 4090
- 计算能力:8.9
- 微架构:Ada Lovelace
- CUDA核心:16,384
- 张量核心:512
- GPU内存:24GB GDDR6X
- FP32 性能:82.6 TFLOPS
NVIDIA RTX 4090 拥有 82.6 TFLOPS FP32 性能、16,384 个 CUDA 核心和 512 个 Tensor 核心,在计算能力和成本效益方面均胜过大多数消费级 GPU。
在 Ollama 平台上使用 RTX 4090 对大型语言模型(LLM)的推理能力进行测试
- LLaMA 系列:LLaMA 2 (13B)、LLaMA 3.1 (8B)
- Qwen系列:Qwen(14B、32B)
- Phi系列:Phi4(14B)
- Mistral 型号:Mistral-small (22B)
- 猎鹰系列:猎鹰(40B)
- 杰玛和 LLaVA:杰玛2 (27B)、LLaVA (34B)
基准测试结果:Ollama GPU RTX 4090 性能指标
| 模型 | deepseek-r1 | deepseek-r1 | llama2 | llama3.1 | qwen2.5 | qwen2.5 | gemma2 | phi4 | qwq | llava |
|---|---|---|---|---|---|---|---|---|---|---|
| 参数 | 14b | 32b | 13b | 8b | 14b | 32b | 27b | 14b | 32b | 34b |
| 尺寸 | 9 | 20 | 7.4 | 4.9 | 9 | 20 | 16 | 9.1 | 20 | 19 |
| 量化 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| 正在运行 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 |
| 下载速度(mb/s) | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 |
| CPU 速率 | 2% | 3% | 1% | 2% | 3% | 3% | 2% | 3% | 2% | 2% |
| 内存速率 | 3% | 3% | 3% | 3% | 3% | 3% | 3% | 3% | 3% | 3% |
| GPU 虚拟内存 | 45% | 90% | 41% | 65% | 45% | 90% | 78% | 47% | 90% | 92% |
| GPU 执行时间 | 95% | 98% | 92% | 94% | 96% | 97% | 96% | 97% | 99% | 97% |
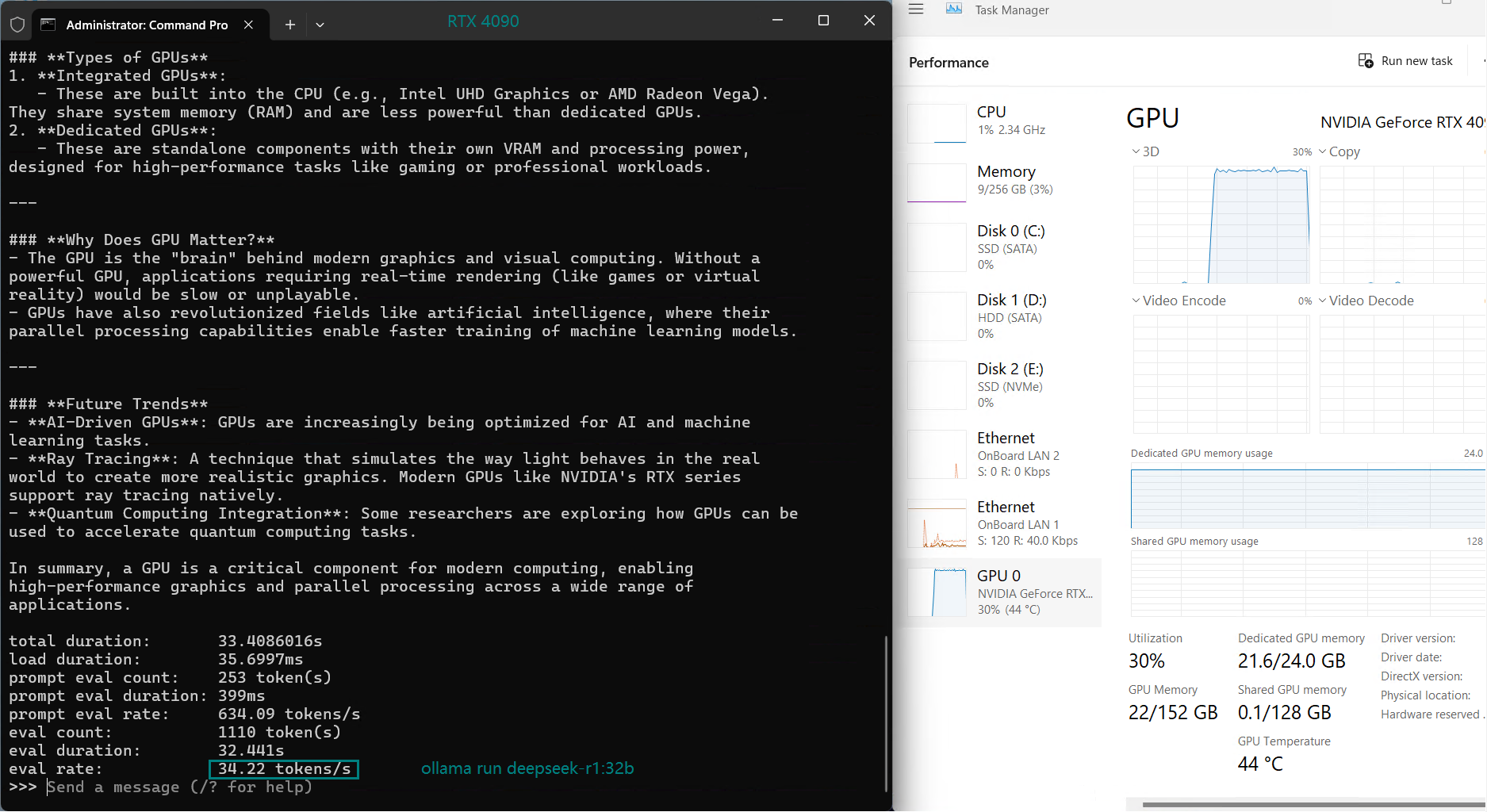
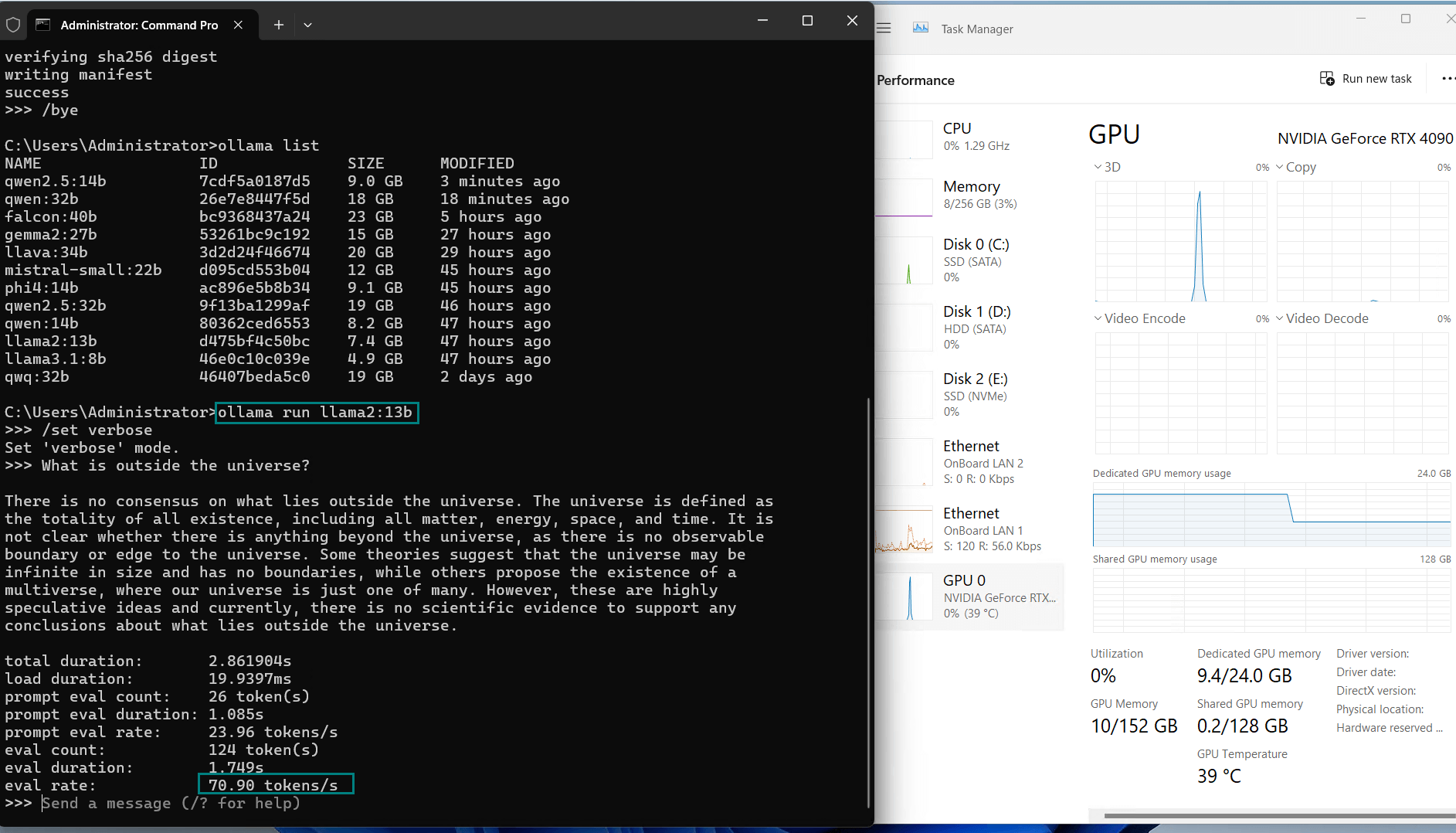
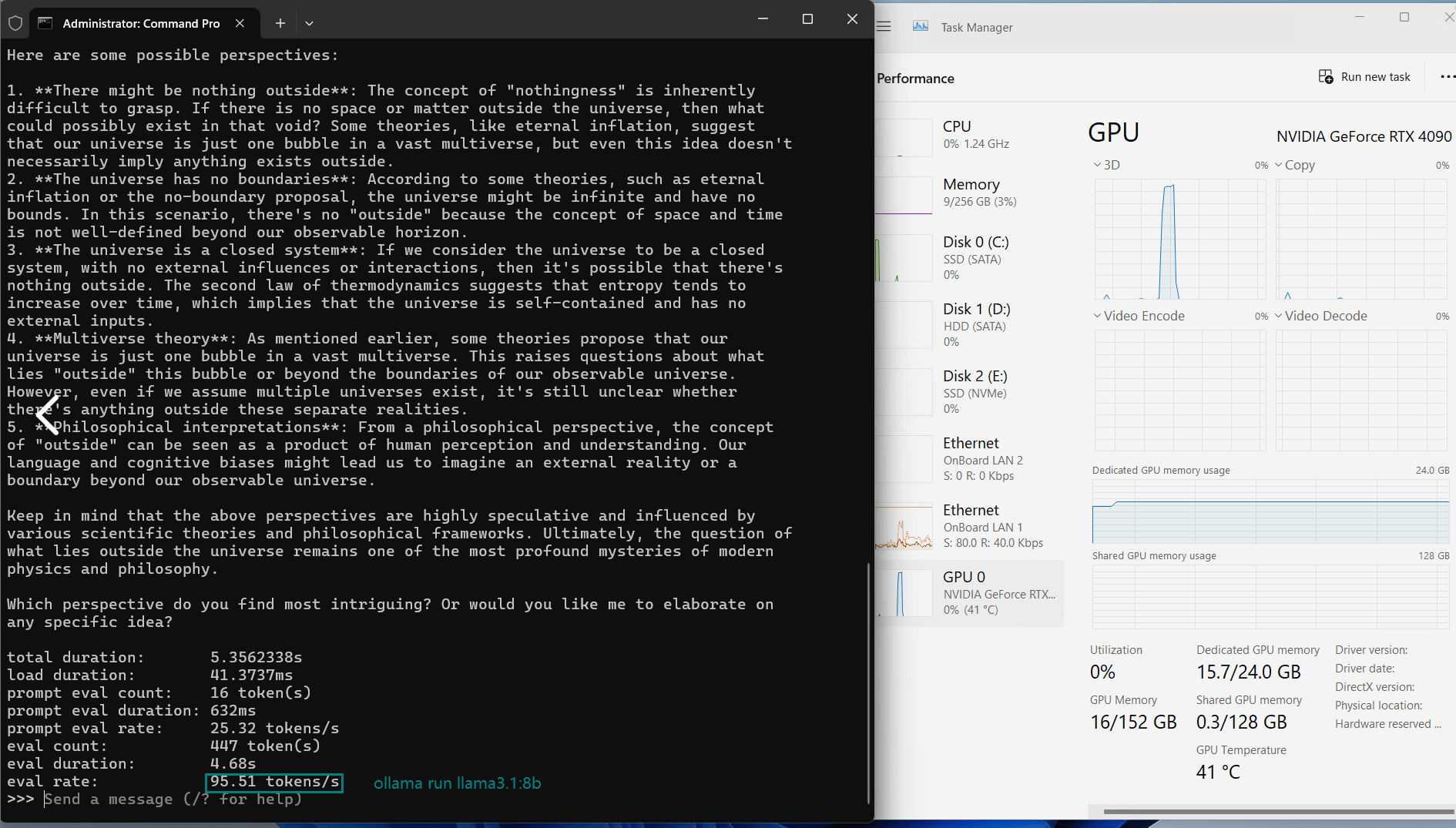
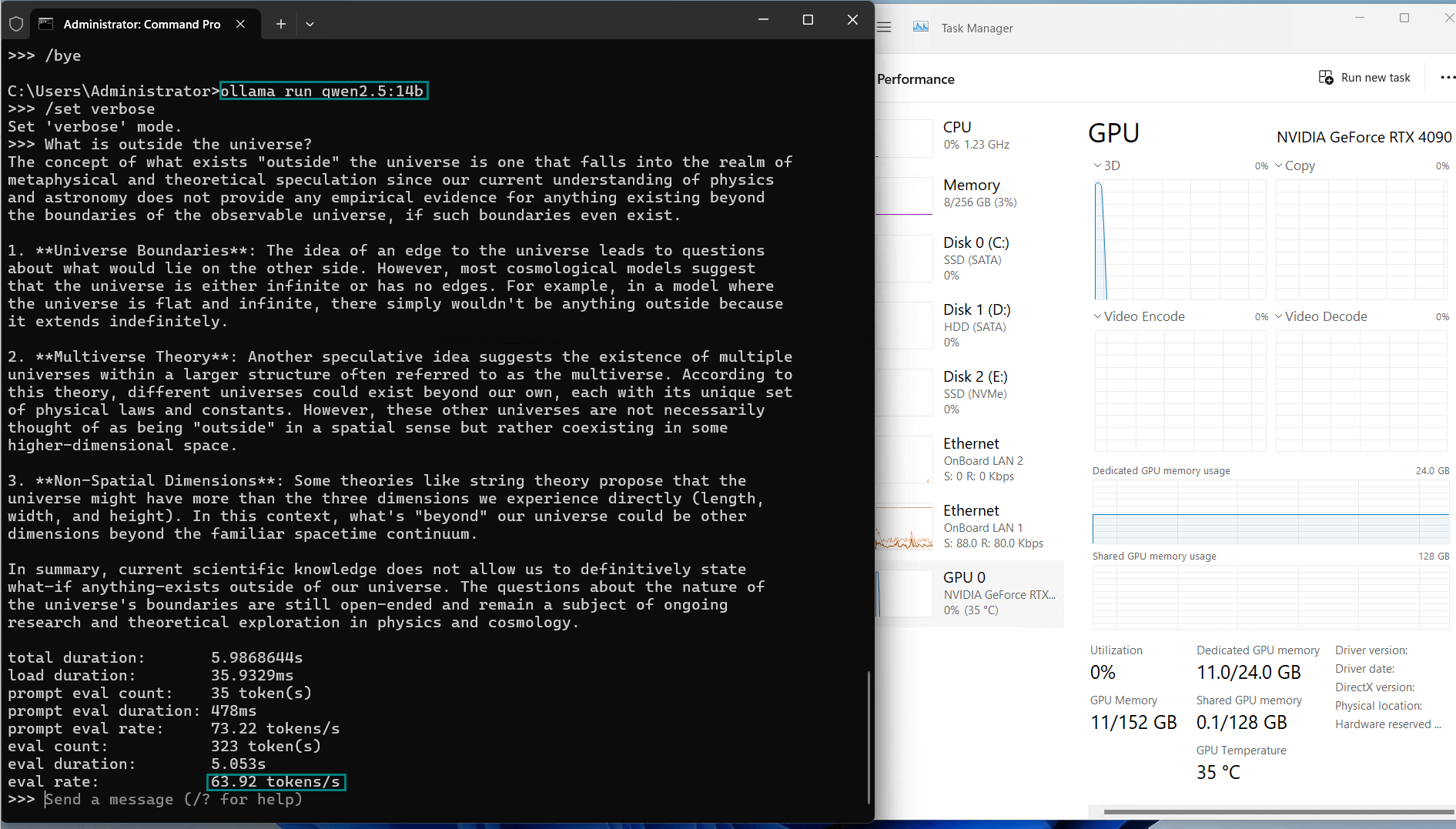
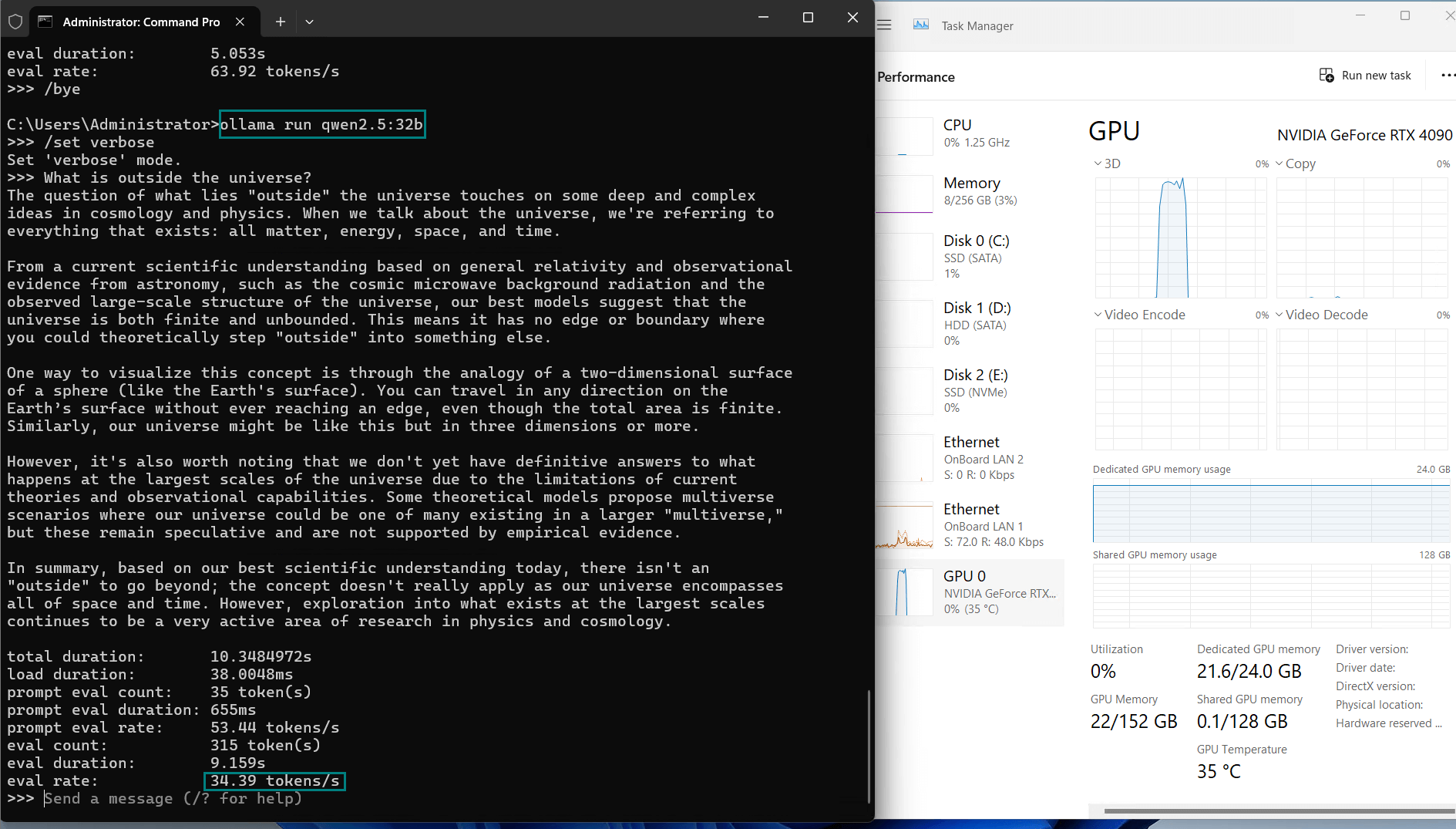
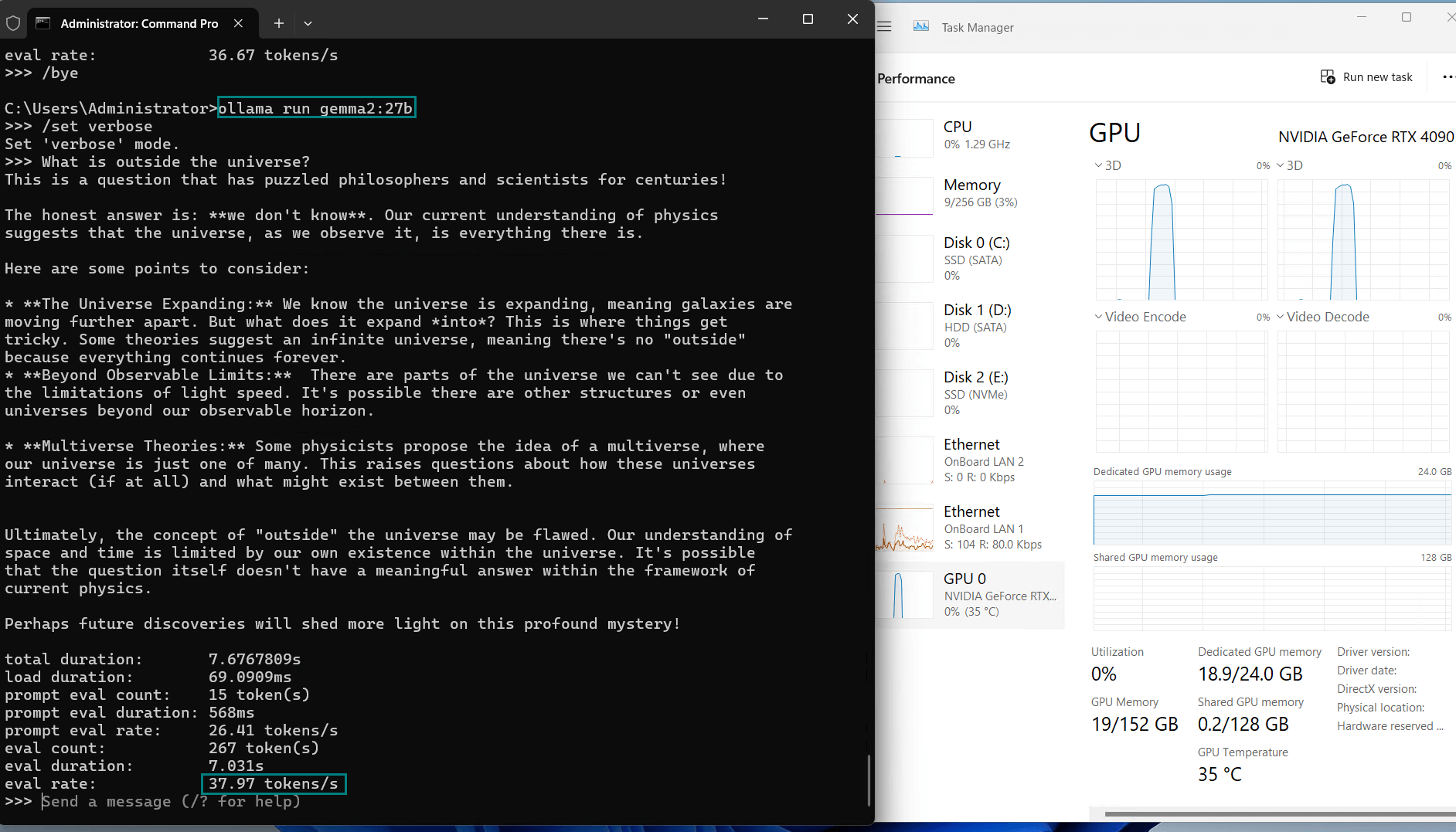
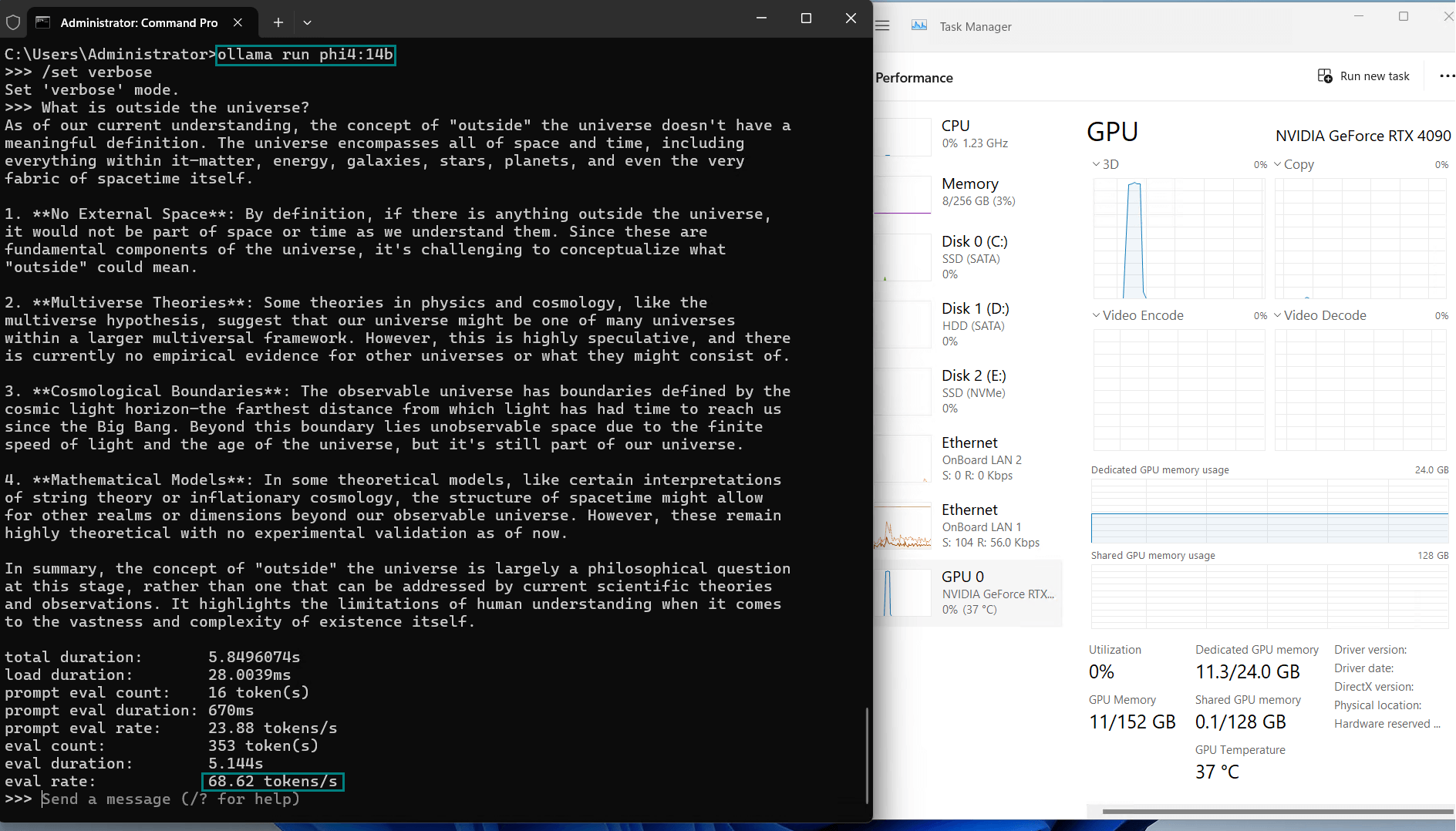
| 评估率(令牌/秒) | 58.62 | 34.22 | 70.90 | 95.51 | 63.92 | 34.39 | 37.97 | 68.62 | 31.80 | 36.67 |
关键见解
1. 小型到中型模型(8B–34B)
2. 对于 40B 模型能力不足
3. 性价比高
| Metric | 各种型号的价值 |
|---|---|
| 下载速度 | 所有型号均为 12 MB/s,订购 1gbps 带宽附加组件时为 118 MB/s。 |
| CPU利用率 | 维持1-3% |
| RAM利用率 | 维持2-4% |
| GPU vRAM 利用率 | 41-92%。车型越大,利用率越高。 |
| GPU利用率 | 92%+。保持高利用率。 |
| 评估速度 | 30+ token/s,建议使用36b以下型号。 |
与其他显卡的性能对比
GPU物理服务器 - A6000
- CPU: 36核E5-2697v4*2
- 内存: 256GB DDR4
- 系统盘: 240GB SSD
- 数据盘: 2TB NVMe + 8TB SATA
- 系统: Win10/Linux
- 其他: 独立IP,100M-1G带宽
- 独显: Nvidia RTX A6000
- 显存: 48GB GDDR6
- CUDA核心: 10752
- 单精度浮点: 38.71 TFLOPS
总结与建议
NVIDIA RTX 4090 的性能基准展示了其处理大型语言模型(LLM)推理工作负载的卓越能力,尤其是在小型到中型模型上。与 Ollama 配合使用时,这一组合为开发者和企业提供了一个强大且性价比高的解决方案,使其能够在不超出预算的情况下获得高性能。
然而,对于更大型的模型和更高的扩展性需求,可能需要像 NVIDIA A100 这样的 GPU 或多 GPU 配置。尽管如此,对于大多数实际应用场景来说,RTX 4090 托管解决方案在大型语言模型(LLM)基准测试领域仍具有变革性意义。
RTX 4090, Ollama, 大型语言模型, 人工智能基准测试, GPU 性能, NVIDIA GPU, AI 模型托管, 4 位量化, Falcon 40B, LLaMA 2, GPU 服务器, 机器学习, RTX 4090 性能测试, Ollama 性能测试, NVIDIA GPU, 大型语言模型性能, GPU 服务器托管, 4 位量化, Falcon 40B, LLaMA 2 benchmark, AI 模型托管, GPU 服务器性能