
NVIDIA H100 与 A100:终极高性能计算显卡对比
作为 NVIDIA 最新推出的两款数据中心 GPU,A100 和 H100 旨在满足企业和工业的多样化需求,尤其是在 AI 训练、推理和高性能计算(HPC)工作负载方面。那么 H100 在规格、可用性和硬件创新方面提升了多少?它真的是最佳性价比选择吗?在 AI、大规模模型以及高并发任务等实际应用场景中,又会出现哪些差异?本文将为你详细解析。
A100 vs H100 – 背景对比
| 品牌 | 系列 | 型号 | 发布年份 | 官方定位 / 描述 | 市场价格 (美元) |
|---|---|---|---|---|---|
| NVIDIA | A100 | A100 40GB / 80GB | 2020 | 数据中心 GPU,用于 AI 训练和高性能计算(HPC)工作负载 | $11,000+ |
| NVIDIA | H100 | H100 80GB / SXM5 | 2022 | 新一代数据中心 GPU,用于 AI 训练、高性能计算(HPC)和推理 | $25,000+ |
概要亮点
- A100:比 V100 高 20 倍,广泛应用于 AI、机器学习和 HPC 工作负载。
- H100:新一代替代品,在 Transformer 训练上快 6 倍,在最大规模模型的 AI 推理上快 30 倍。
- 核心优势:H100 引入了重大架构升级(Hopper),为大型 AI 模型和高并发任务提供无与伦比的性能。
- 性价比洞察:尽管 H100 在尖端工作负载中占据优势,但 A100 在许多企业场景中仍是一个强大且 高性价比 的选择。
NVIDIA A100 vs H100 – 规格对比
A100 与 H100 核心规格对比
H100 基于 NVIDIA Hopper 架构,引入了第四代 Tensor 核心、Transformer 引擎以及更高的互连带宽,使 AI 训练和推理速度相比 A100 的 Ampere 架构大幅提升。其更大的 GPU 显存和显著更高的内存带宽支持更大模型、更大批量大小和更快的数据传输,减少了 HPC 模拟和大规模深度学习工作负载中的瓶颈。虽然 A100 在许多生产场景中依然是可靠且高性价比的选择,但 H100 为尖端 AI 和高性能计算任务提供了显著的性能和能力提升。
| 参数 | NVIDIA A100 | NVIDIA H100 | 差异 / 优势 |
|---|---|---|---|
| 架构 | Ampere | Hopper | H100 为新一代架构 |
| CUDA 核心 | 6,912 | 16,896 | H100 核心数量约 2.4× |
| 显存类型 | HBM2 (40G A100), HBM2e (80G A100) | HBM3 | H100 使用更快的 HBM3 |
| 显存容量 | 40 GB / 80 GB | 80 GB | H100 标配 80 GB |
| 显存带宽 | ~1.6(40G A100), ~2.0 TB/s (80G A100) | ~3.0 TB/s | H100 带宽更高 |
| 核心频率 (基础/加速) | ~1.41 GHz(视型号而定) | ~1.8 GHz(视型号而定) | H100 通常更高 |
| TDP (总功耗) | 400W (PCIe) / 500W (SXM4) | 350W (PCIe) / 700W (SXM5) | H100 SXM5 支持更高功耗/性能 |
| 接口 / 总线 | PCIe Gen4, NVLink (SXM4) | PCIe Gen5, NVLink (SXM5, 900 GB/s 链路) | H100 支持更新 PCIe & 更快 NVLink |
| FP32 性能 | ~19.5 TFLOPS | ~60 TFLOPS | H100 FP32 性能约 3× |
| Tensor 核心 | 第三代 Tensor 核心 | 第四代 Tensor 核心 + Transformer 引擎 | H100 AI 加速更强 |
| PCIe 版本 | Gen4 | Gen5 | H100 支持新 PCIe 标准 |
高级功能
| 参数 | NVIDIA A100 | NVIDIA H100 | 差异 / 优势 |
|---|---|---|---|
| FP16 / BF16 性能 | ~312 TFLOPS (Tensor 核心) | ~1,000 TFLOPS (Tensor 核心) | H100 FP16/BF16 性能约 3× |
| INT8 / INT4 性能 | ~624 TOPS (INT8 Tensor 运算) | ~2,000 TOPS (INT8) / ~4,000 TOPS (INT4) | H100 推理性能更强 |
| FP64 性能 | ~9.7 TFLOPS | ~30 TFLOPS | H100 FP64 性能约 3× |
| 晶体管数量 | 54.2B | 80B | H100 晶体管数量约 1.5×,密度更高 |
| 功耗 (TDP) | 400–500 W | 700 W | H100 功耗更高 |
| 接口 | PCIe Gen4 / SXM4 | PCIe Gen5 / SXM5 | H100 支持更快 PCIe Gen5 |
| NVLink 带宽 / 版本 | 600 GB/s (NVLink 3, SXM4) | 900 GB/s (NVLink 4, SXM5) | H100 更快互连 |
| Nvlink 互连 | NVLink 3 / SXM4 | NVLink 4 / SXM5 | H100 NVLink 新一代 |
| NVIDIA AI Enterprise | 支持 | 支持 | 两者均支持企业 AI 堆栈 |
| 多实例 GPU (MIG) | 最多 7 个 GPU 实例 | 最多 7 个 GPU 实例(隔离优化) | H100 MIG 隔离和效率更佳 |
| Transformer 引擎支持 | 不支持 | 支持(专用 Tensor 核心) | H100 对大型语言模型有优势 |
| 外形规格 (PCIe / SXM) | PCIe Gen4 / SXM4 (最高 500W) | PCIe Gen5 / SXM5 (最高 700W) | H100 功率更高,支持 Gen5 |
| NVSwitch 兼容性 | 支持 (Ampere NVSwitch) | 支持 (Hopper NVSwitch,更快链路) | H100 NVSwitch 新一代 |
| ECC 内存支持 | 支持 | 支持 | 相同,企业级可靠性 |
| 虚拟化 / vGPU | 支持 | 支持 | 相同,但 H100 针对新 CUDA 堆栈优化 |
总结与分析
NVIDIA H100 在几乎所有核心性能指标上相较 A100 实现了巨大飞跃。
混合精度 AI 训练 (FP16/BF16):
H100 提供约 1,000 TFLOPS,而 A100 为 312 TFLOPS,实现 3 倍以上的深度学习训练速度,尤其在大规模模型训练中效果显著。科学计算 (FP32/FP64):
FP32 性能从 19.5 TFLOPS (A100) 提升至 ~60 TFLOPS,FP64 从 9.7 TFLOPS 提升至 ~30 TFLOPS,使 H100 在 HPC 模拟、气候建模和物理研究中更具优势。推理性能 (INT8/INT4):
支持最高约 4,000 TOPS,H100 提供 4–6 倍更高吞吐量,大幅提升 AI 推理、推荐系统及量化模型部署效率。显存带宽:
H100 的 HBM3 (3 TB/s) 几乎是 A100 HBM2e (1.6 TB/s) 的两倍,减少数据瓶颈,实现 更大批量和更快数据传输,对 基础模型训练和大规模数据集处理至关重要。架构创新:
- 第四代 Tensor 核心 支持 FP8 和 BF16,减少显存占用同时保持精度,显著提高大模型训练效率。
- Transformer 引擎 专为 GPT 等大型语言模型设计,实现 Transformer 训练速度提升至 6 倍。
- DPX 加速 为动态规划任务提供独特能力(如 DNA/RNA 测序、优化问题)。
- 增强 MIG 保持 7 分区但隔离性和 QoS 更优,使 H100 更适合 多租户和云规模部署。在 MIG 场景下推理速度 比 A100 快 1.5–2 倍。
- 高速互连(PCIe Gen5 + NVLink 900 GB/s)支持 扩展至百亿级 GPU 集群,效率高于 A100 的 Gen4/NVLink 600 GB/s。
核心结论
虽然 A100 仍是 AI 训练和 HPC 工作负载的强大且高性价比选项,但 H100 重新定义了数据中心 GPU 性能。凭借 Transformer 训练性能提升 6 倍、FP32/FP64 性能提升 3 倍、显存带宽翻倍,H100 是为下一代 AI、高性能计算和大规模推理设计的 量子飞跃,是企业部署 大型语言模型、生成式 AI 及多租户云环境的优选。
H100 vs A100 AI 基准测试
H100 和 A100 都针对高计算工作负载设计,如 AI、HPC 和高级接口任务。随着模型规模和数据量的增加,两款 GPU 在 AI 推理中的性能差距愈发明显。
H100 与 A100 的 AI 接口性能
根据 NVIDIA 官方数据,在特定优化测试场景中,例如在 5300 亿参数模型上使用 H100 的下一代高速互连进行短问推理,H100 在 AI 推理吞吐量上可比 A100 提高 16–30 倍。
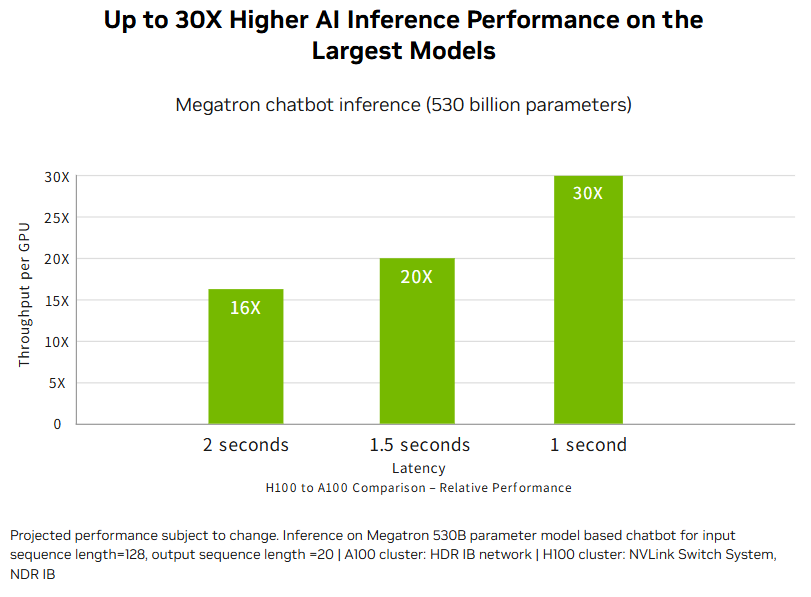
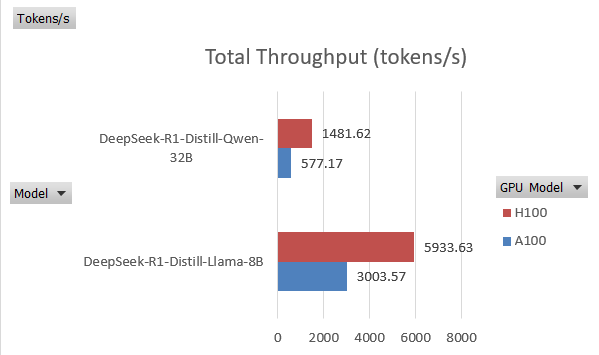
然而,在测试 DeepSeek-R1-Distill-Qwen-32B 时,总吞吐量为:
- A100: ~577.17 tokens/sec (点击这里查看 A100 的不同测试)
- H100: ~1,481.62 tokens/sec (点击这里查看 H100 的不同测试)
这意味着性能提升不到 3 倍。对于较小模型,性能差距进一步缩小,表明 H100 的优势在很大程度上依赖于模型规模和工作负载特性。
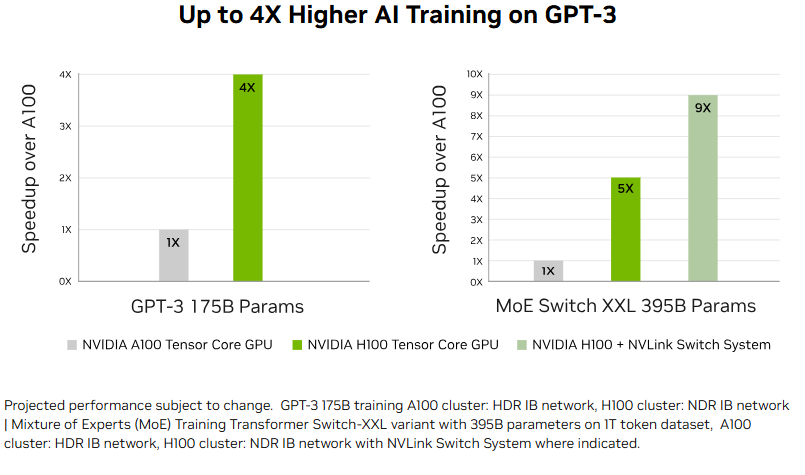
A100 与 H100 AI 训练
在某些大规模 AI 训练任务中,特别是配合第四代 NVLink 使用时,A100 与 H100 之间的性能差距可达到 4–7 倍。在数据中心规模下,H100 GPU 明显优于 A100,展示了其在高性能、大模型部署中的卓越性能。
H100 vs A100: 价格与价值
作为价格在数万美元的企业级 GPU,A100 和 H100 的价格在不同平台上差异明显,取决于二手与全新、显存容量和市场库存等因素,差距可达 2× 到 10×。显然,二手 A100 提供了最佳性价比,对于小至中型模型(参数量低于 700 亿)来说,A100 可能是更具成本效益的选择。
| Platform | NVIDIA A100 (USD) | NVIDIA H100 (USD) | Price Difference (USD) | Price Difference (%) |
|---|---|---|---|---|
| 官方建议零售价 (MSRP) | $11,000 | $30,000 | +$19,000 | +173% |
| Amazon | $7,500–$14,000 | $25,000–$30,000 | +$17,500–$22,500 | +233–300% |
| 第三方经销商(ebay 等) | $2,500–$17,200 | $27,000–$31,000 | +$24,500–$28,500 | +1,000–1,140% |
H100 vs A100 – 优缺点
| GPU 型号 | 优点 | 缺点 |
|---|---|---|
| NVIDIA A100 | - AI/HPC 应用成熟可靠 - 成本较低,尤其是二手 - 支持 7 路 MIG - 软件与生态系统支持广泛 - 驱动和库支持稳定 - 中型模型(<70B 参数)高效 - 相比 H100 功耗较低 |
- FP16/BF16 训练较慢 - FP32/FP64 吞吐量较低 - HBM2e 显存带宽有限 - 架构较老 - 对 LLMs 的未来适应性有限 - 推理吞吐量较低 |
| NVIDIA H100 | - FP16/BF16 吞吐量巨大 - FP32/FP64 性能高 - HBM3 显存带宽约 3 TB/s - 第四代 Tensor 核心,支持 FP8 - Transformer 引擎支持 LLMs - DPX 加速器支持动态规划 - MIG 隔离与 QoS 增强 - PCIe Gen5 + NVLink 900 GB/s - 可扩展至云端及多 GPU 集群 |
- 价格极高(为 A100 的 2–10 倍) - 对小/中型模型过剩 - 功耗更高 - 初期软件优化可能滞后 - 某些地区供应有限 |
结论
NVIDIA H100 在 AI 和 HPC 领域实现了重大飞跃,在大规模 AI 训练、推理和集群部署中,其性能比 A100 提升了 2–30 倍。虽然价格高出 2–3 倍,但对于中型模型来说,差距要小得多,A100 仍然是高性价比的选择——尤其是二手卡。最终,最佳选择取决于工作负载规模和预算,两款 GPU 都为企业 AI 项目提供了强大的价值。
h100 vs a100, a100 vs h100, nvidia a100 vs h100, nvidia h100 vs a100, H100 用于 AI, H100 价格, H100 参数, A100 价格, A100 参数, 用A100运行AI