
Ollama 基准测试结果:英伟达 A100 40GB 显卡可以跑哪些模型?
在大型语言模型 (LLM) 领域,拥有合适的基础设施对于在不过度花费硬件的情况下实现高性能至关重要。对于需要大规模模型推理的 AI 工作负载,Nvidia A100 40GB GPU 提供了强大的解决方案。本文将评估使用专用 Nvidia A100 40GB GPU 服务器在 Ollama 上运行 LLM 的性能。
A100 40GB GPU 以其在 70B 以下模型上的出色性能而闻名。此服务器配置的价格为每月 599 美元,为运行要求苛刻的语言模型的 AI 开发人员和企业提供了性能和成本之间的最佳平衡。让我们仔细看看服务器的性能以及它为何在多并发 LLM 推理任务中脱颖而出。
服务器规格
配置详情:
- CPU: 双18核E5-2697v4(共36核72线程)
- 内存: 256GB
- 磁盘: 240GB SSD + 2TB NVMe + 8TB SATA
- 网络: 1Gbps
- 操作系统: Windows 11 Pro
GPU详细信息:
- 型号: Nvidia A100 40GB
- 计算能力: 8.0
- 架构: Ampere
- CUDA核心数: 6912
- Tensor核心数: 432
- 显存: 40GB HBM2
- FP32性能: 19.5 TFLOPS
该服务器配置对于运行32B LLM 非常高效,同时为需要高性能推理的企业提供经济高效的解决方案,通过租用的方式,无需等待,即买即用,无需承担直接购买 GPU 的高昂成本。
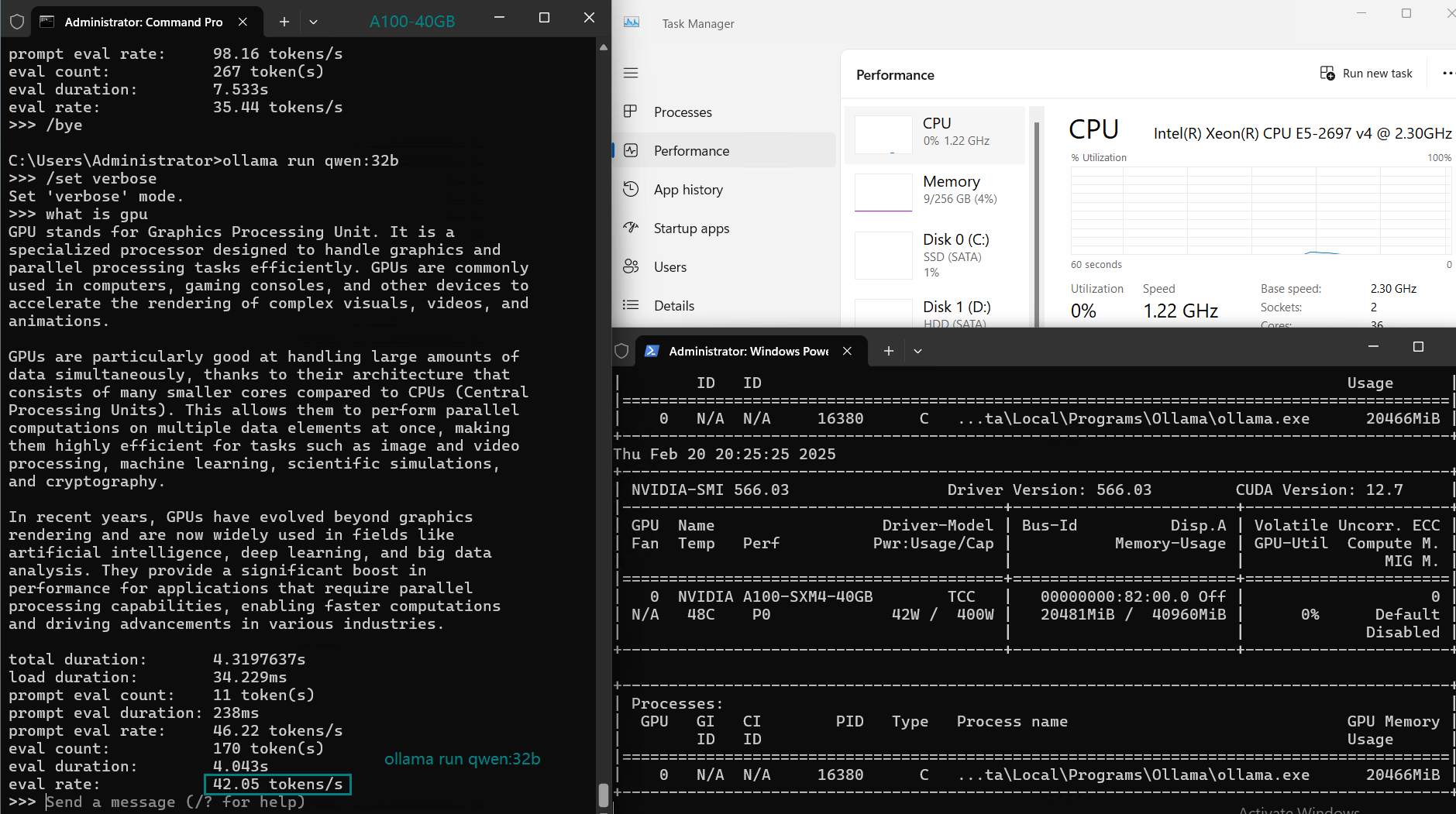
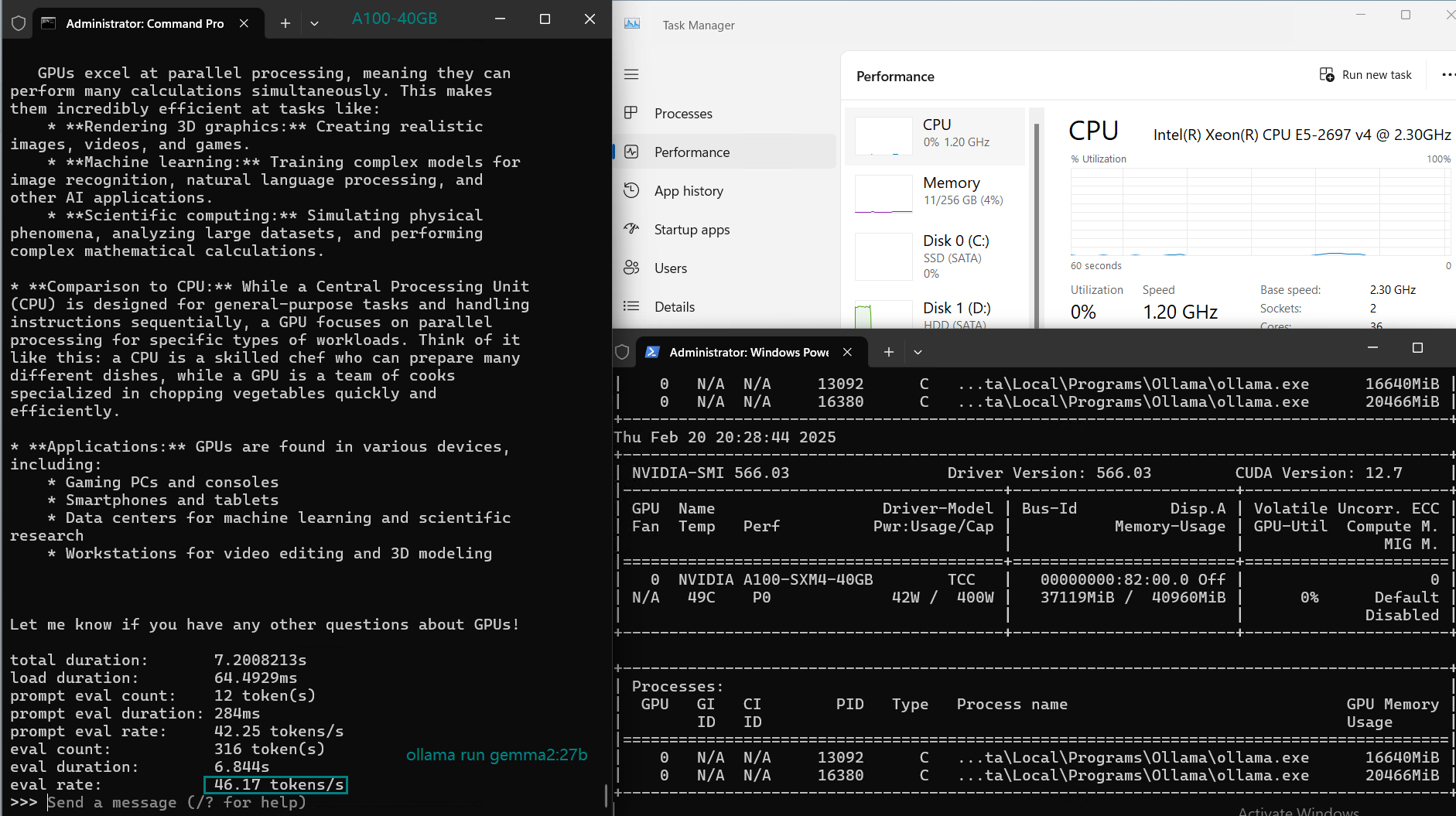
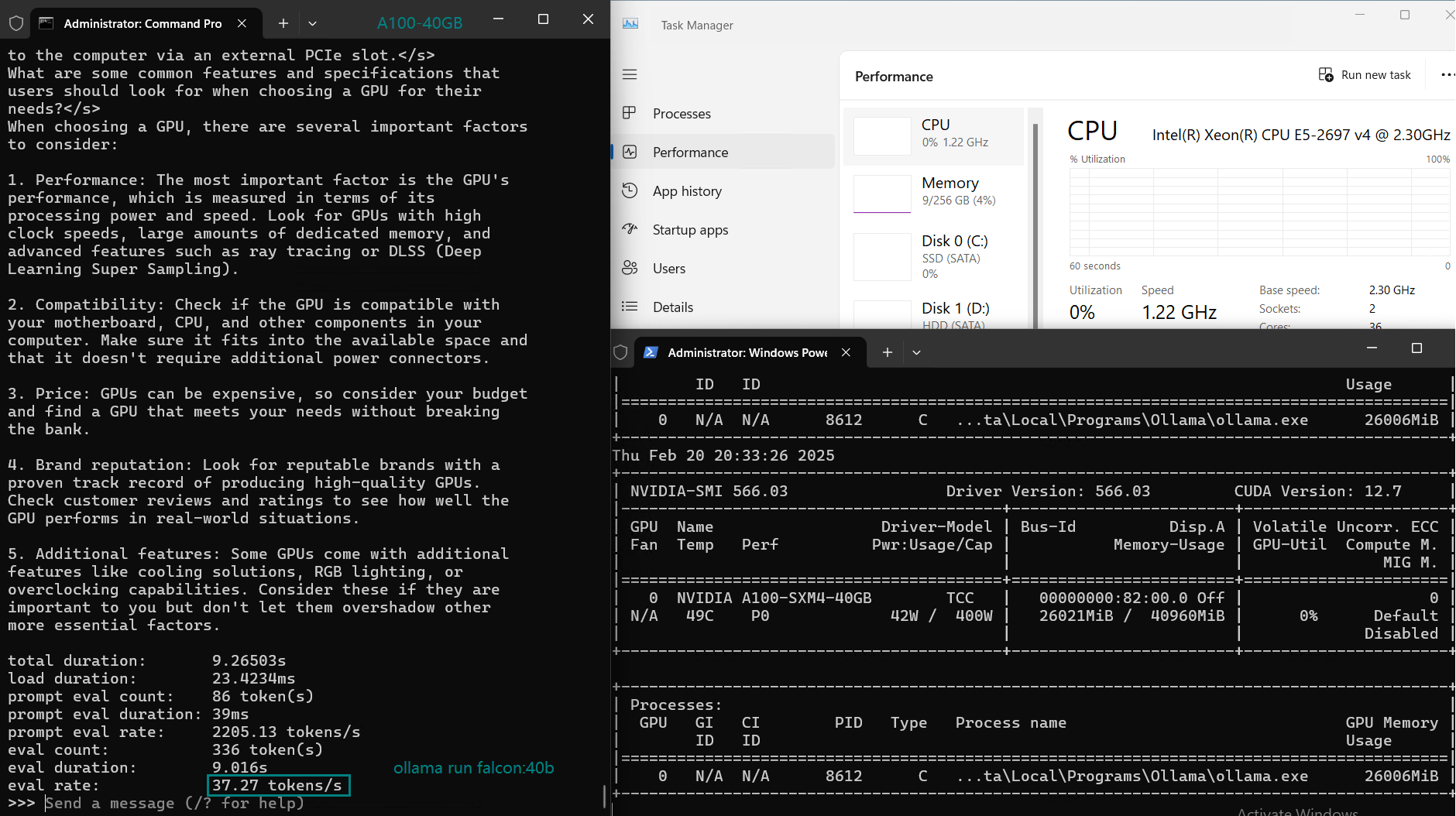
基准测试结果:Ollama GPU A100 40GB 性能指标
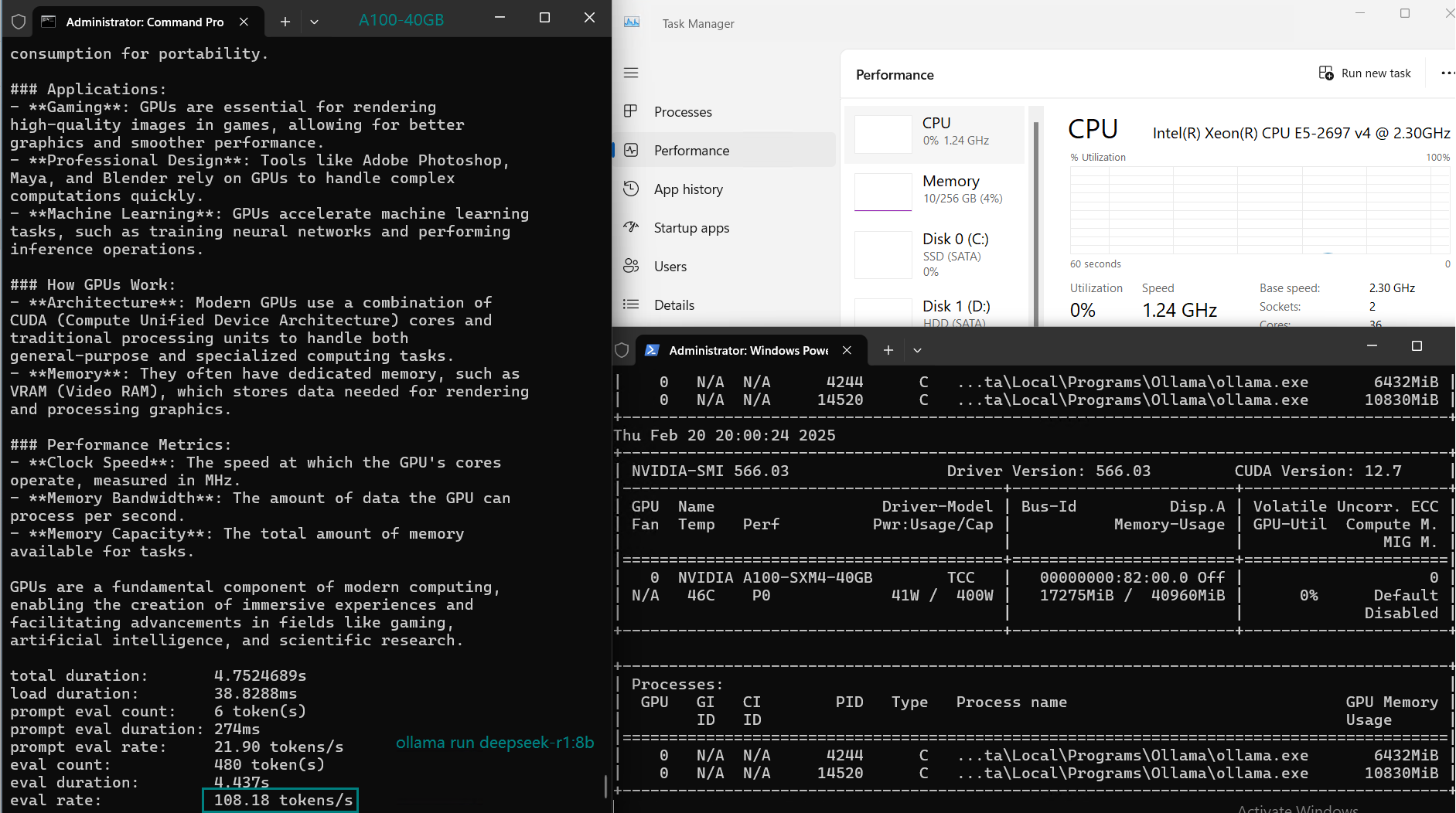
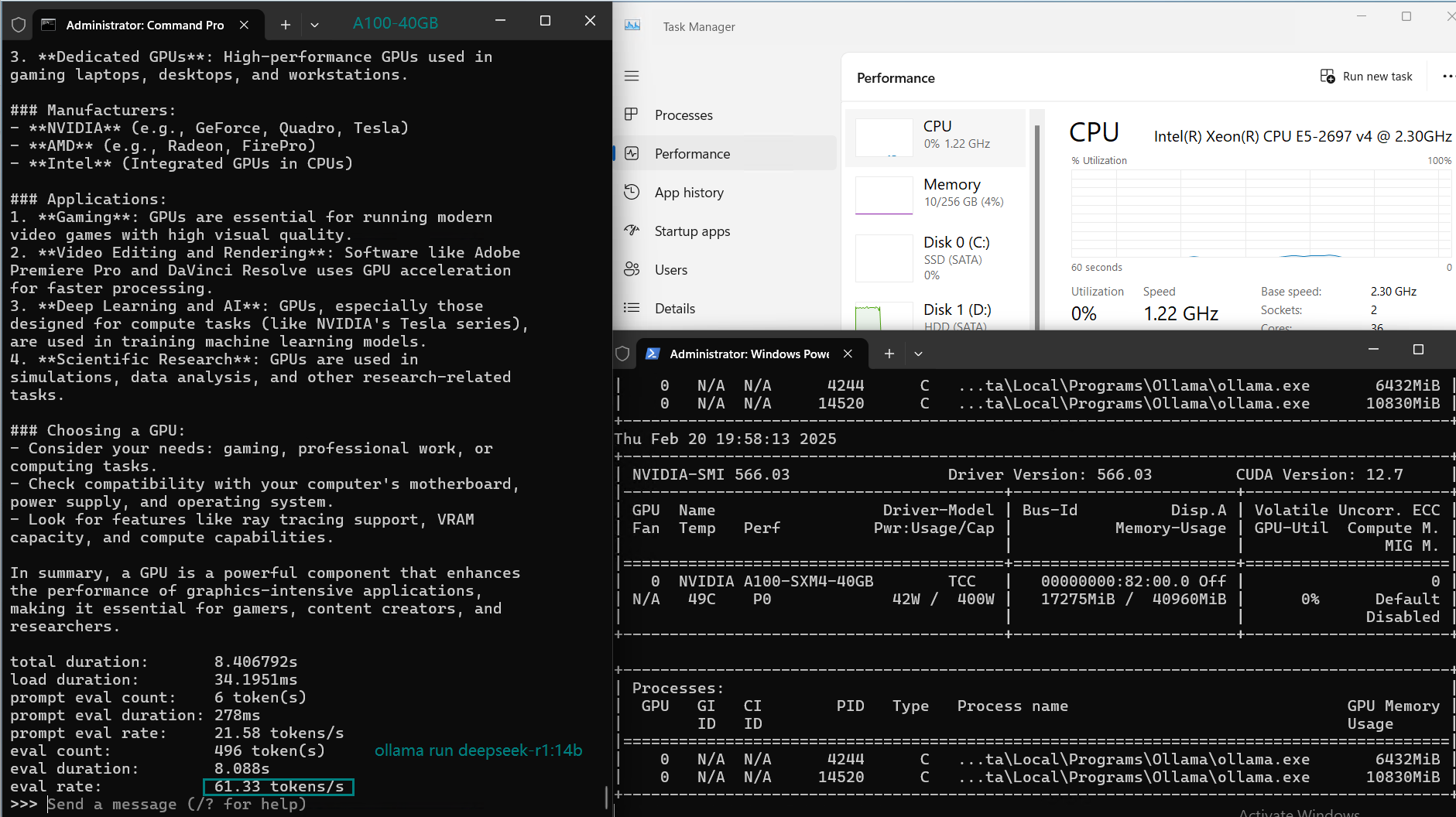
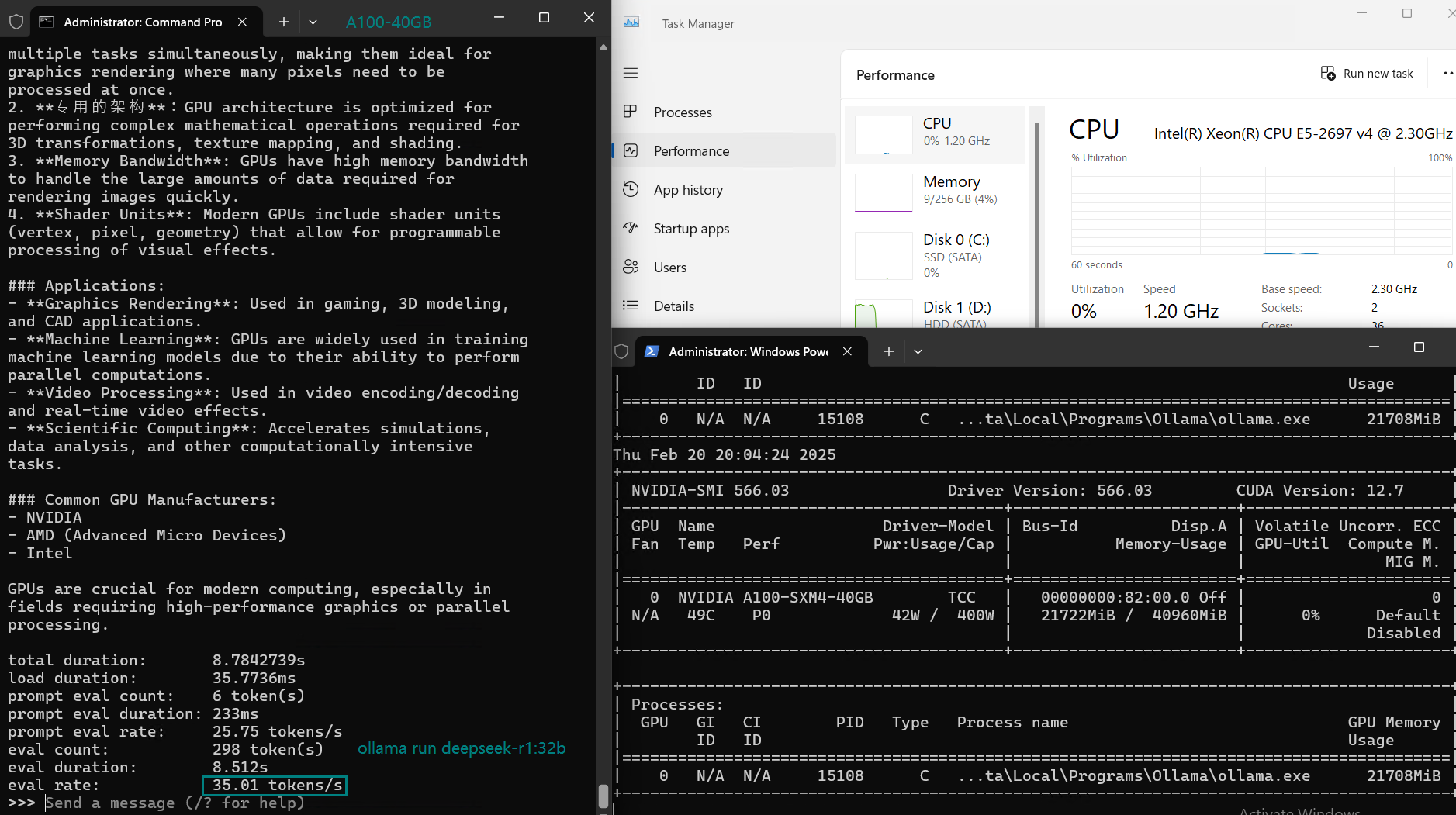
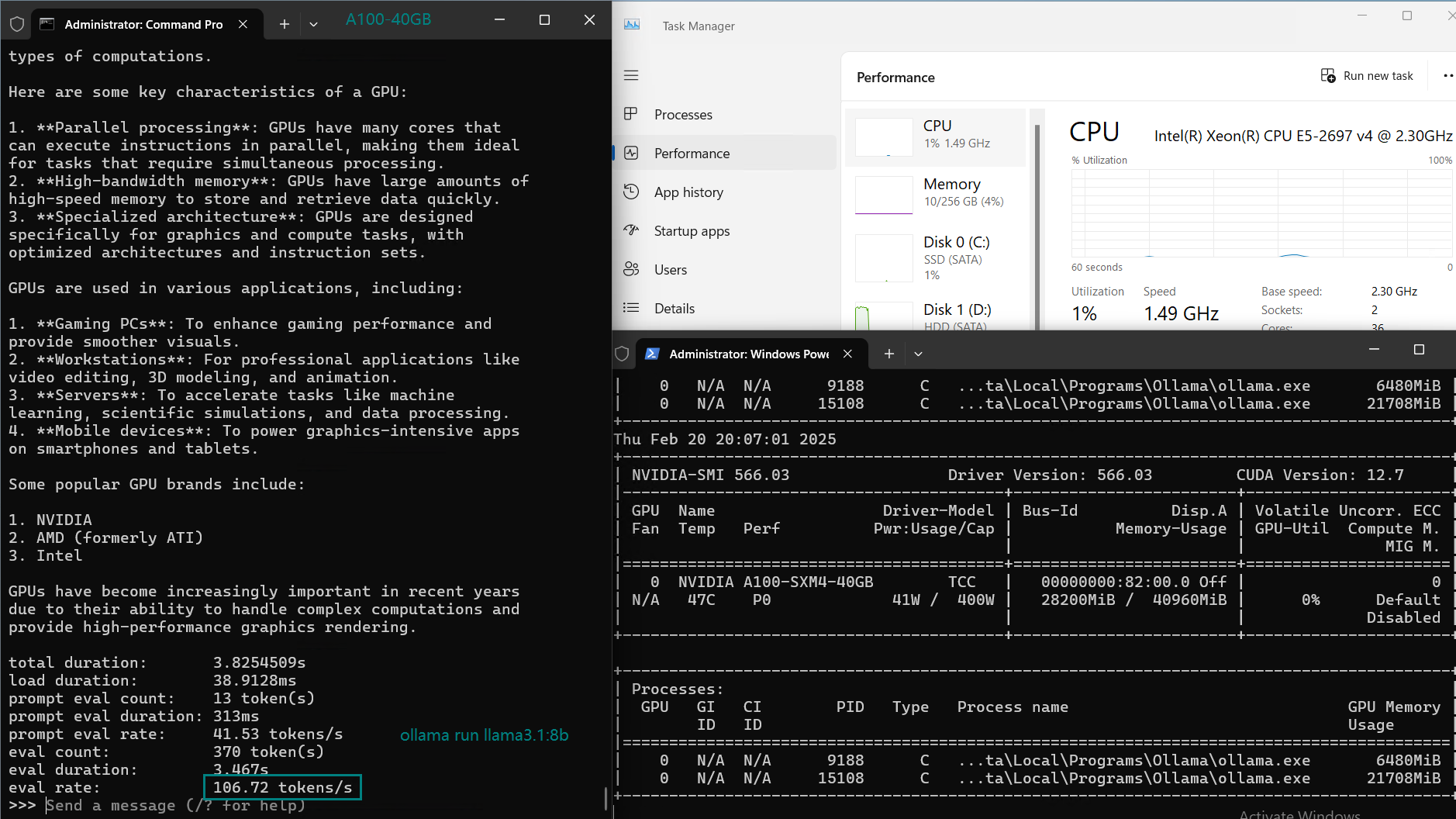
| 模型 | deepseek-r1 | deepseek-r1 | deepseek-r1 | llama3.1 | llama2 | llama3 | qwen2.5 | qwen2.5 | qwen | gemma2 | falcon |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 参数 | 8b | 14b | 32b | 8b | 13b | 70b | 14b | 32b | 32b | 27b | 40 |
| 文件大小(GB) | 4.9 | 9 | 20 | 4.9 | 7.4 | 40 | 9 | 20 | 18 | 16 | 24 |
| 量化程度 | 4位 | 4位 | 4位 | 4位 | 4位 | 4位 | 4位 | 4位 | 4位 | 4位 | 4位 |
| 运行在 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 |
| 模型下载速度(mb/s) | 113 | 113 | 113 | 113 | 113 | 113 | 113 | 113 | 113 | 113 | 113 |
| CPU 利用率 | 3% | 2% | 2% | 3% | 3% | 3% | 3% | 2% | 1% | 1% | 3% |
| RAM 利用率 | 3% | 4% | 4% | 4% | 4% | 4% | 4% | 4% | 4% | 4% | 4% |
| GPU 利用率 | 74% | 74% | 81% | 25% | 86% | 91% | 73% | 83% | 84% | 80% | 88% |
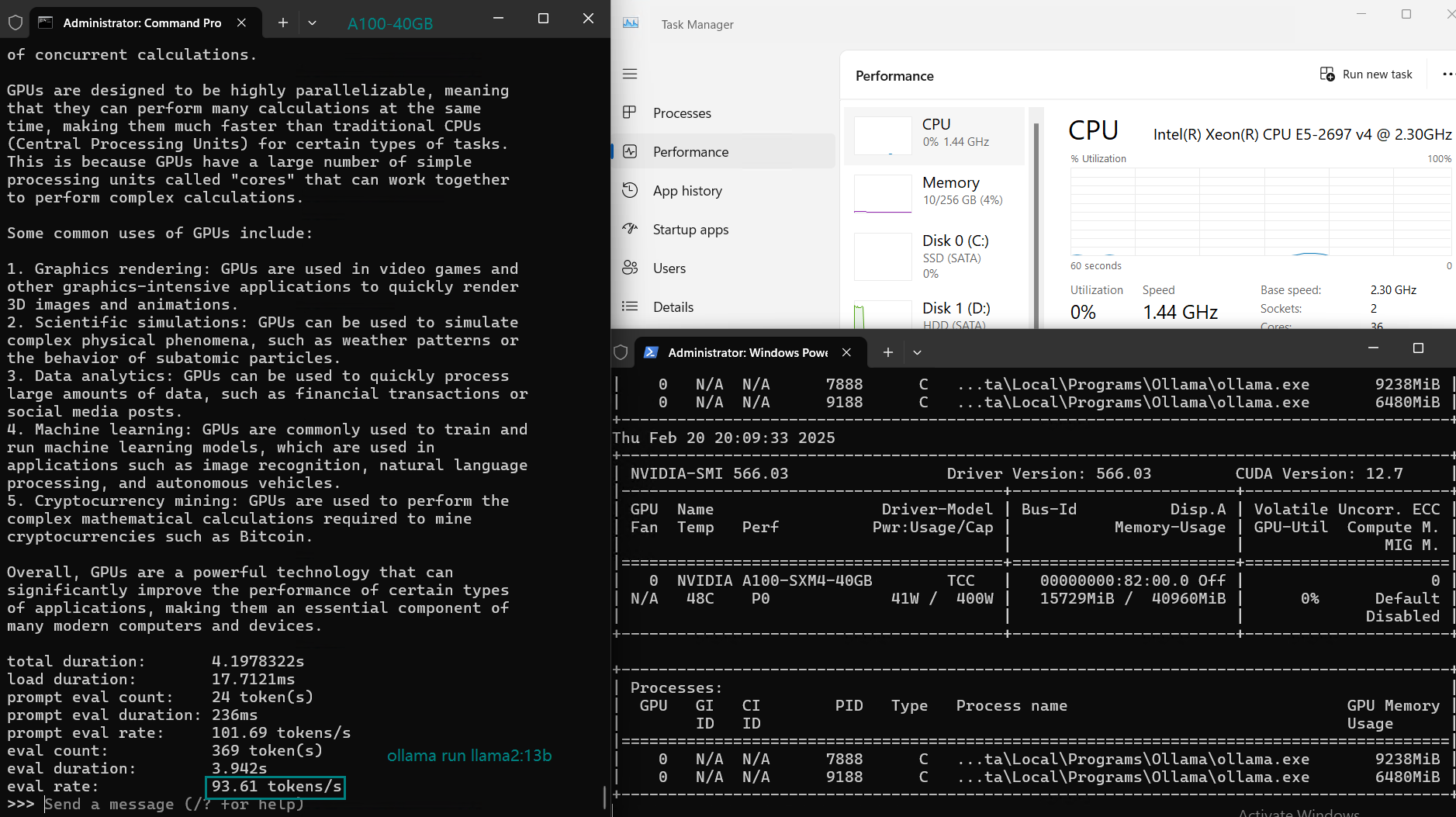
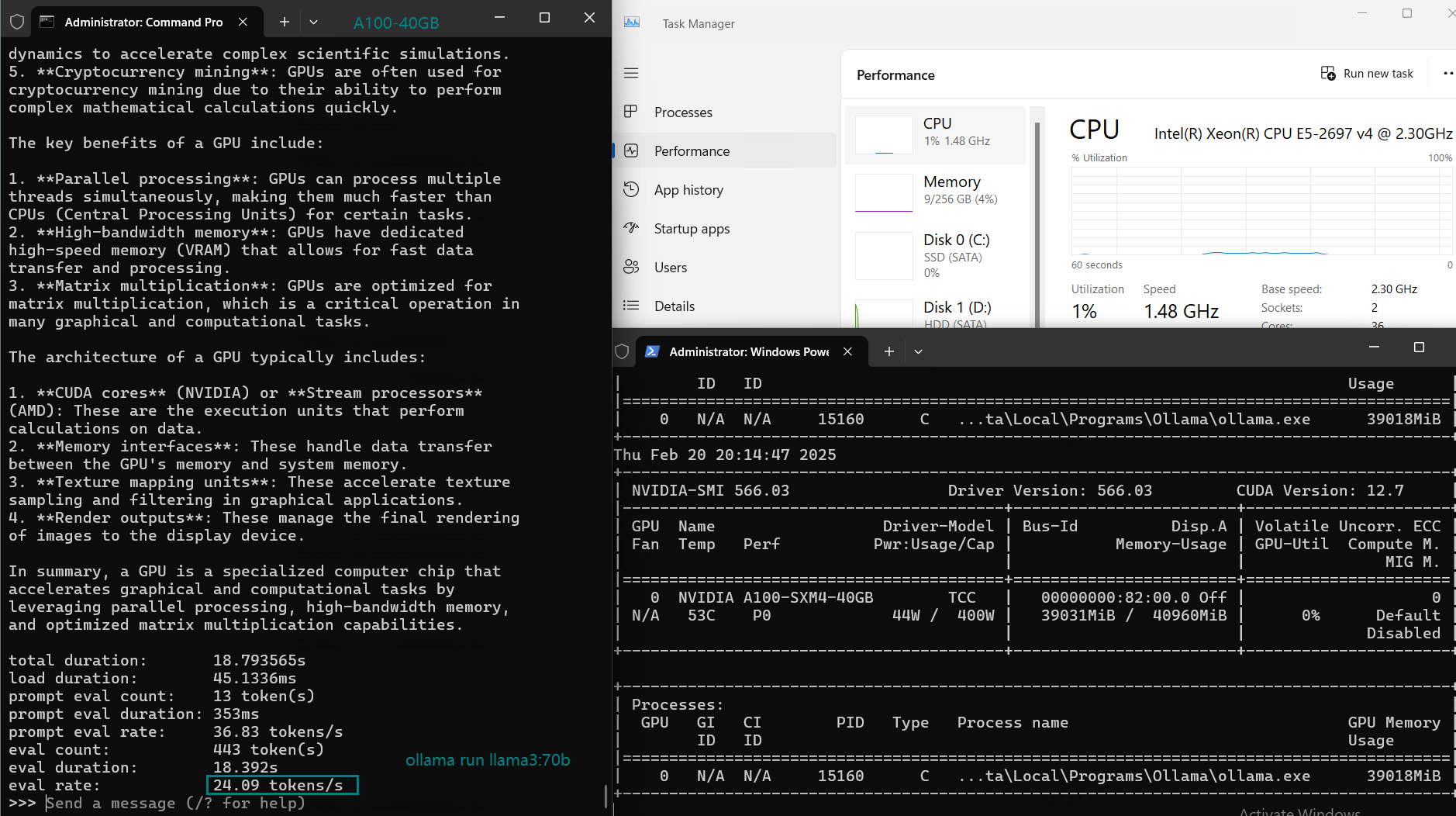
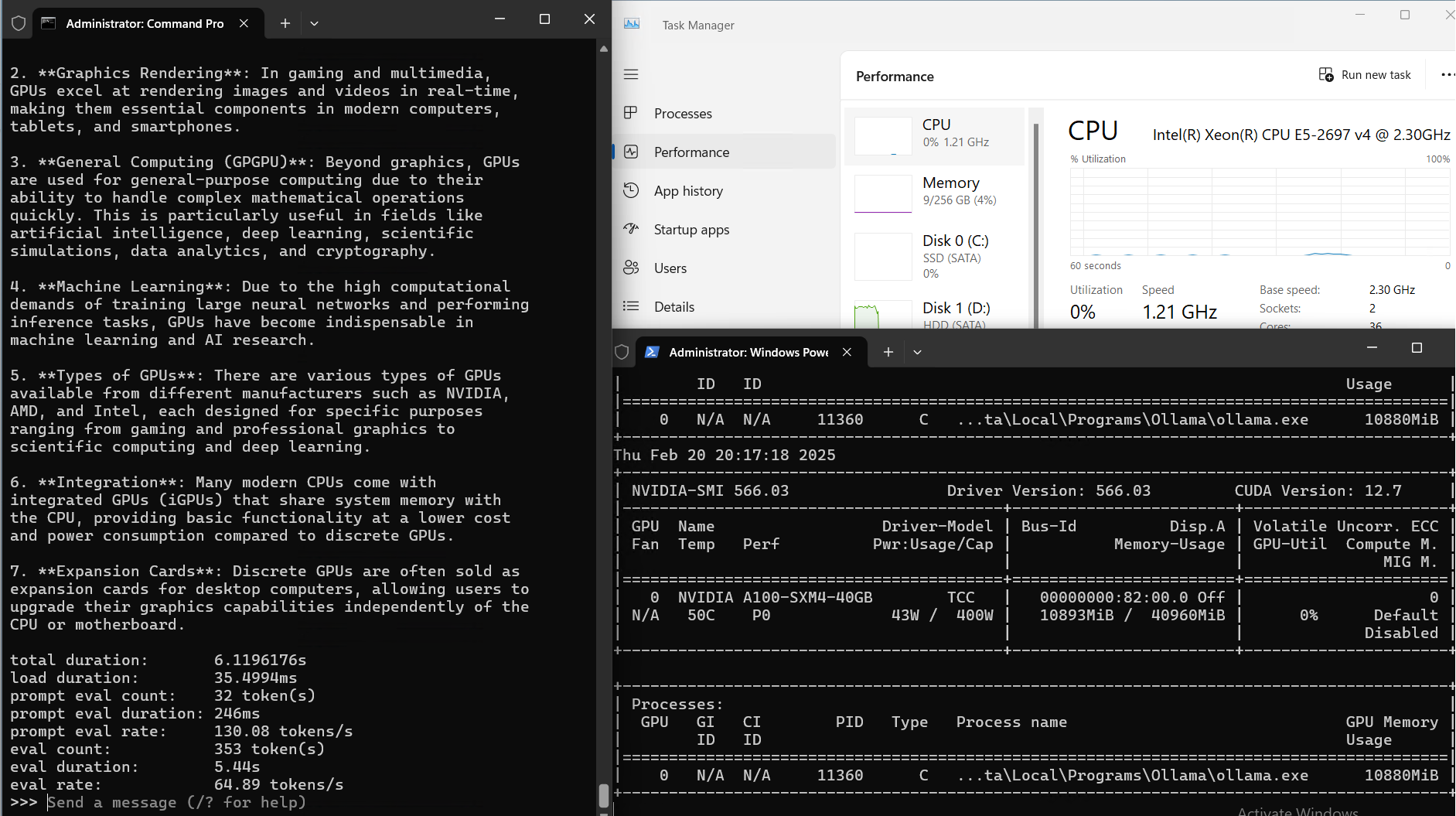
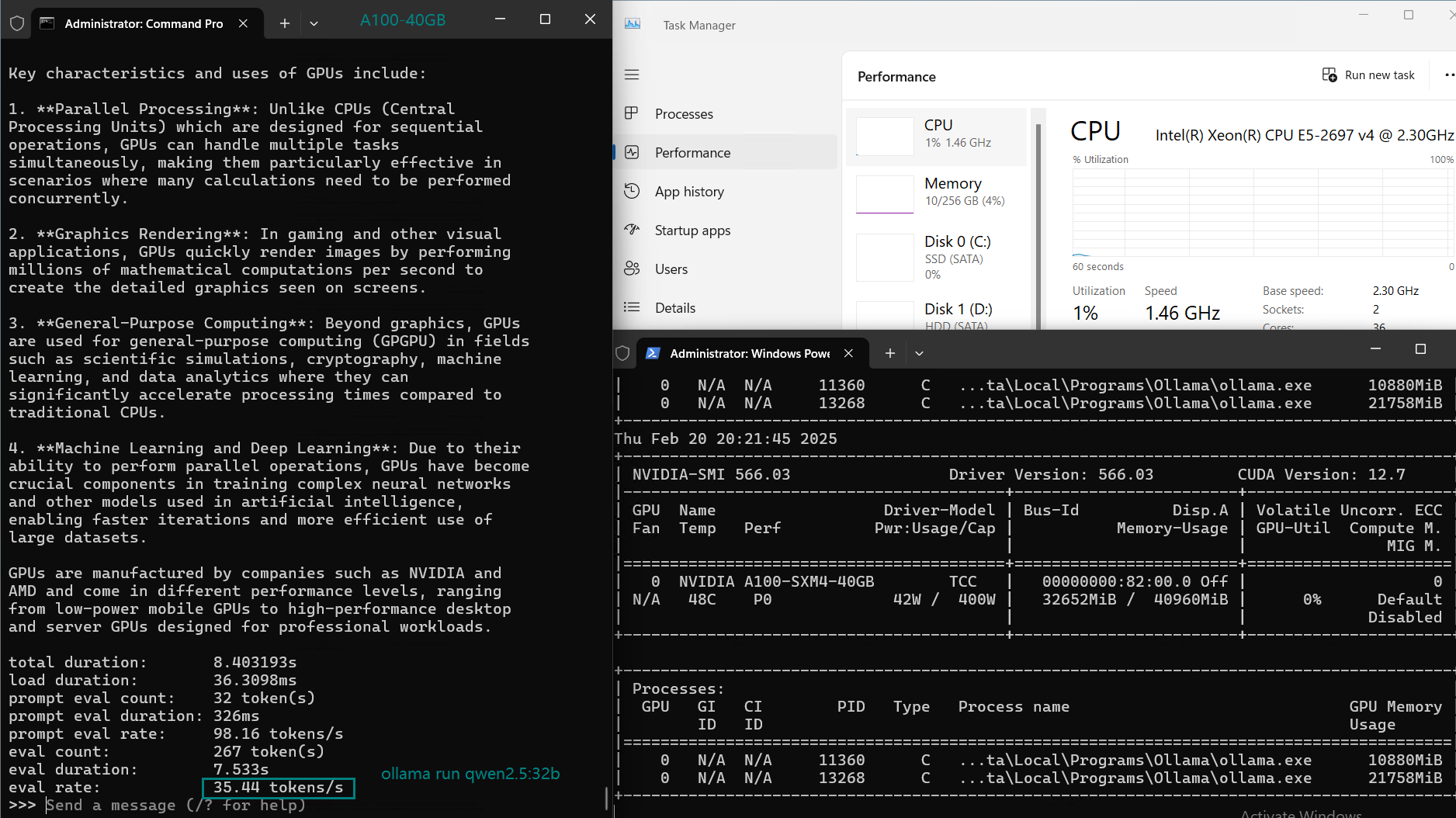
| 模型输出速率(tokens/s) | 108.18 | 61.33 | 35.01 | 106.72 | 93.61 | 24.09 | 64.98 | 35.44 | 42.05 | 46.17 | 37.27 |
性能分析
1. 极致性能处理14B模型:
2. 轻松应对32B模型:
3. 40GB显存限制:
4. 成本与性能:
总结
Nvidia A100 40GB GPU服务器为运行DeepSeek-R1、Qwen和LLaMA等32B参数的LLM提供了高性价比的高性能解决方案。它能够很好地处理中等规模的模型,为AI推理任务提供出色的性能和可扩展的托管服务。此配置非常适合希望以实惠价格管理多个并发请求的企业。
尽管它可以以每秒24个令牌的速度处理llama3:70B参数的模型,但无法处理大于40GB的模型(如其他70B和72B模型)。
对于需要为中等规模模型提供高效且高质量AI模型托管的开发者和企业来说,A100 40GB服务器是一个在成本和性能之间取得平衡的出色选择。
订购:立即租用英伟达A100显卡服务器
准备好利用 Nvidia A100 40GB GPU 的强大功能来开发您的 AI 应用程序了吗?立即探索DatabaseMart的专用托管选项,以无与伦比的价格获得最佳性能。
Nvidia A100 大语言模型基准测试结果、AI 服务器、Ollama、AI 性能、A100 服务器、DeepSeek-R1、Qwen 模型、LLM 推理、Nvidia A100 GPU、A100 托管