
在NVIDIA A4000 GPU VPS上对Ollama LLMs进行基准测试
随着大型语言模型(LLMs)的不断发展,在GPU优化的虚拟专用服务器(VPS)上高效运行它们已成为AI开发者和企业关注的关键因素。在本次基准测试中,我们评估了多种LLM在Ollama上的性能,使用NVIDIA A4000 GPU VPS进行测试。本测试旨在帮助用户确定最佳的AI推理模型,并对比评估速度、GPU利用率及整体系统性能等关键指标。
美国服务器配置
服务器配置:
- 价格:179美元/月
- CPU:24 核
- 内存:32GB
- 存储:320GB SSD
- 网络:300Mbps 无流量限制
- 操作系统:Windows 11 Pro
- 备份:每两周一次
GPU详细信息:
- GPU: NVIDIA Quadro RTX A4000
- 计算能力:8.6
- 微架构:Ampere
- CUDA 核心数:6144
- 张量核心:192
- 内存:16GB GDDR6
- FP32 性能:19.2 TFLOPS
此配置可确保 AI 推理工作负载的最佳性能,使其成为 Ollama VPS 托管和 LLM 推理任务的可靠选择。
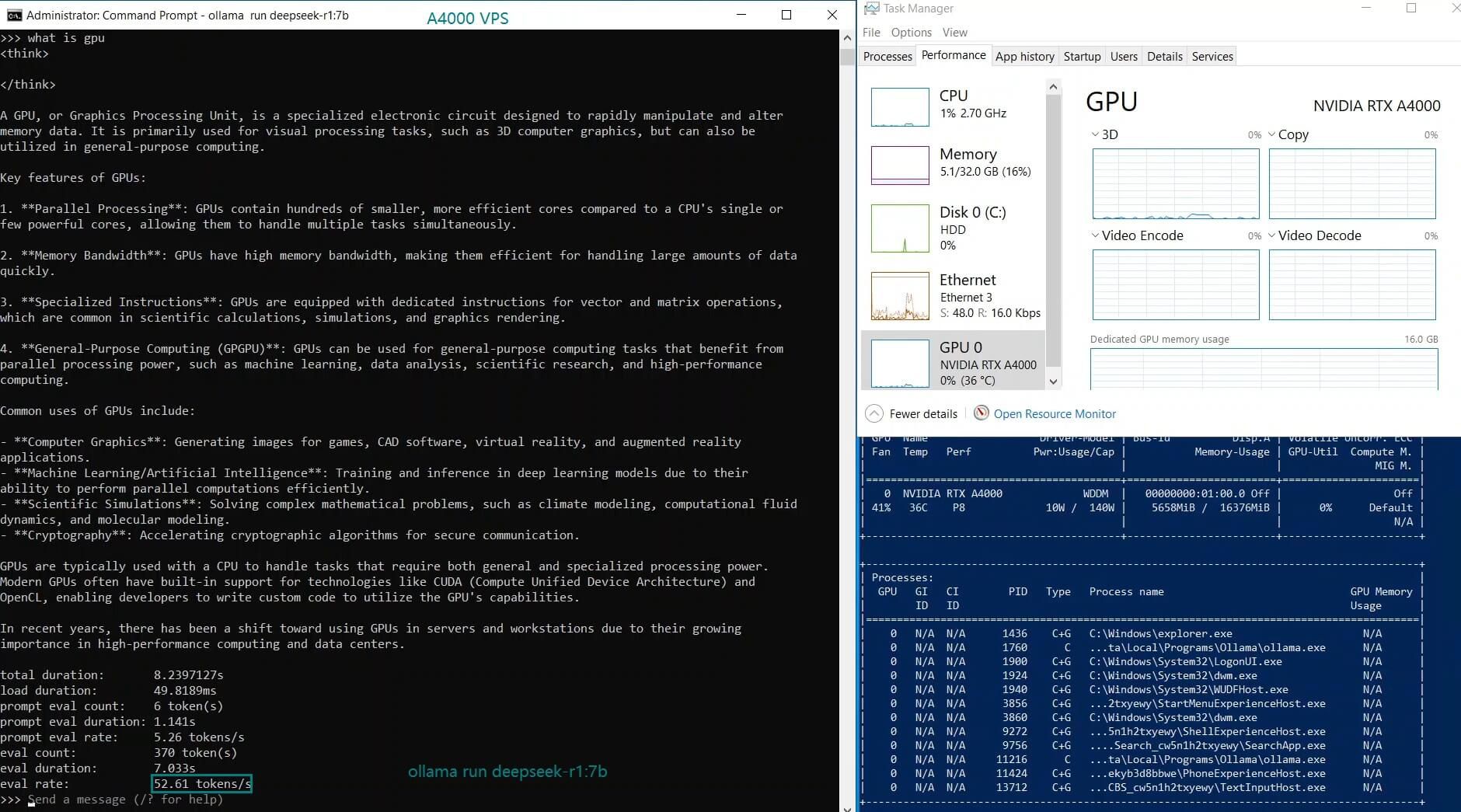
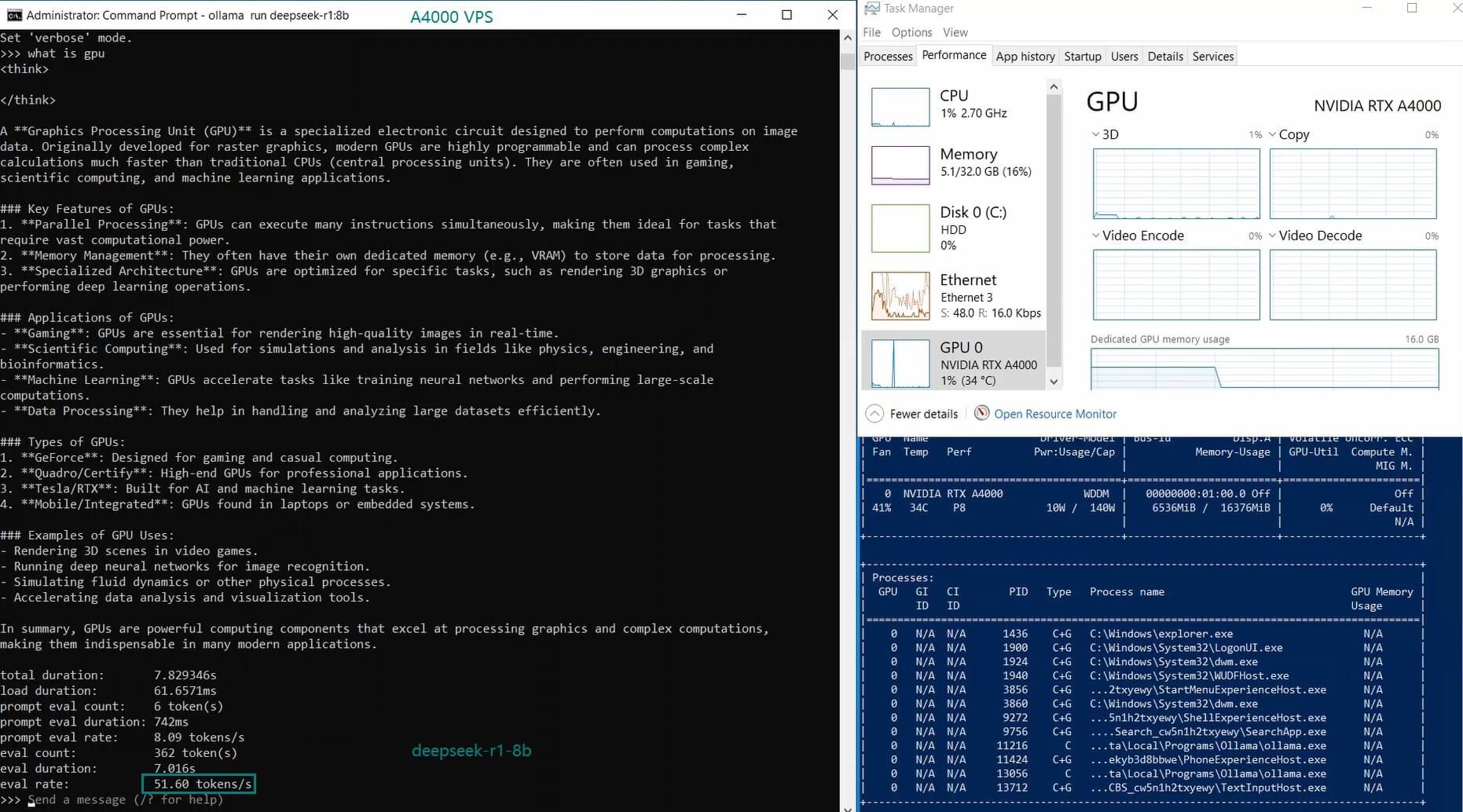
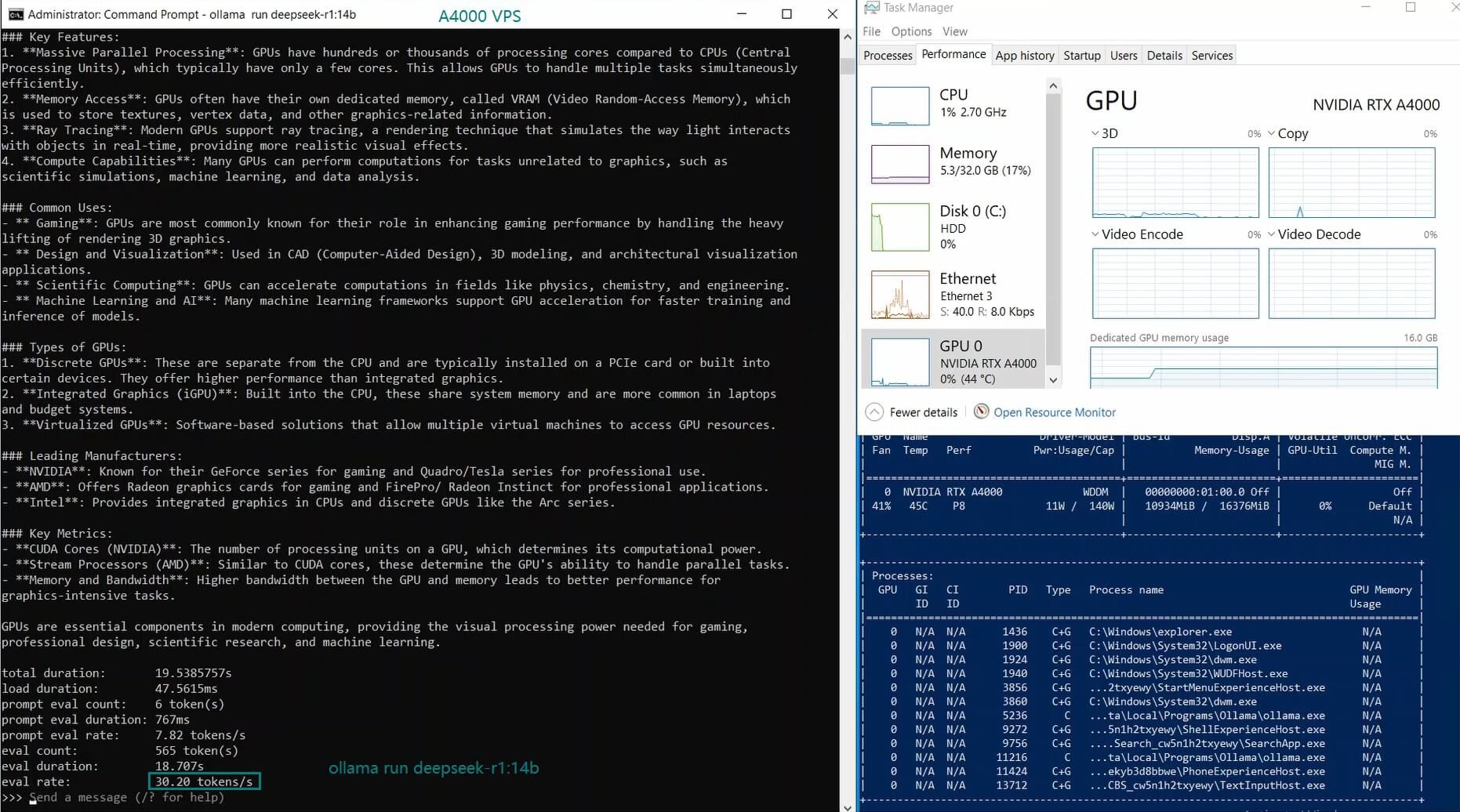
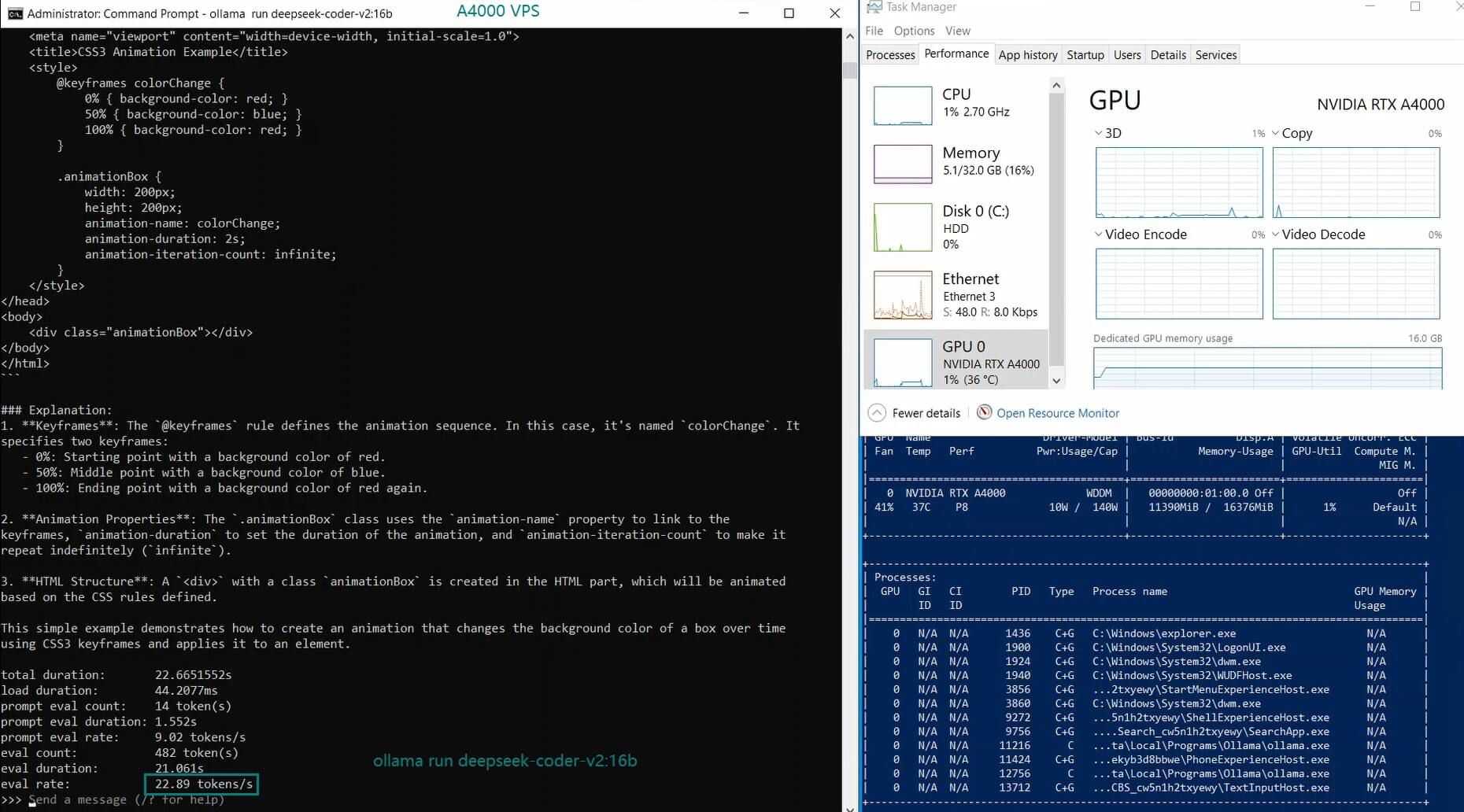
Ollama 基准测试:在 NVIDIA A4000 VPS 上推理 LLM
| 模型 | deepseek-r1 | deepseek-r1 | deepseek-r1 | deepseek-coder-v2 | llama2 | llama2 | llama3.1 | mistral | gemma2 | gemma2 | qwen2.5 | qwen2.5 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 参数 | 7b | 8b | 14b | 16b | 7b | 13b | 8b | 7b | 9b | 27b | 7b | 14b |
| 大小(GB) | 4.7 | 4.9 | 9 | 8.9 | 3.8 | 7.4 | 4.9 | 4.1 | 5.4 | 16 | 4.7 | 9.0 |
| 量化 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| 运行平台 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 |
| 下载速度(mb/s) | 36 | 36 | 36 | 36 | 36 | 36 | 36 | 36 | 36 | 36 | 36 | 36 |
| CPU 使用率 | 8% | 7% | 8% | 8% | 8% | 8% | 8% | 8% | 7% | 70-86% | 8% | 7% |
| RAM 使用率 | 16% | 18% | 17% | 16% | 15% | 15% | 15% | 18% | 19% | 21% | 16% | 17% |
| GPU 使用率 | 77% | 78% | 83% | 40% | 82% | 89% | 78% | 81% | 73% | 1% | 12% | 80% |
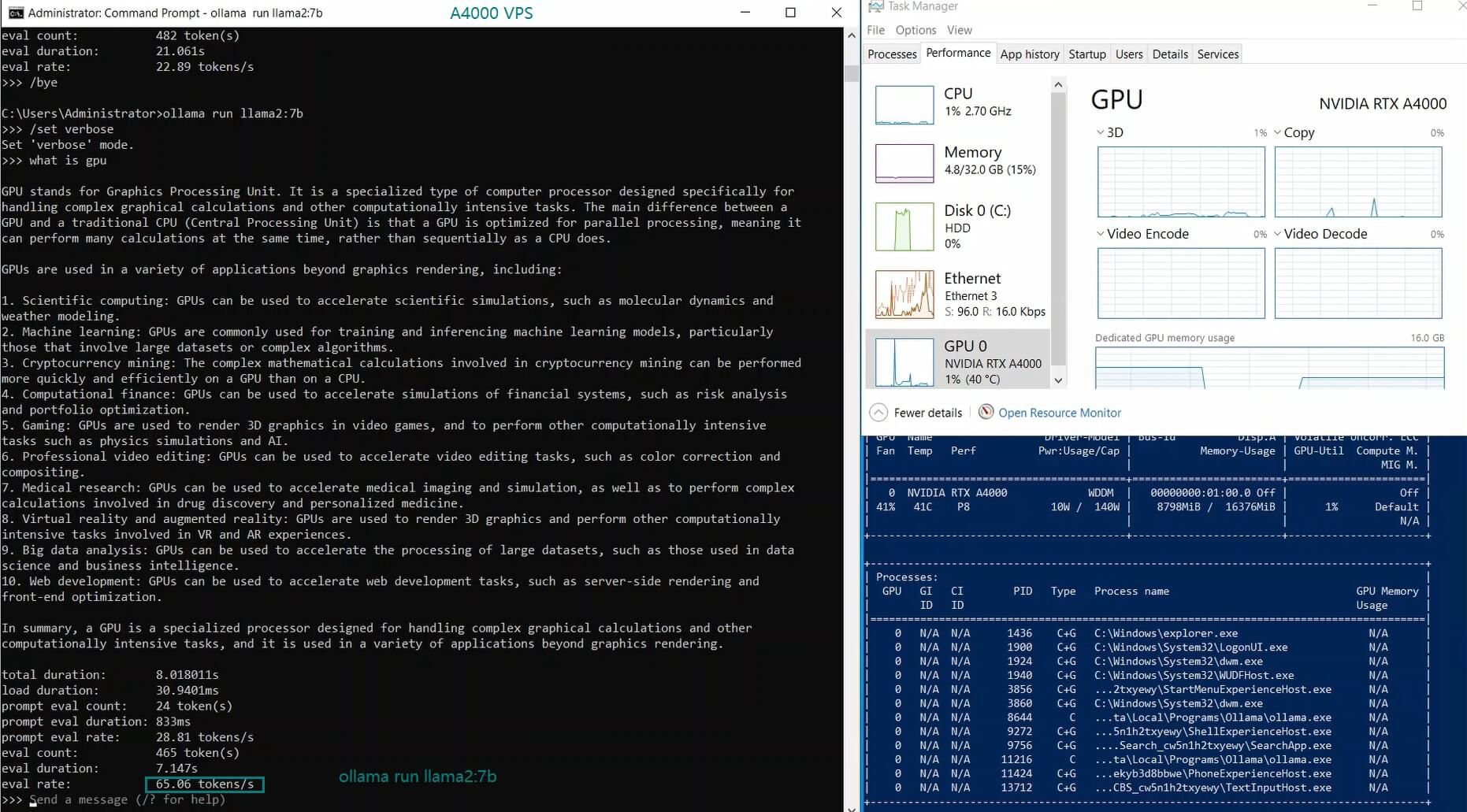
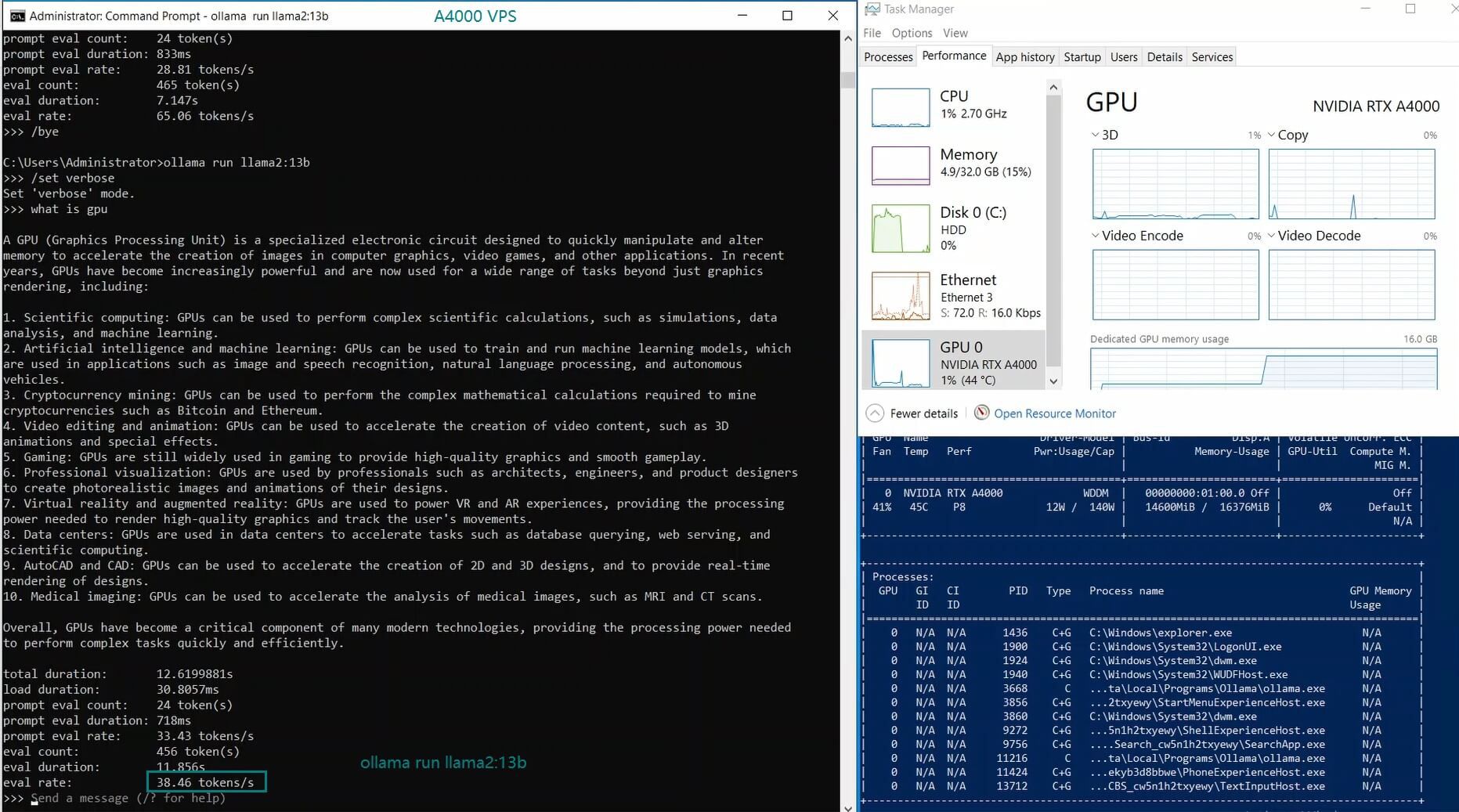
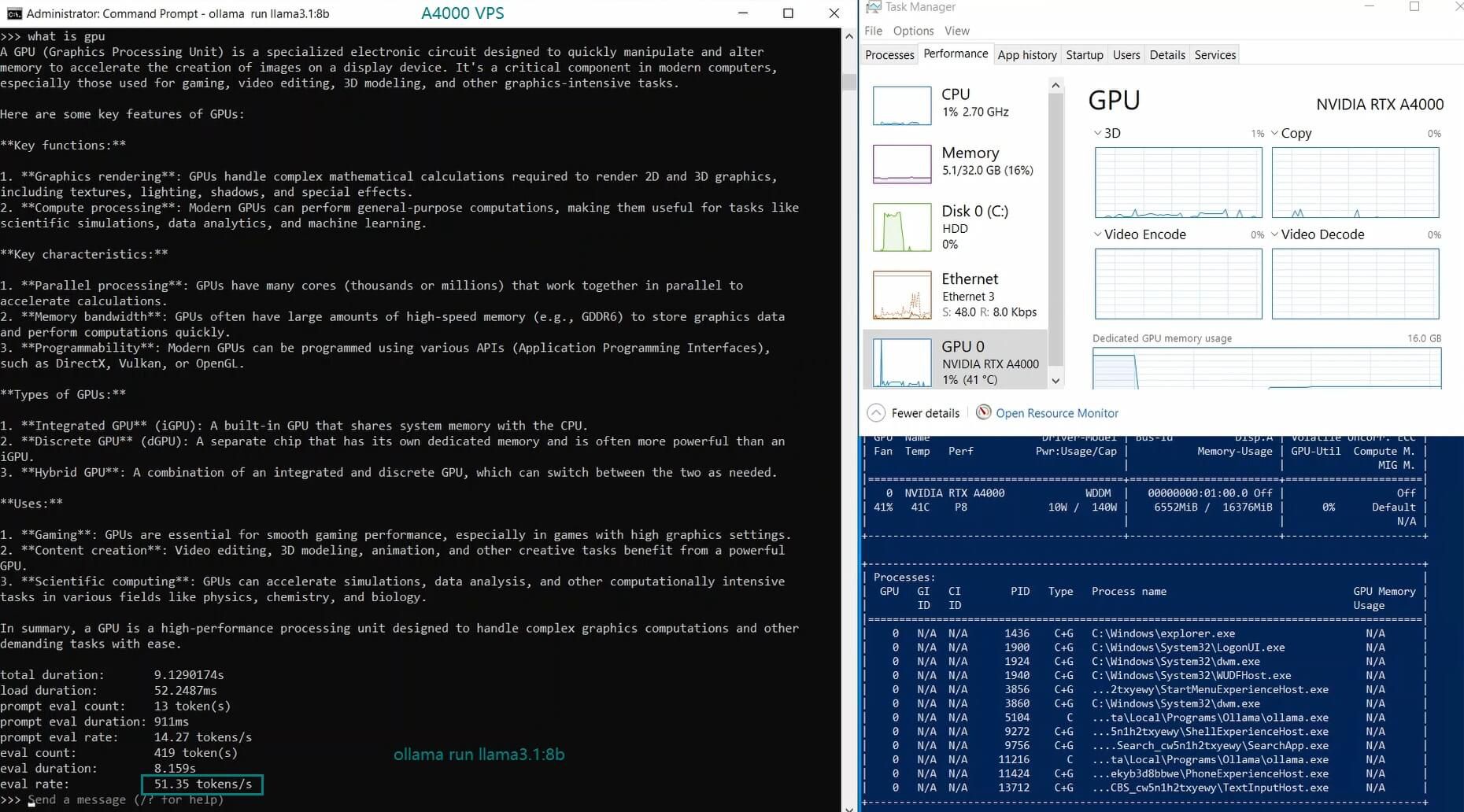
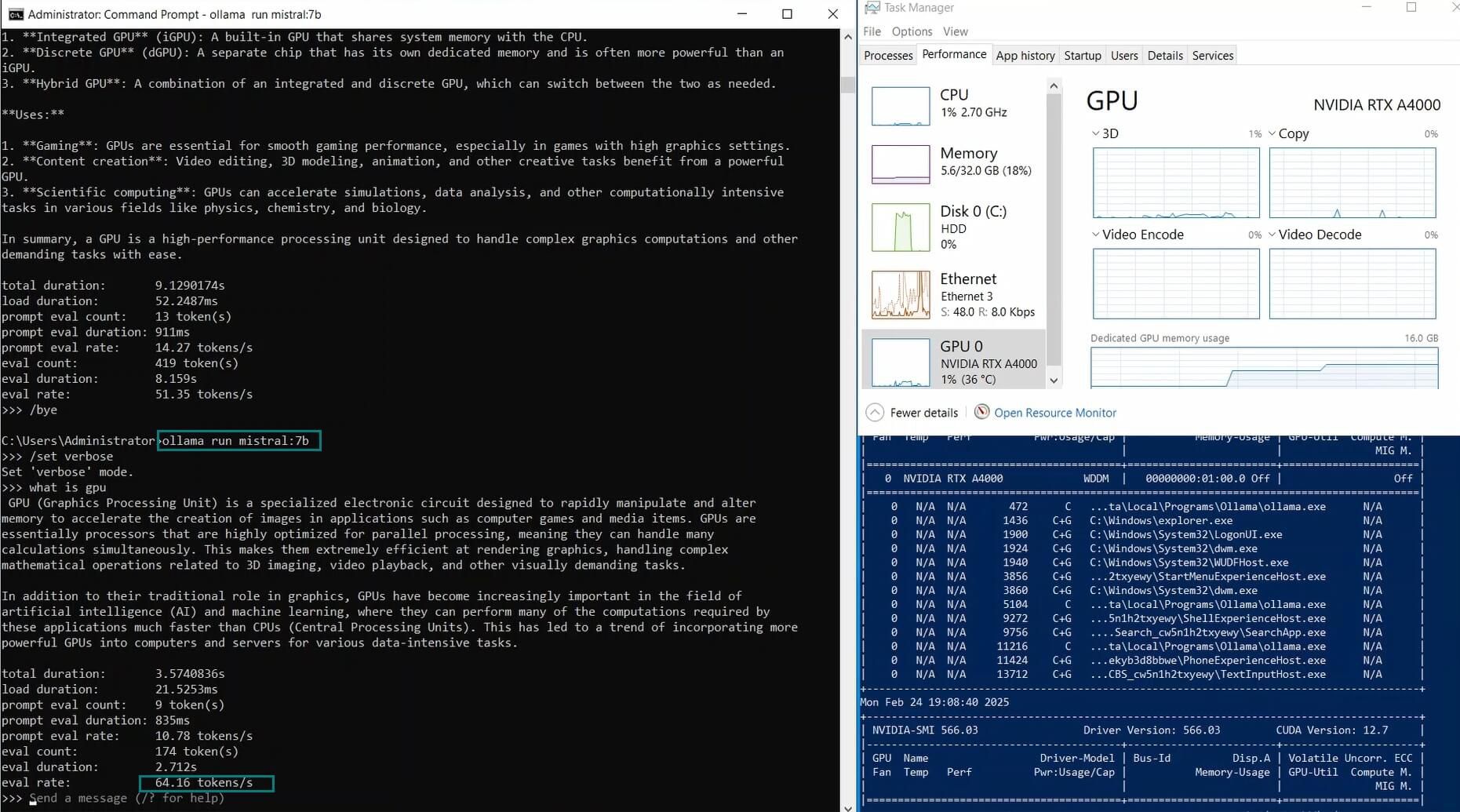
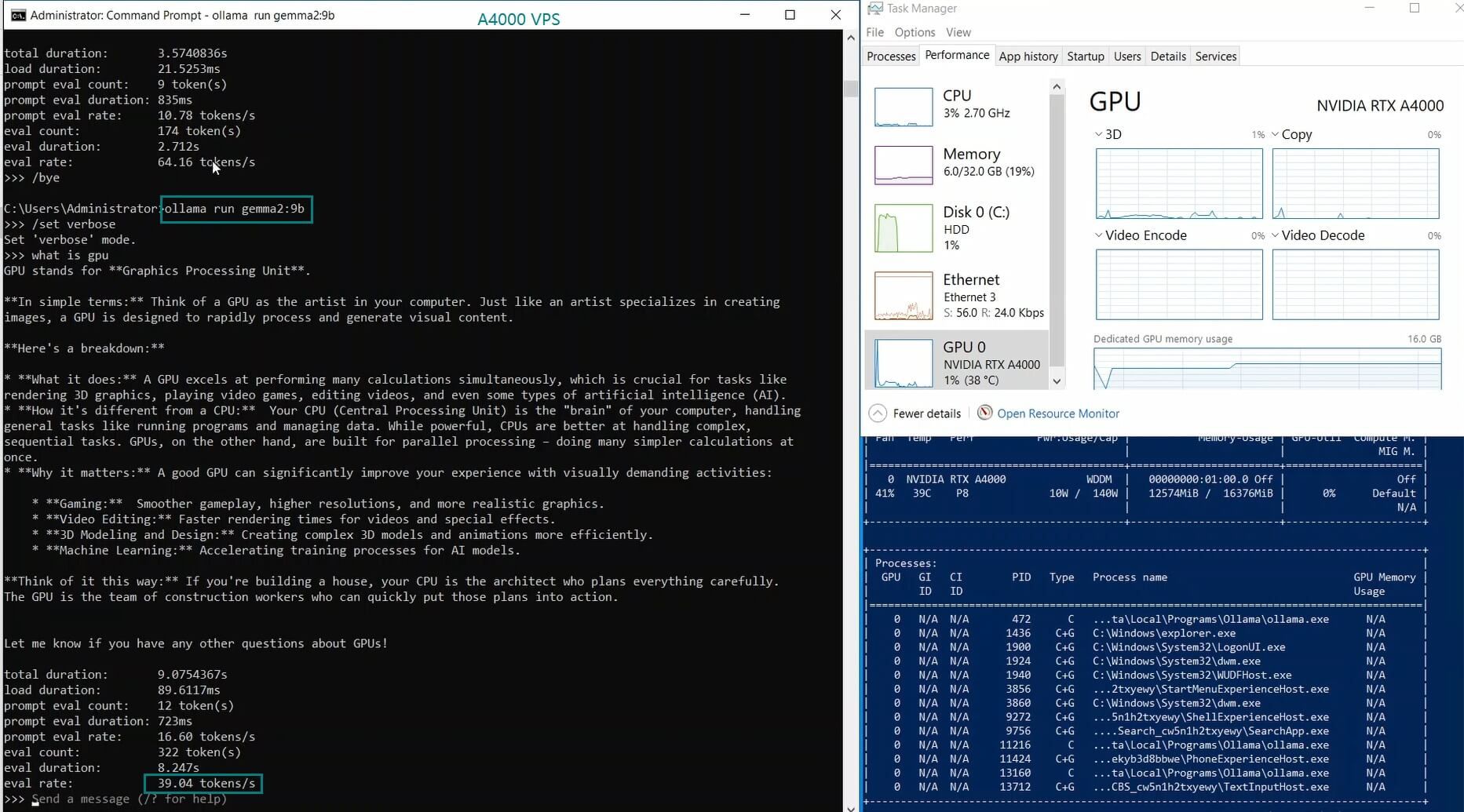
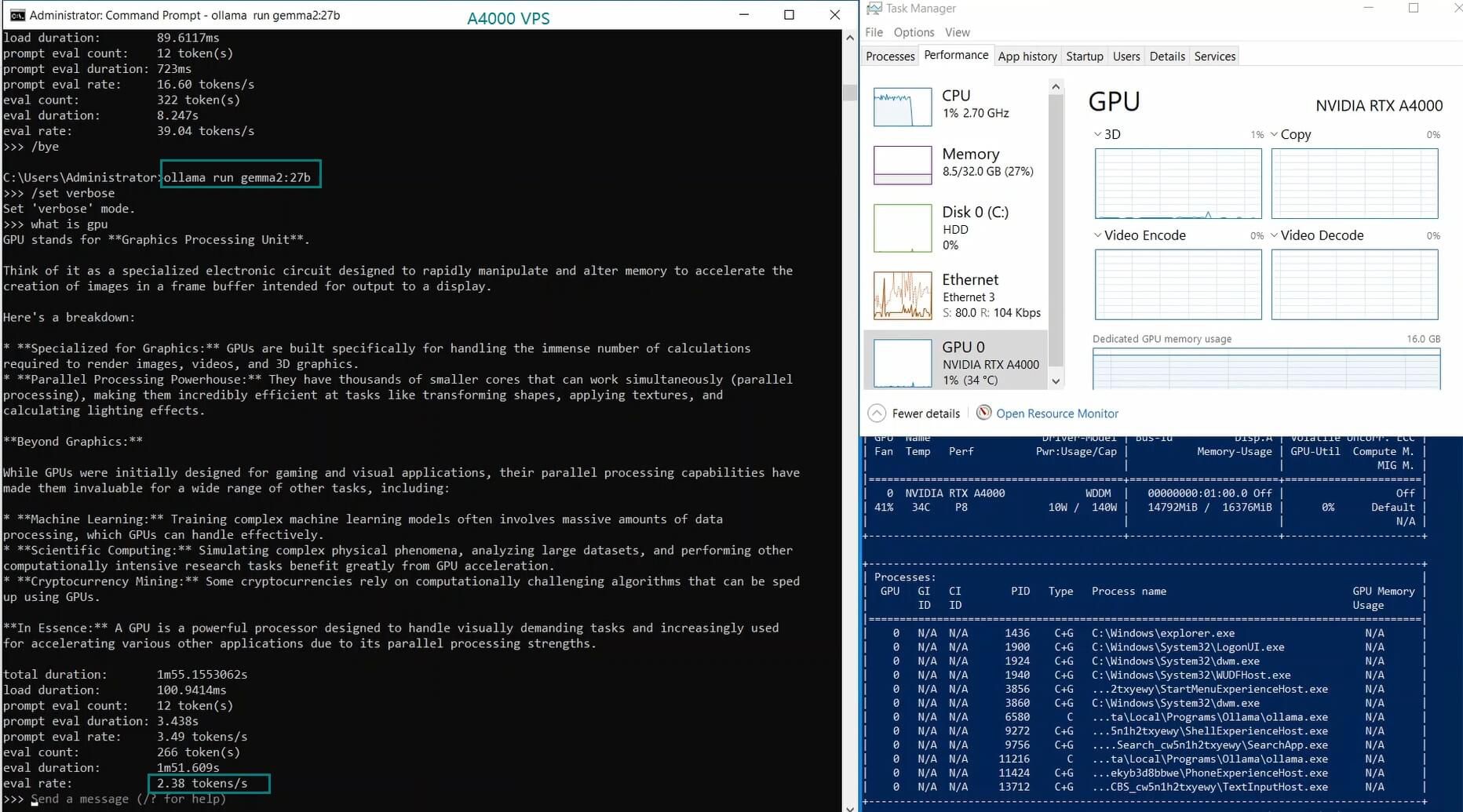
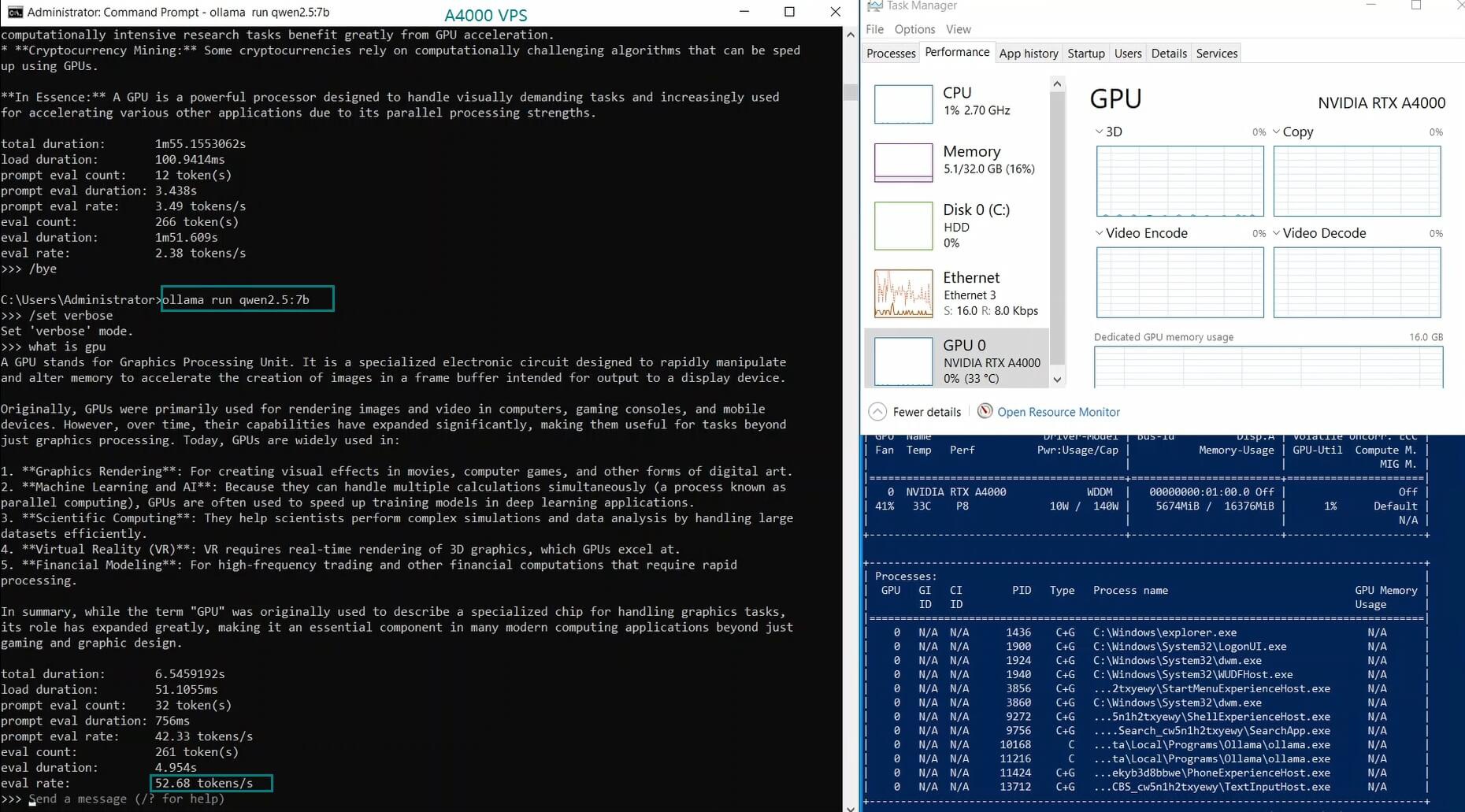
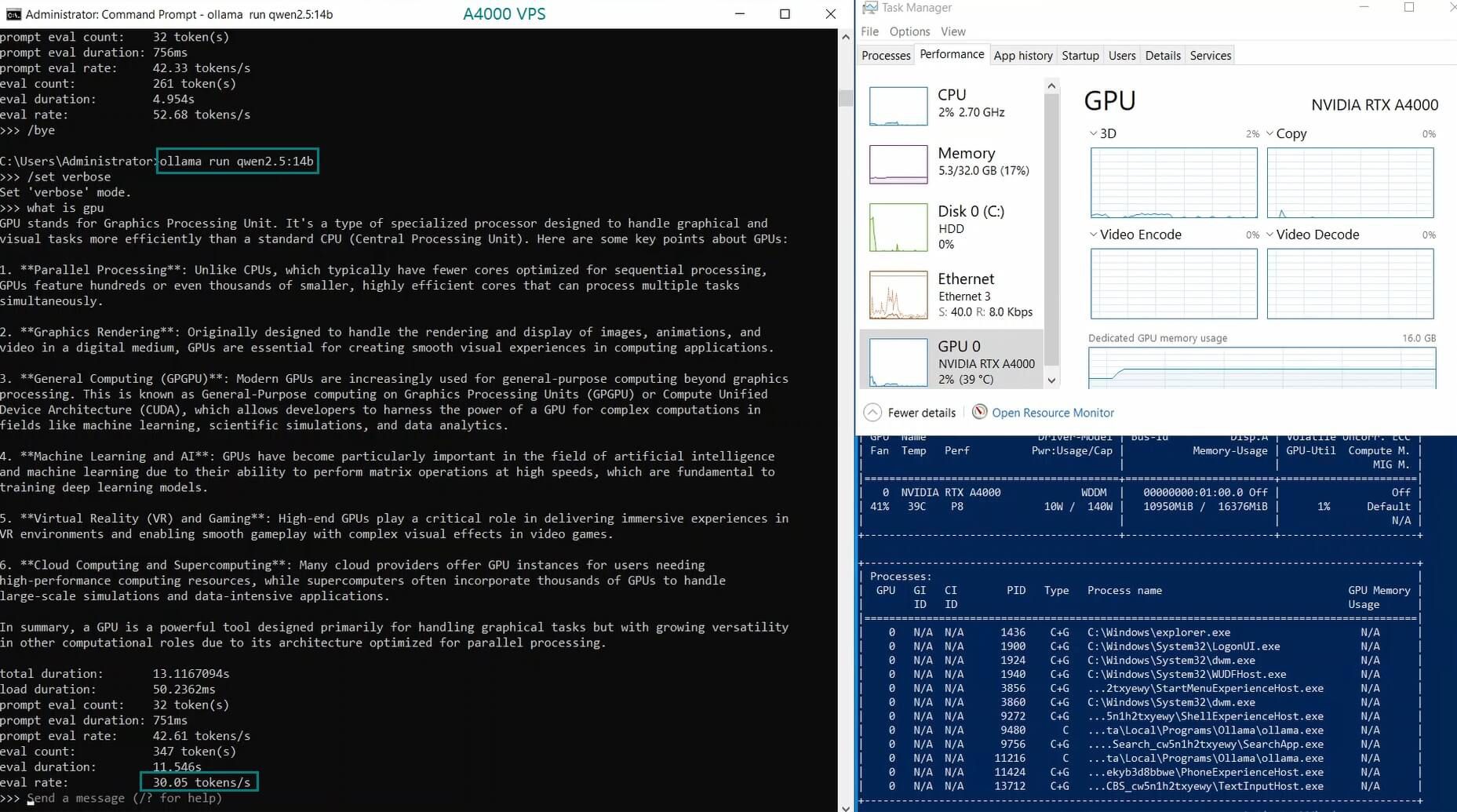
| 模型输出速率(tokens/s) | 52.61 | 51.60 | 30.20 | 22.89 | 65.06 | 38.46 | 51.35 | 64.16 | 39.04 | 2.38 | 52.68 | 30.05 |
基准测试关键结论
1. A4000 GPU能高效处理中等规模模型
2. A4000 VPS上高速推理的最佳模型
LLaMA 2 7B 和 Mistral 7B 模型表现优异,评估速度分别达到 65.06 个 token/s 和 64.16 个 token/s。它们在 GPU 利用率和推理速度之间实现了平衡,非常适合 Ollama A4000 VPS 上的实时应用。
3. DeepSeek-Coder 效率高但速度较慢
4. 240 亿以上的大型模型举步维艰
NVIDIA A4000 VPS 是否适合 LLM 推理?
✅ 使用 NVIDIA A4000 运行 Ollama 的优点
- 对于 LLaMA 2 和 Mistral 等 7B-14B 参数模型表现出色
- 相较于高端 GPU,是一种性价比较高的 Ollama VPS 解决方案
- 在 GPU 利用率和 Token 评估速率之间实现良好平衡
❌ 使用 NVIDIA A4000 运行 Ollama 的缺点
- 处理 24B+ 大模型时表现欠佳
- 在 DeepSeek-Coder 等复杂 LLM 上,性能可能大幅下降
A4000 VPS 在 AI 中的推荐用例
- 聊天机器人和人工智能助手(LLaMA 2 7B、Mistral 7B)
- 代码补全和人工智能编码(DeepSeek-Coder 16B)
- 人工智能研究与实验(Qwen 7B、Gemma 9B)
立即开始使用 A4000 VPS 托管 LLM!
GPU云服务器 - A4000
- 配置: 24核32GB, 独立IP
- 存储: 320GB SSD系统盘
- 带宽: 300Mbps 不限流
- 赠送: 每2周一次自动备份
- 系统: Win10/Linux
- 其他: 1个独立IP
- 独显: Nvidia RTX A4000
- 显存: 16GB GDDR6
- CUDA核心: 6144
- 单精度浮点: 19.2 TFLOPS
GPU物理服务器 - V100
- CPU: 24核E5-2690v3*2
- 内存: 128GB DDR4
- 系统盘: 240GB SSD
- 数据盘: 2TB SSD
- 系统: Win10/Linux
- 其他: 独立IP,100M-1G带宽
- 独显: Nvidia V100
- 显存: 16GB HBM2
- CUDA核心: 5120
- 单精度浮点: 14 TFLOPS
GPU物理服务器 - A5000
- CPU: 24核E5-2697v2*2
- 内存: 128GB DDR3
- 系统盘: 240GB SSD
- 数据盘: 2TB SSD
- 系统: Win10/Linux
- 其他: 独立IP,100M-1G带宽
- 独显: Nvidia RTX A5000
- 显存: 24GB GDDR6
- CUDA核心: 8192
- 单精度浮点: 27.8 TFLOPS
GPU物理服务器 - A6000
- CPU: 36核E5-2697v4*2
- 内存: 256GB DDR4
- 系统盘: 240GB SSD
- 数据盘: 2TB NVMe + 8TB SATA
- 系统: Win10/Linux
- 其他: 独立IP,100M-1G带宽
- 独显: Nvidia RTX A6000
- 显存: 48GB GDDR6
- CUDA核心: 10752
- 单精度浮点: 38.71 TFLOPS
最终总结
本次基准测试清楚地表明,NVIDIA A4000 VPS 托管是运行中型 AI 模型(如 Ollama LLMs)的理想选择。如果您在寻找兼具性价比与稳定性能的 VPS 方案,A4000 VPS 托管值得考虑。然而,对于 24B-32B 规模的更大型模型,可能需要更强大的 GPU 解决方案。
想获取更多 Ollama 基准测试、GPU VPS 托管评测及 AI 性能测试,敬请关注我们的最新更新!
ollama vps、ollama a4000、a4000 vps 托管、基准 a4000、ollama 基准、用于 llms 推理的 a4000、nvidia a4000 租赁、用于 ai 的 gpu vps、ollama 模型性能、深度学习 vps、在 a4000 上部署 ollama