
在 Ollama 上使用 Nvidia GTX 1660 GPU 服务器对大语言模型进行基准测试
GTX 1660 GPU 托管简介:Nvidia GeForce GTX 1660 是一款中端游戏显卡,如今也被用于服务器环境中运行大语言模型(LLM)。该显卡配备 6GB GDDR6 显存、1408 个 CUDA 核心,以及 5.0 TFLOPS 的 FP32 性能,是进行小规模语言模型推理任务的经济实惠选择。让我们来深入了解其性能表现。
测试服务器配置
在深入 Ollama GTX 1660 基准测试之前,让我们先看看服务器规格:
服务器配置:
- 价格: ¥1160.7月
- CPU: 双 10 核 Xeon E5-2660v2
- 内存: 64GB
- 存储: 120GB + 960GB SSD
- 网络: 100Mbps Unmetered
- 操作系统: Windows 11 Pro
GPU Details:
- GPU: Nvidia GeForce GTX 1660
- 计算能力: 7.5
- 微架构: Turing
- CUDA 核数: 1408
- 显存: 6GB GDDR6
- FP32 性能: 5.0 TFLOPS
该配置使 Nvidia GTX 1660 托管成为一个可行的选择,能够在保持成本可控的同时,高效运行小规模大语言模型(LLM)推理工作负载。
Ollama 基准测试:在 GTX 1660 服务器上测试大语言模型(LLM)
在测试中,我们使用 Ollama 0.5.11 对 Nvidia GTX 1660 GPU 上的多种大语言模型进行了基准测试。结果为在处理小型语言模型任务时,该 GPU 的性能提供了有价值的参考。
| 模型 | deepseek-r1 | deepseek-r1 | deepseek-r1 | deepseek-coder | llama3.2 | llama3.1 | codellama | mistral | gemma | codegemma | qwen2.5 | qwen2.5 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 参数 | 1.5b | 7b | 8b | 6.7b | 3b | 8b | 7b | 7b | 7b | 7b | 3b | 7b |
| 大小(GB) | 1.1 | 4.7 | 4.9 | 3.8 | 2.0 | 4.9 | 3.8 | 4.1 | 5.0 | 5.0 | 1.9 | 4.7 |
| 量化 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| 运行于 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 |
| 下载速度(兆字节/秒) | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 |
| CPU 使用率 | 6% | 20% | 28% | 18% | 6% | 30% | 17% | 4% | 45% | 30% | 6% | 18% |
| 内存占用率 | 8% | 9% | 10% | 9% | 8% | 10% | 8% | 8% | 12% | 12% | 8% | 9% |
| GPU 利用率 | 38% | 37% | 37% | 42% | 50% | 35% | 42% | 20% | 30% | 36% | 36% | 37% |
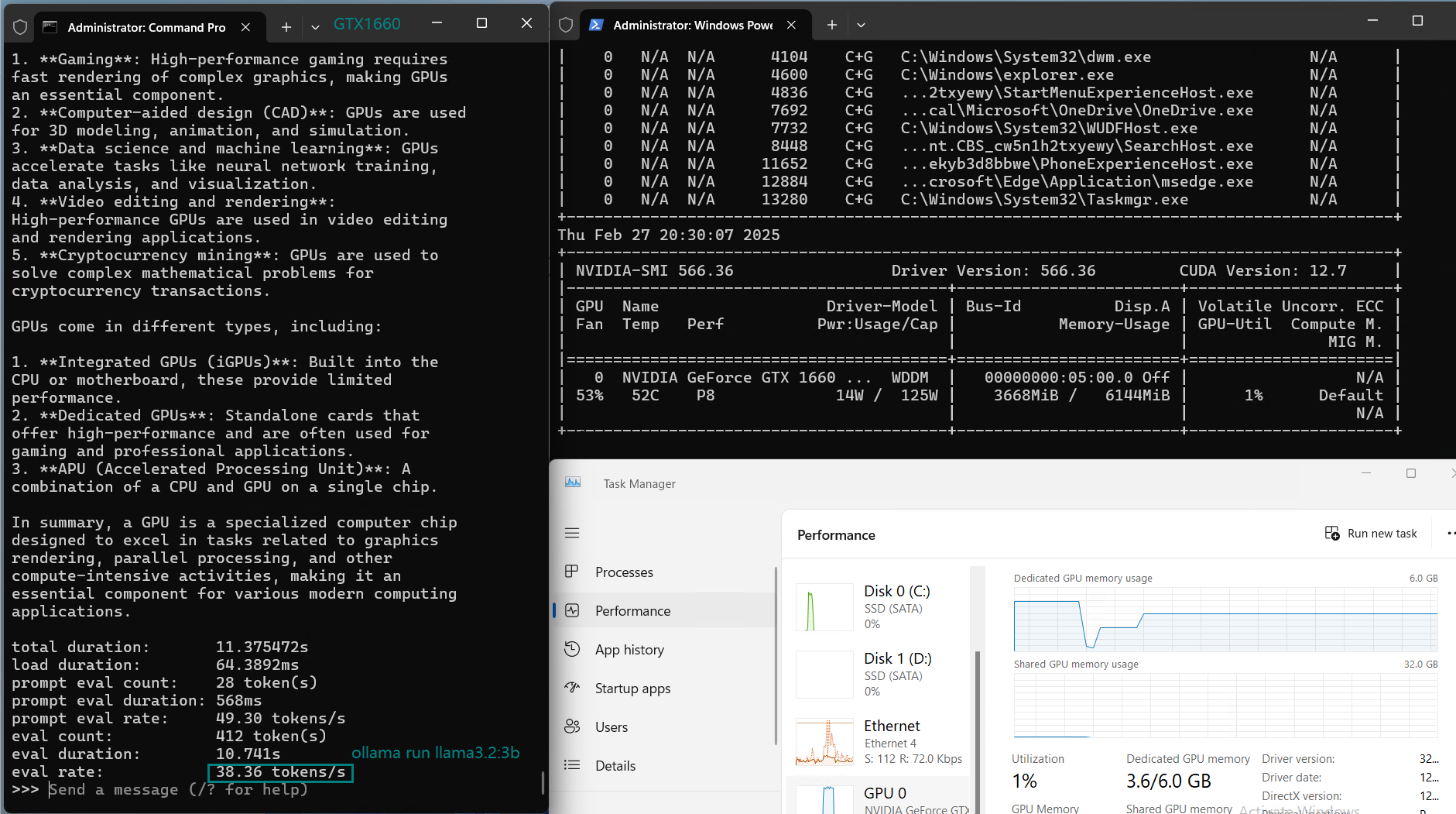
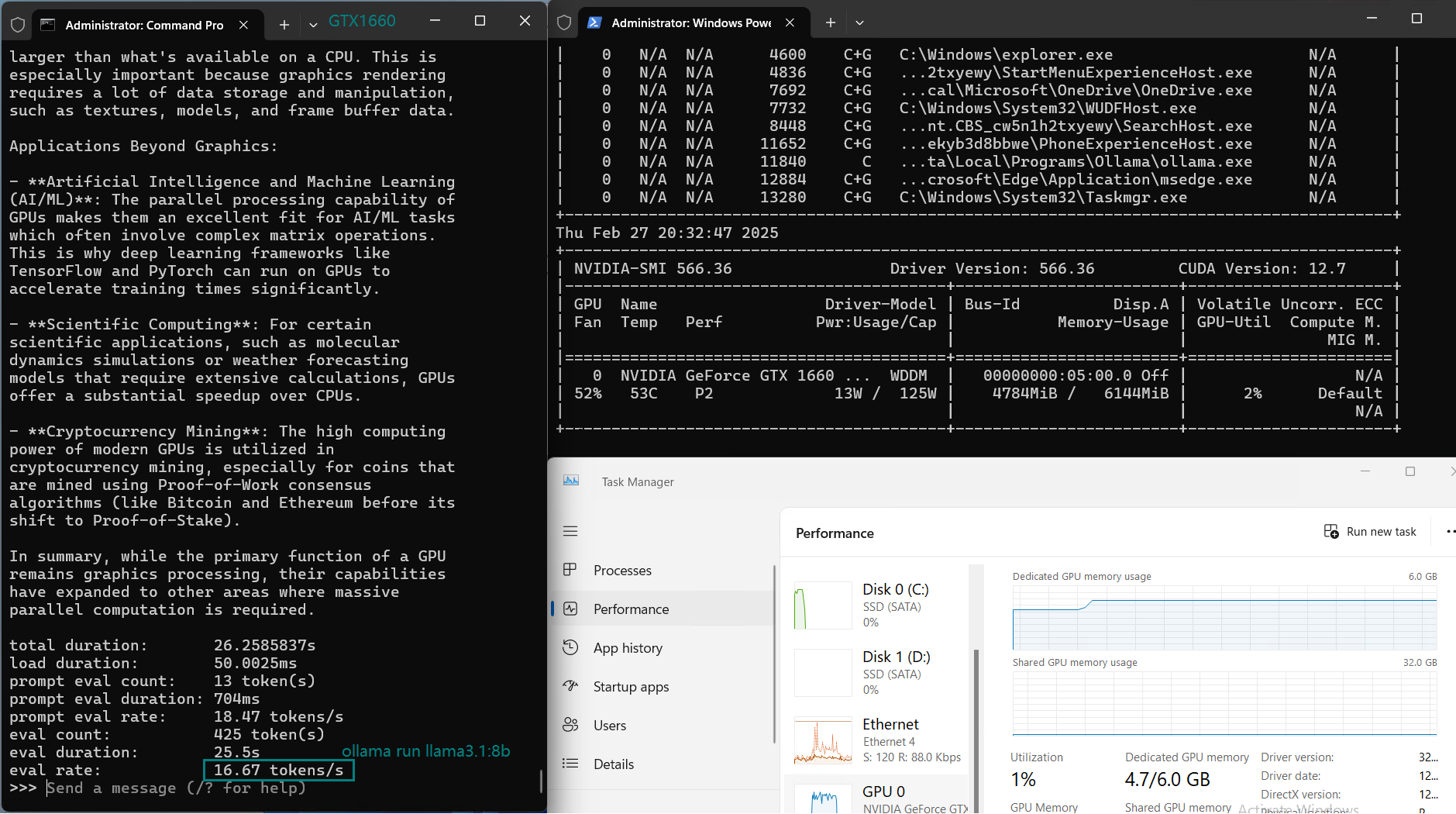
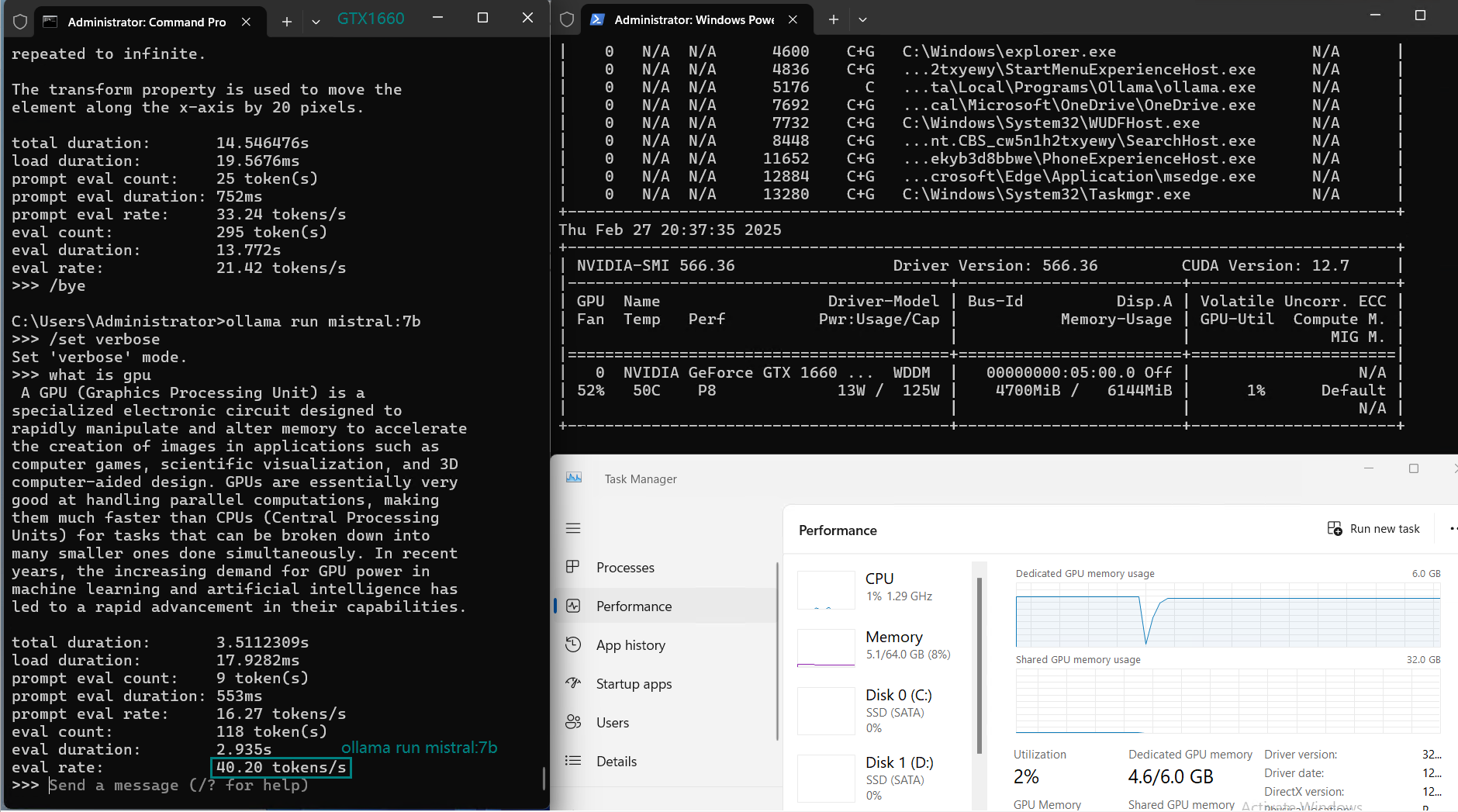
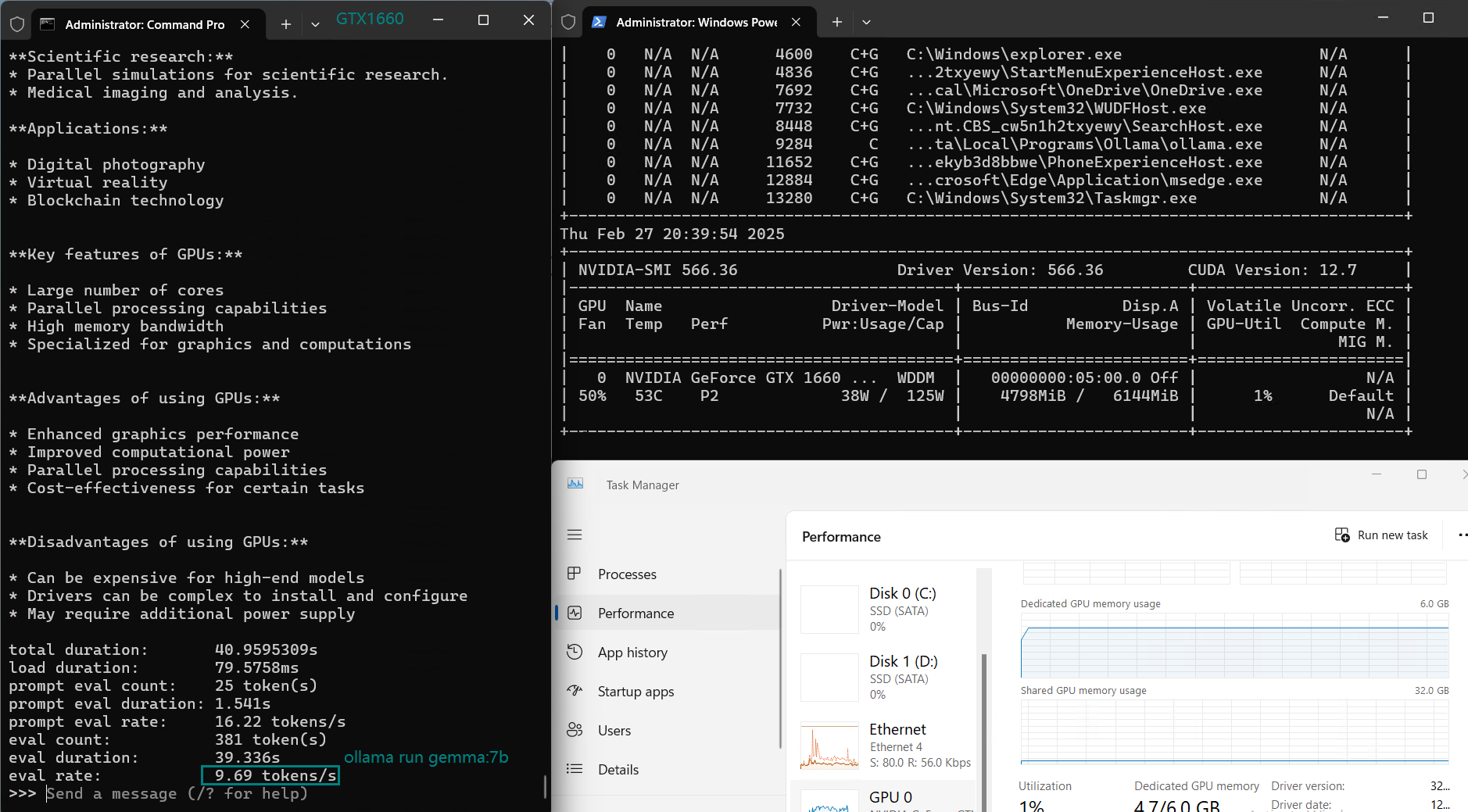
| 评估速率(tokens/s) | 30.16 | 18.29 | 16.26 | 21.31 | 38.36 | 16.67 | 21.42 | 40.2 | 9.69 | 9.39 | 26.28 | 18.24 |
一段用于记录 GTX 1660 GPU 服务器实时资源消耗数据的视频:
用于在 Nvidia GTX 1660 GPU 服务器上使用 Ollama 对大型语言模型进行基准测试的截图
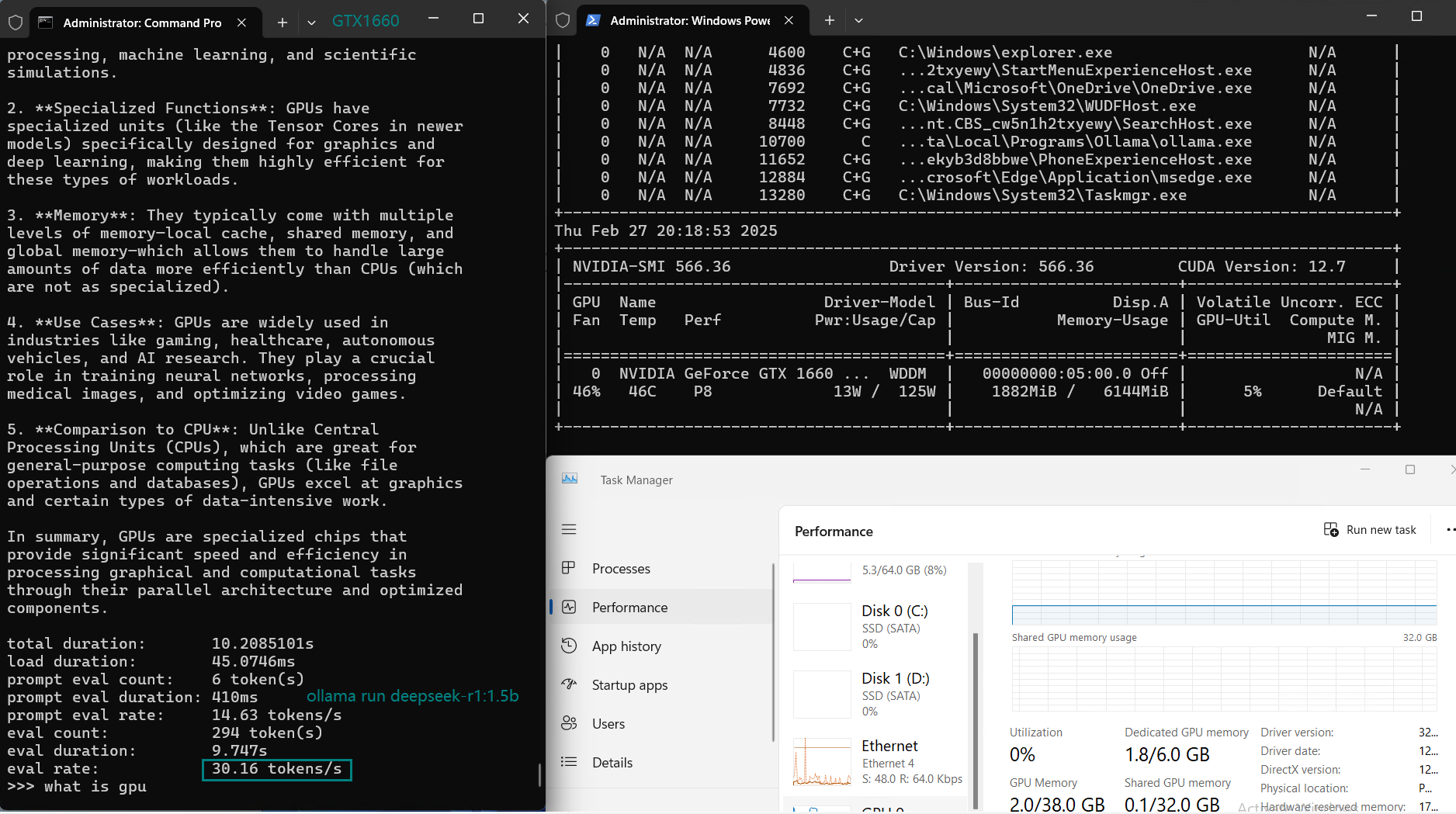
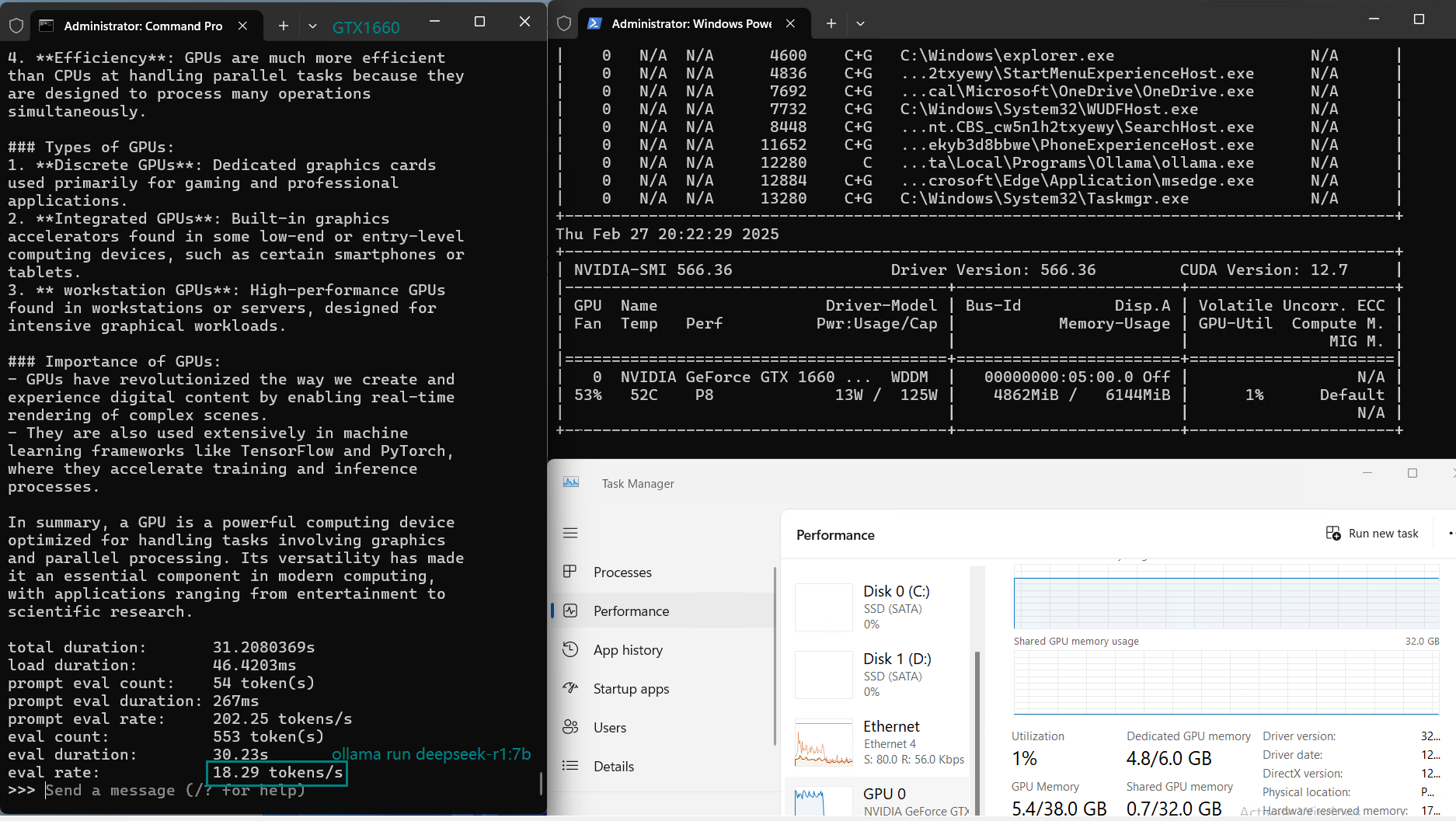
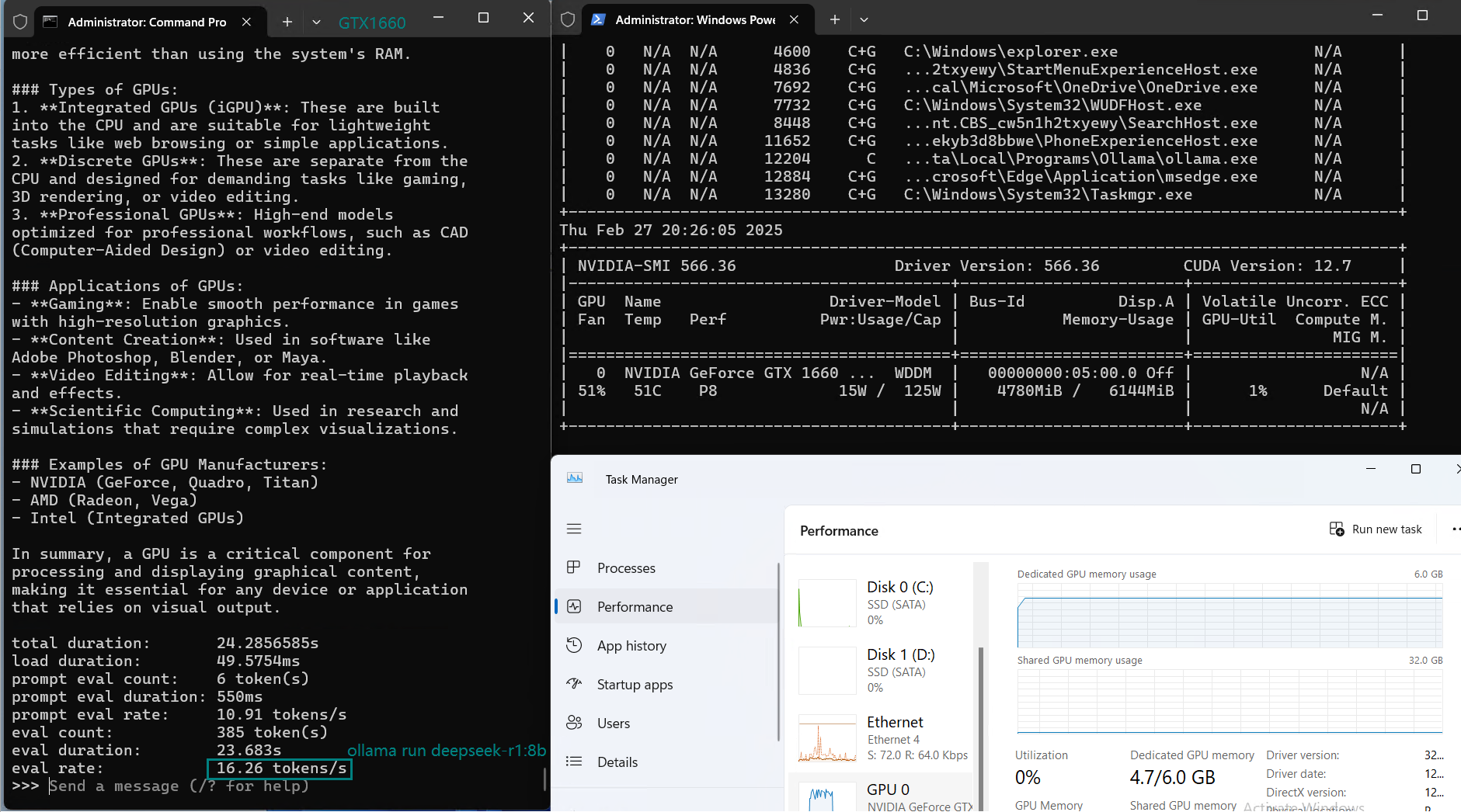
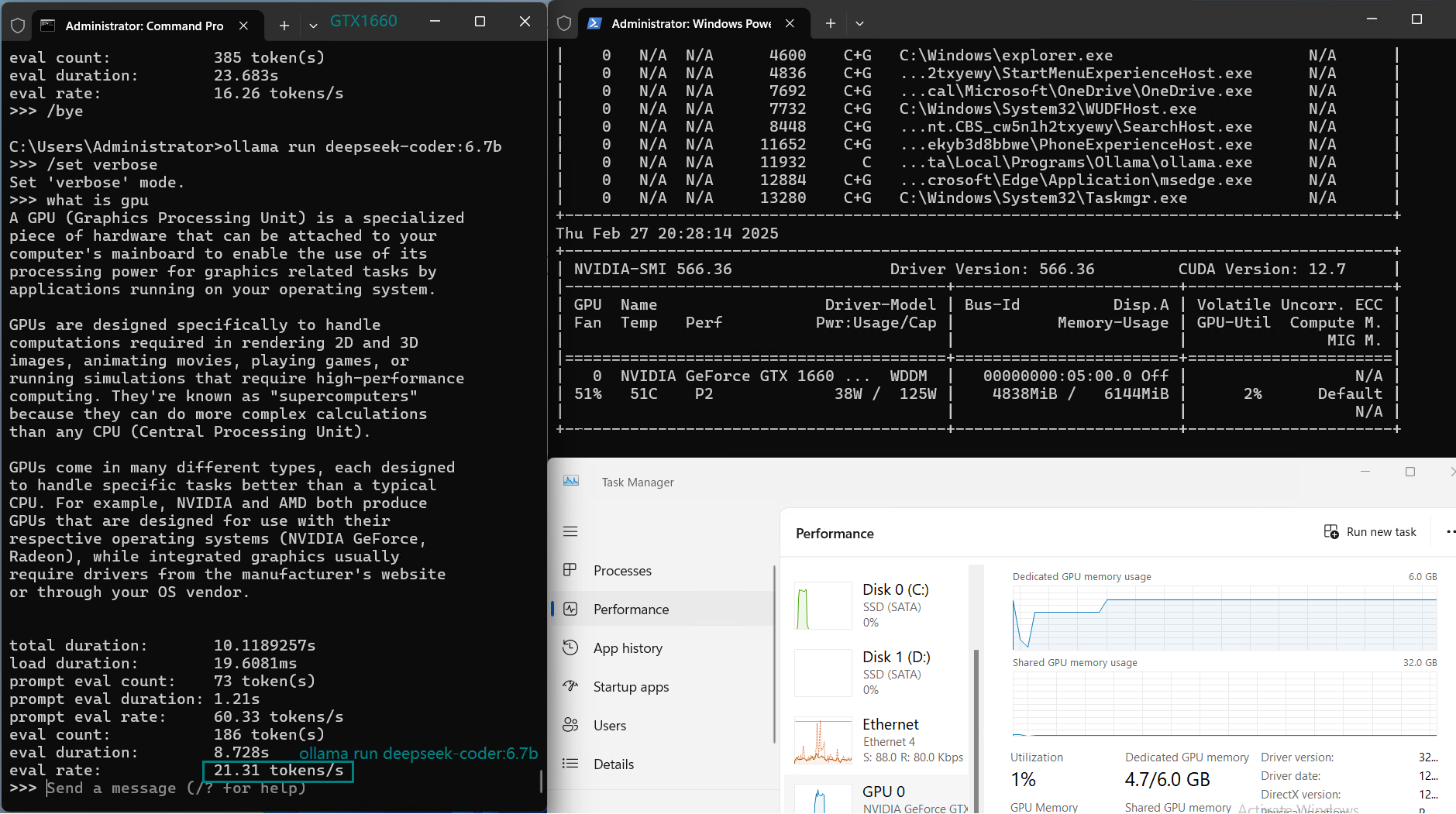

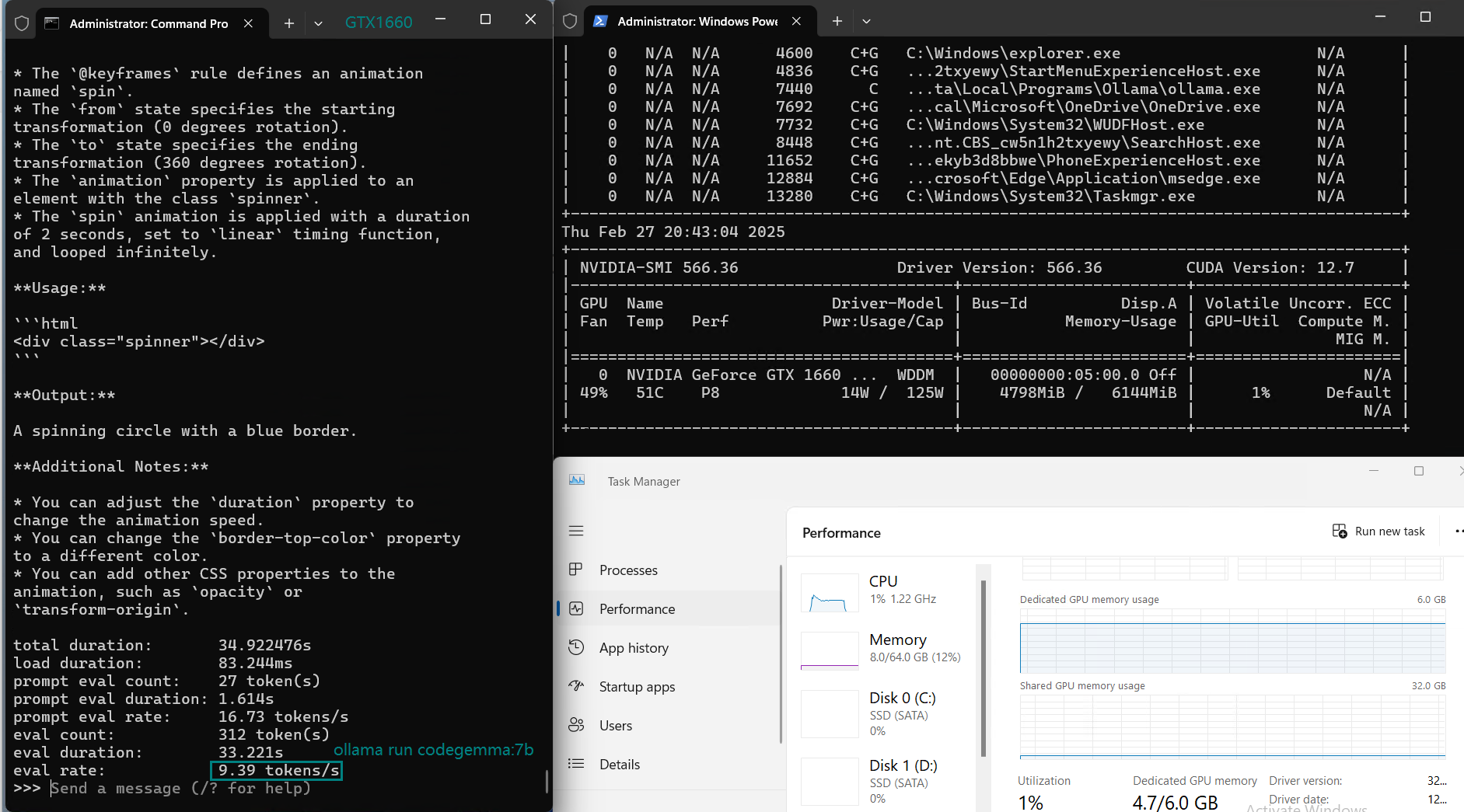
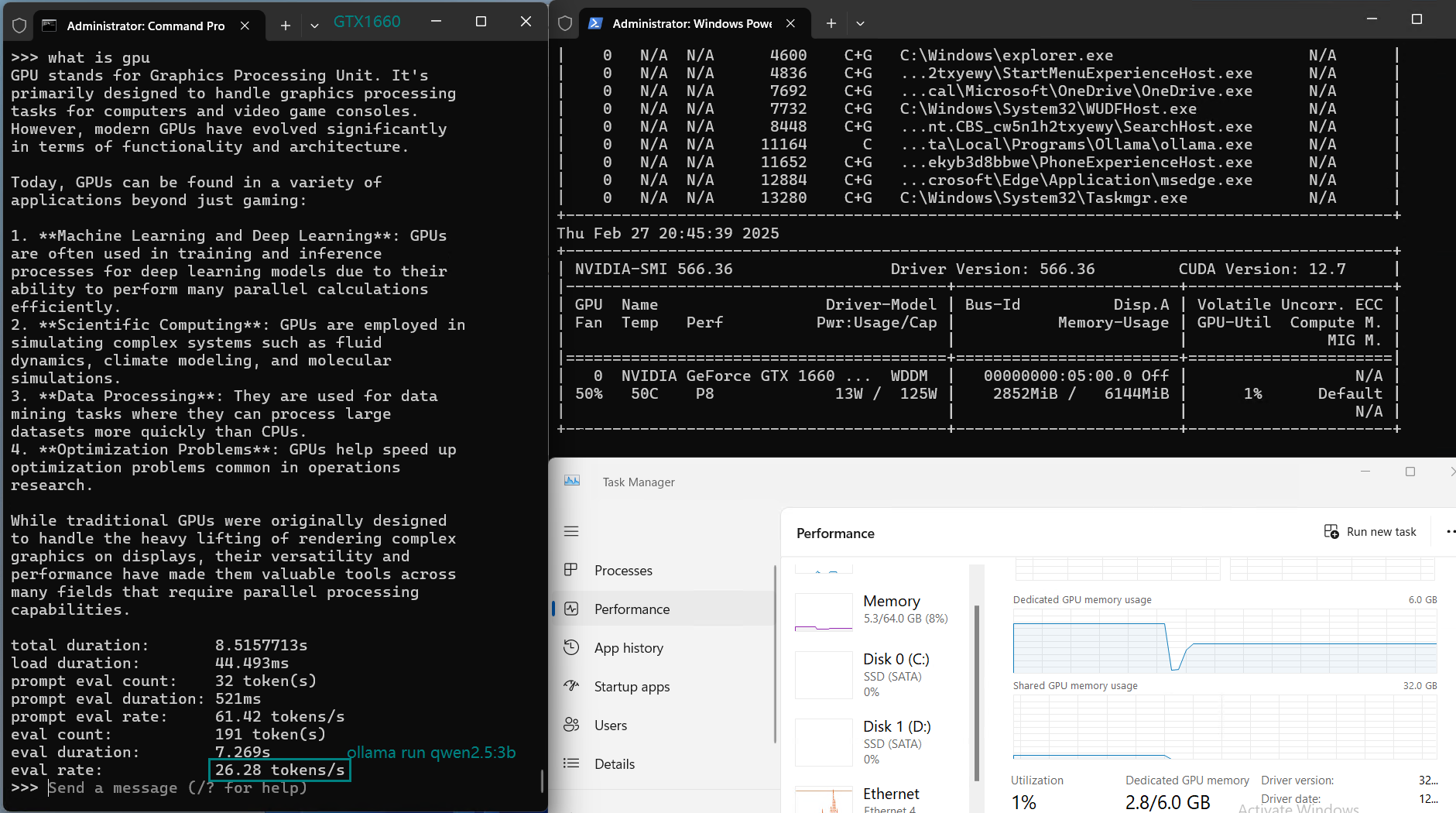
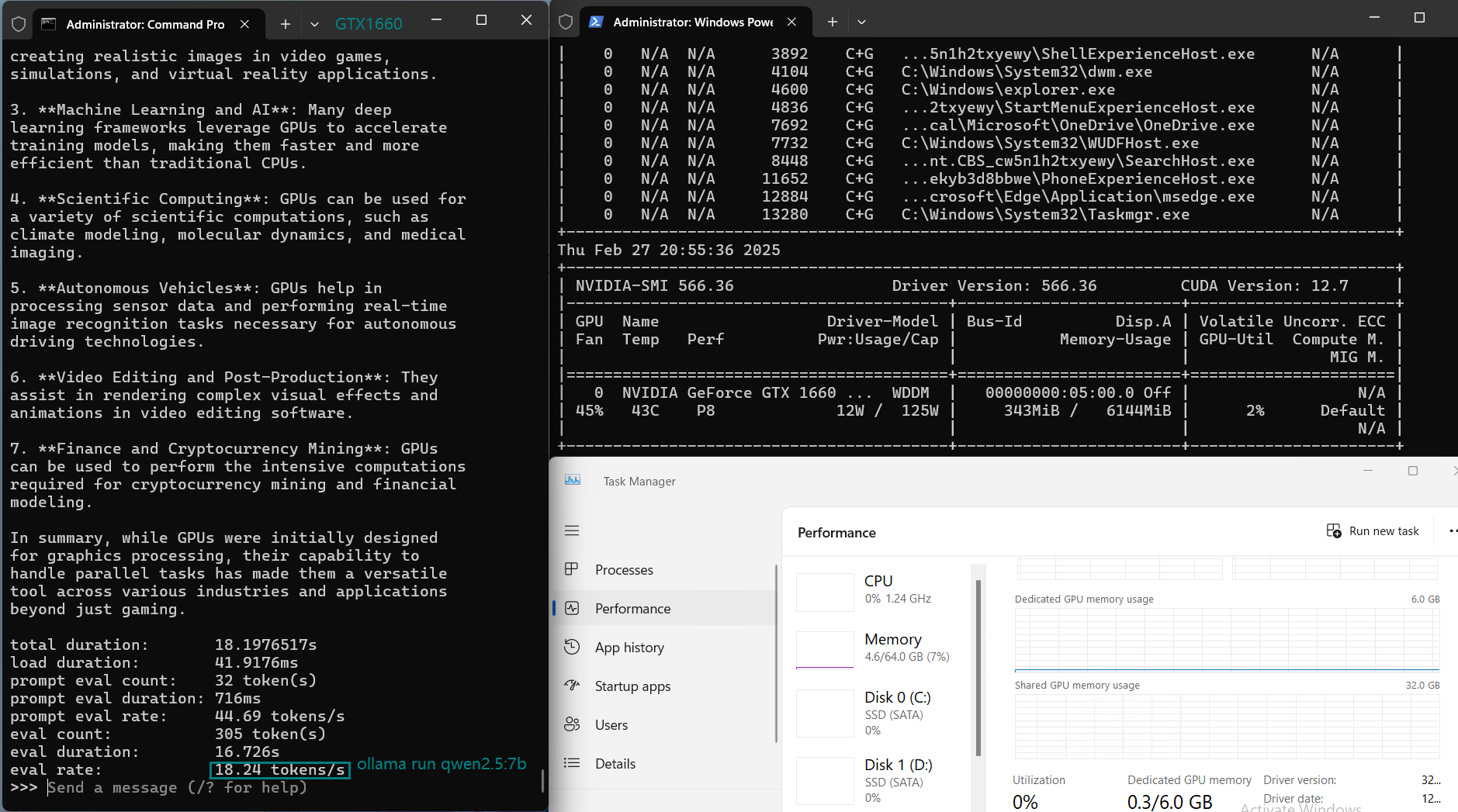
基准测试的主要发现
1️⃣.小模型最佳(7B及以下)
GTX 1660 GPU 在运行像 DeepSeek-r1(1.5B)和 LLama 2(7B)这样的小模型时表现出色。这些模型运行流畅,GPU 利用率高,推理速度合理(约 30-40 tokens/s)
2️⃣.大模型 CPU 负载增加
对于超过 7B 的模型,如 DeepSeek-r1(8B)和 LLama 3.1(8B),CPU 利用率增加,表明 GPU 内存(6GB)成为瓶颈,限制了性能。
3️⃣. 8B+ 模型表现不佳
GTX 1660 在 8B+ 范围的模型上表现困难,性能下降明显,CPU 使用率显著增加。显然,更大的模型不适合此 GPU。
4️⃣.大于 7B 模型性能下降
像 CodeGemma、Gemma 和 Mistral(7B)这样的模型,在保持 6GB VRAM 限制内时表现明显更好,但随着模型尺寸增加,性能下降,尤其是当模型超过 6GB VRAM 时。
GTX1660 小型 LLM 托管入门
在 Ollama 上部署 LLM 时,选择合适的 NVIDIA GTX1660 托管方案可显著提升性能并优化成本。对于 0.5B–7B 模型,GTX1660 是兼具价格与性能的理想 AI 推理方案。
春季特惠
GPU云服务器 - A4000
¥ 692.45/月
立省45% (原价¥1259.00)
月付季付年付两年付
立即订购- 配置: 24核32GB, 独立IP
- 存储: 320GB SSD系统盘
- 带宽: 300Mbps 不限流
- 赠送: 每2周一次自动备份
- 系统: Win10/Linux
- 其他: 1个独立IP
- 独显: Nvidia RTX A4000
- 显存: 16GB GDDR6
- CUDA核心: 6144
- 单精度浮点: 19.2 TFLOPS
GPU物理服务器 - GTX 1660
¥ 989.00/月
月付季付年付两年付
立即订购- CPU: 16核E5-2660*2
- 内存: 64GB DDR3
- 系统盘: 120GB SSD
- 数据盘: 960GB SSD
- 系统: Win10/Linux
- 其他: 独立IP,100M-1G带宽
- 独显: Nvidia GTX 1660
- 显存: 6GB GDDR6
- CUDA核心: 1408
- 单精度浮点: 5.0 TFLOPS
GPU物理服务器 - RTX 2060
¥ 1239.00/月
月付季付年付两年付
立即订购- CPU: 16核E5-2660*2
- 内存: 128GB DDR3
- 系统盘: 120GB SSD
- 数据盘: 960GB SSD
- 系统: Win10/Linux
- 其他: 独立IP,100M-1G带宽
- 独显: Nvidia RTX 2060
- 显存: 6GB GDDR6
- CUDA核心: 1920
- 单精度浮点: 6.5 TFLOPS
结论
Nvidia GTX 1660 GPU 是一种性价比高的方案,适合运行小型 LLM(1.5B–7B),可实现良好的推理速度(30–40 tokens/s),同时托管费用低至 $159/月。对于更大型的模型(如 8B 及以上),建议使用显存更大的 GPU 以获得最佳性能。这款 GTX 1660 VPS 非常适合从事小型语言模型开发、LLM 推理以及注重成本的项目的开发者。
标签:
ollama 1660, 小型 LLM 的 Ollama, Ollama GTX1660, Nvidia GTX1660 托管, GTX1660 基准测试, Ollama 基准测试, 用于 LLM 推理的 GTX1660, Nvidia GTX1660 租用, GTX 1660 LLM 托管, Nvidia 1660 性能