
Ollama P1000 基准测试:在 Ollama P1000 GPU 服务器上运行 LLM
对于开发者和研究人员来说,Ollama 已成为一个强大的平台,可以在各种硬件配置上测试和部署大型语言模型(LLM)。在本文中,我们将深入探讨在配备 Nvidia Quadro P1000 GPU 的专用服务器上运行 Ollama 的基准性能。我们将评估其运行 LLaMA、Gemma、Qwen 等流行模型的能力,并提供关于其性能指标的详细见解。
测试服务器环境
美国服务器测试环境配置了以下硬件和软件规格:
服务器配置:
- CPU:八核 Xeon E5-2690
- 内存:32GB
- 存储:120GB SSD + 960GB SSD
- 带宽:100Mbps
- 操作系统:Ubuntu 24.0
GPU详细信息:
- GPU型号:Nvidia Quadro P1000
- 微架构:Pascal
- 计算能力:6.1
- CUDA 核心数:640
- GPU内存:4GB GDDR5
- FP32 性能:1.894 TFLOPS
基准测试结果:Ollama GPU P1000 性能指标
以下是我们在 P1000 GPU 上运行模型时获得的基准测试结果:
| 模型 | llama3.2 | llama3.2 | gemma2 | codegemma | qwen2.5 | qwen2.5 | qwen2.5 | tinyllama | phi3.5 |
|---|---|---|---|---|---|---|---|---|---|
| 参数 | 1b | 3b | 2b | 2b | 0.5b | 1.5b | 3b | 1.1b | 3.8b |
| 尺寸 | 1.3GB | 2GB | 1.6GB | 1.6GB | 395MB | 1.1GB | 1.9GB | 638MB | 2.2GB |
| 量化 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| 运行平台 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 |
| 下载速度(mb/s) | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 |
| CPU 占用率 | 6.7% | 6.3% | 6.3% | 6.3% | 6.5% | 6.3% | 6.3% | 6.4% | 6.4% |
| RAM 占用率 | 4.5% | 4.8% | 4.9% | 5.0% | 5.4% | 5.4% | 4.0% | 4.0% | 4.2% |
| GPU 内存占用率 | 51.9% | 80.2% | 72.4% | 53.4% | 20% | 37.2% | 60.8% | 33.2% | 74% |
| GPU 利用率 | 92% | 95% | 89% | 96% | 80% | 89% | 95% | 93% | 97% |
| 模型输出速率(tokens/s) | 28.90 | 19.97 | 19.46 | 30.59 | 54.78 | 34.43 | 17.92 | 62.33 | 18.87 |
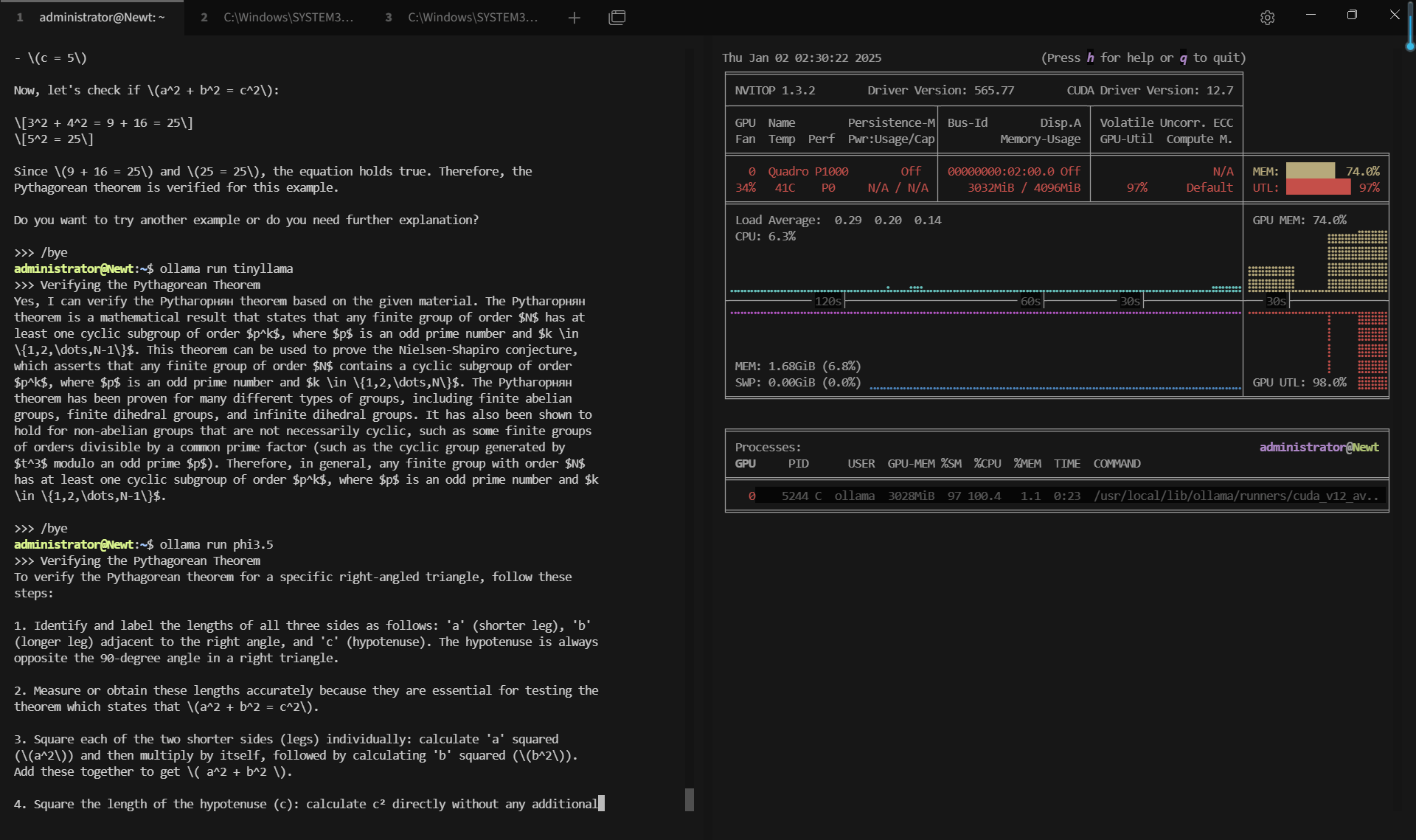
记录实时gpu服务器资源消耗数据:
屏幕截图:点击放大并查看
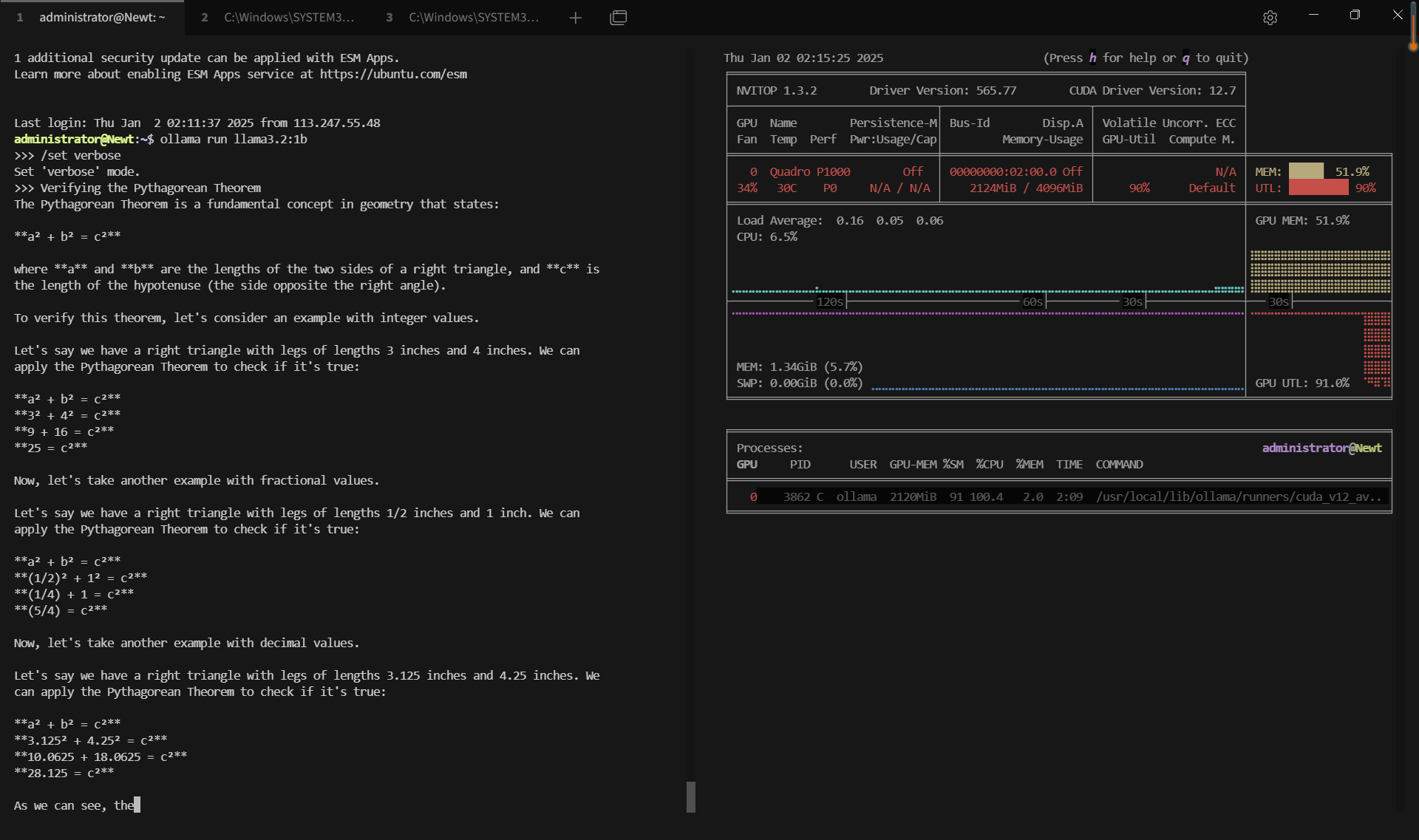
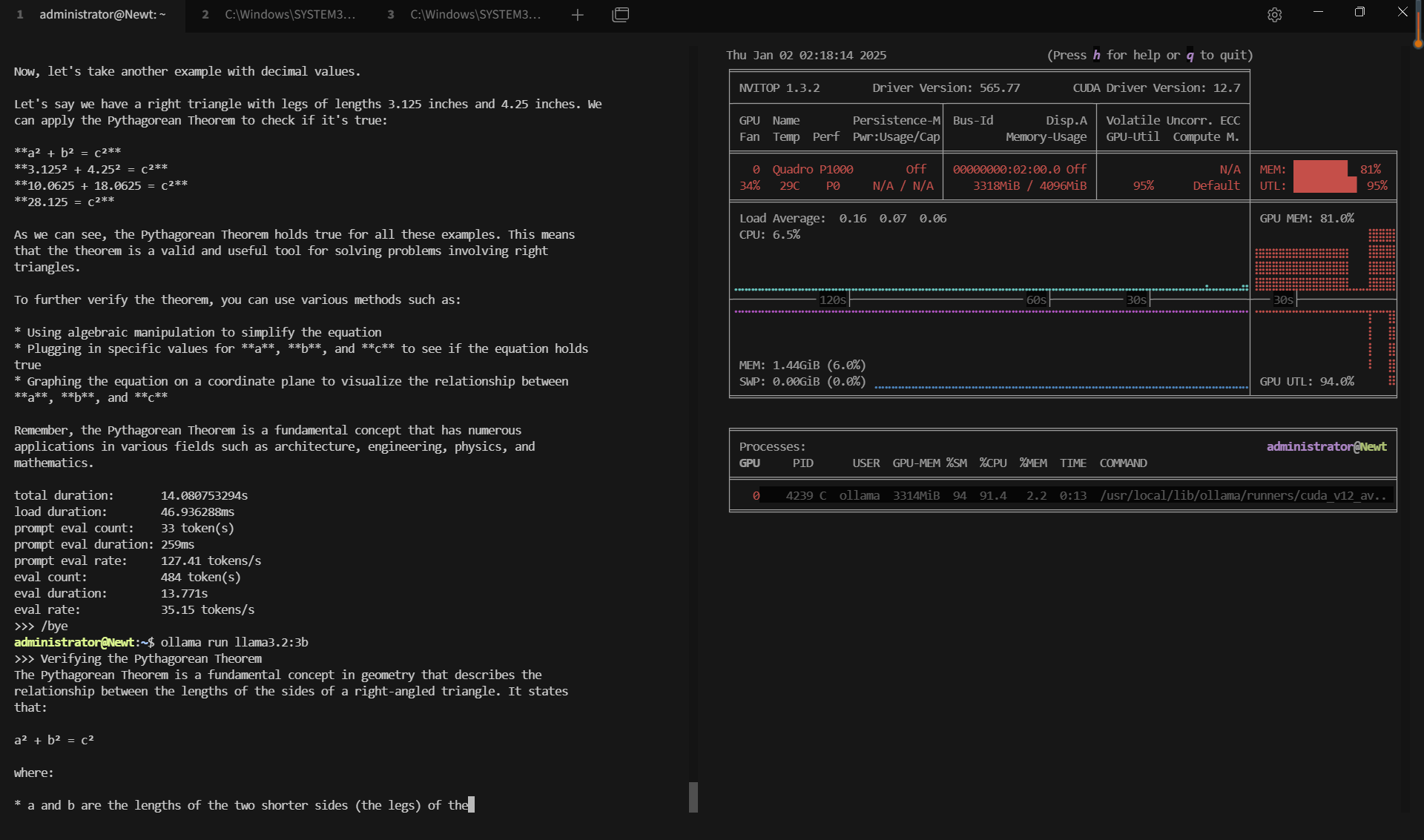
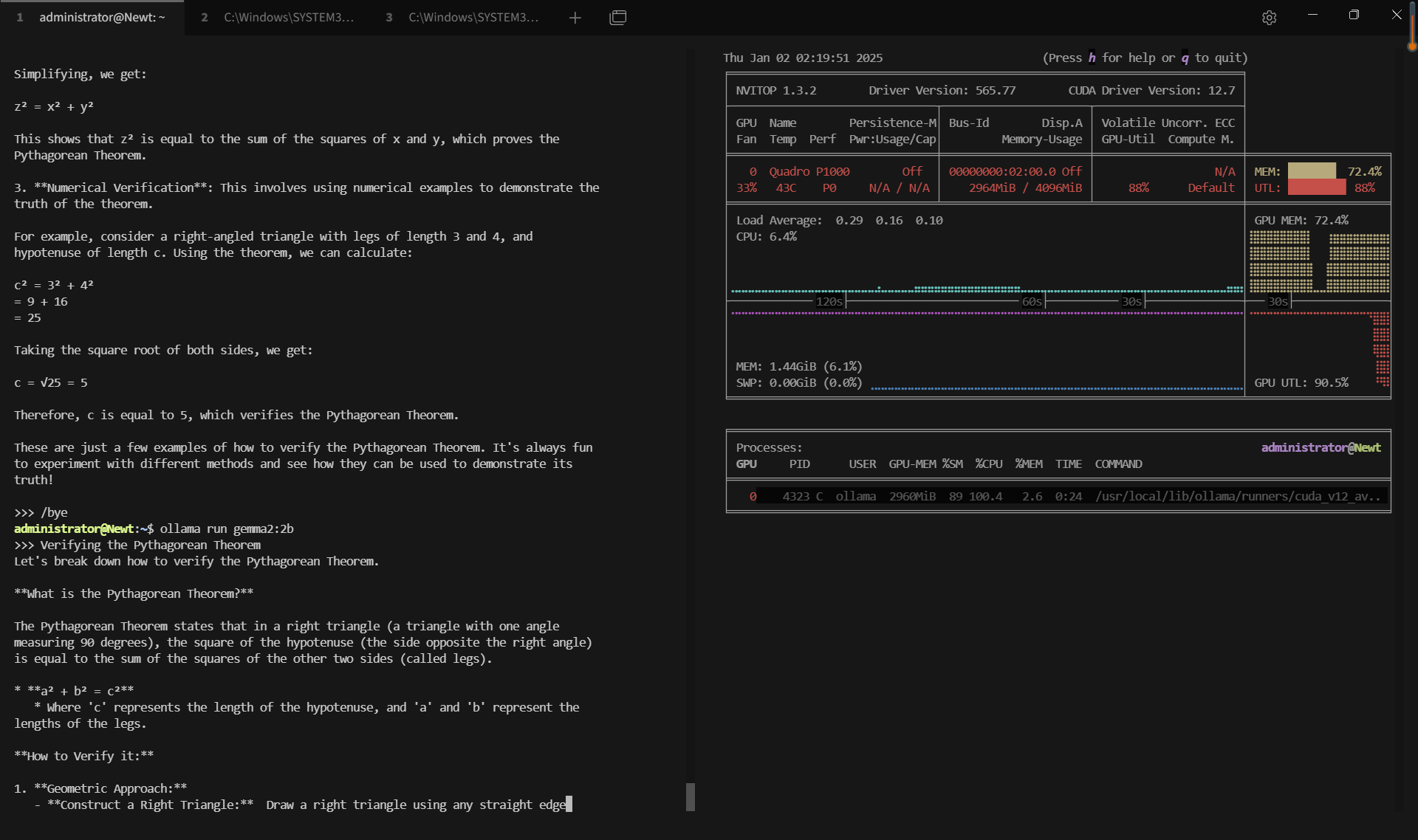
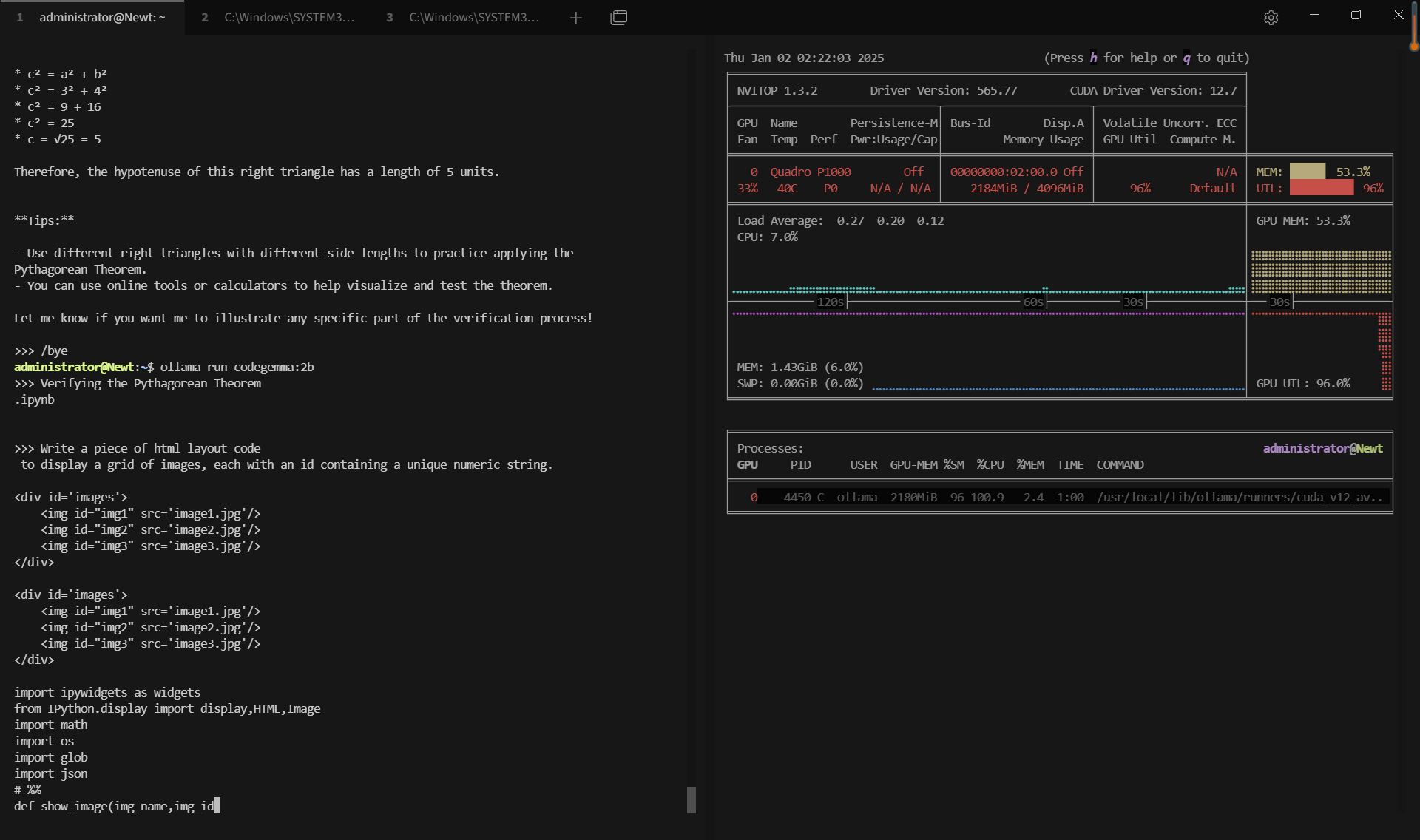
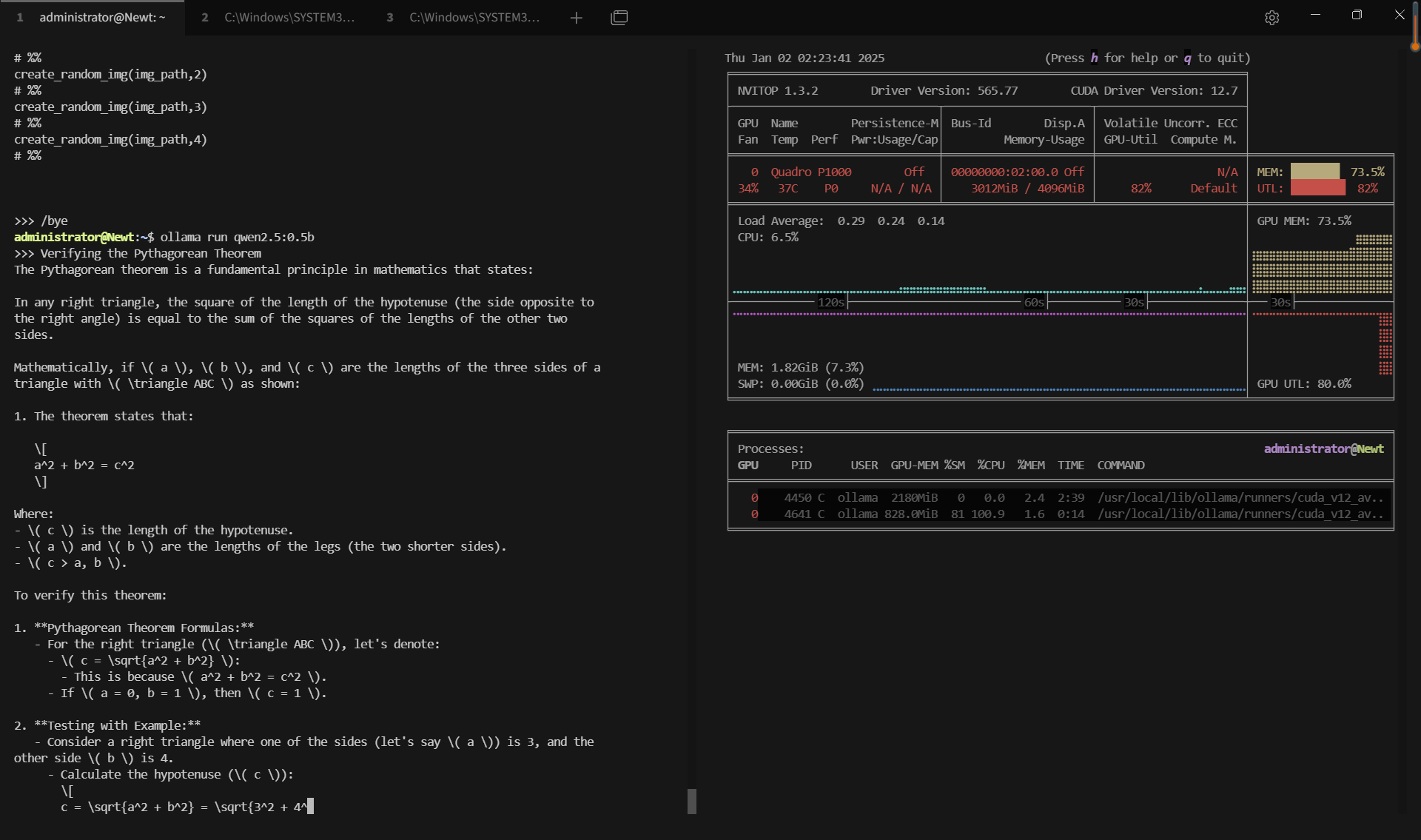
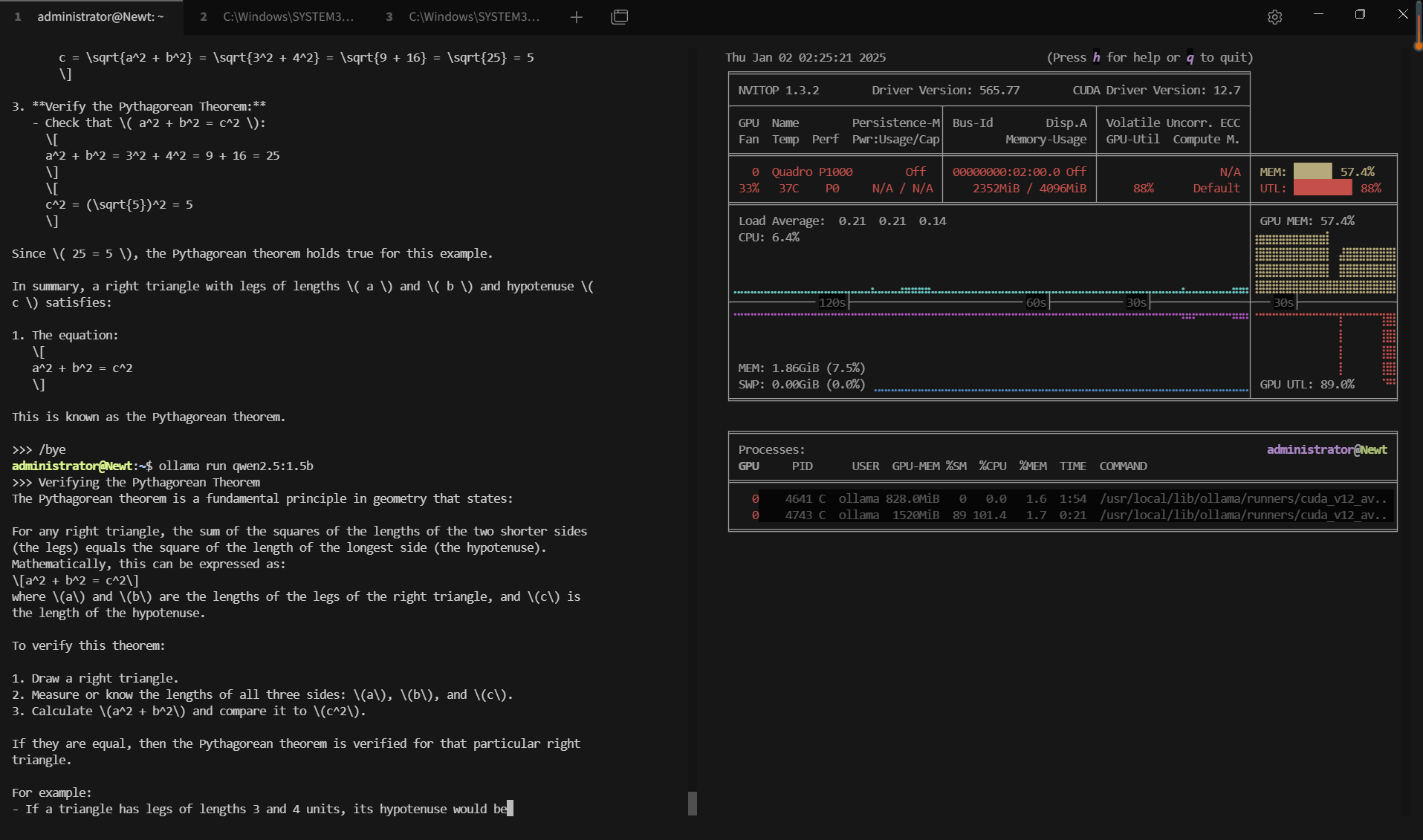
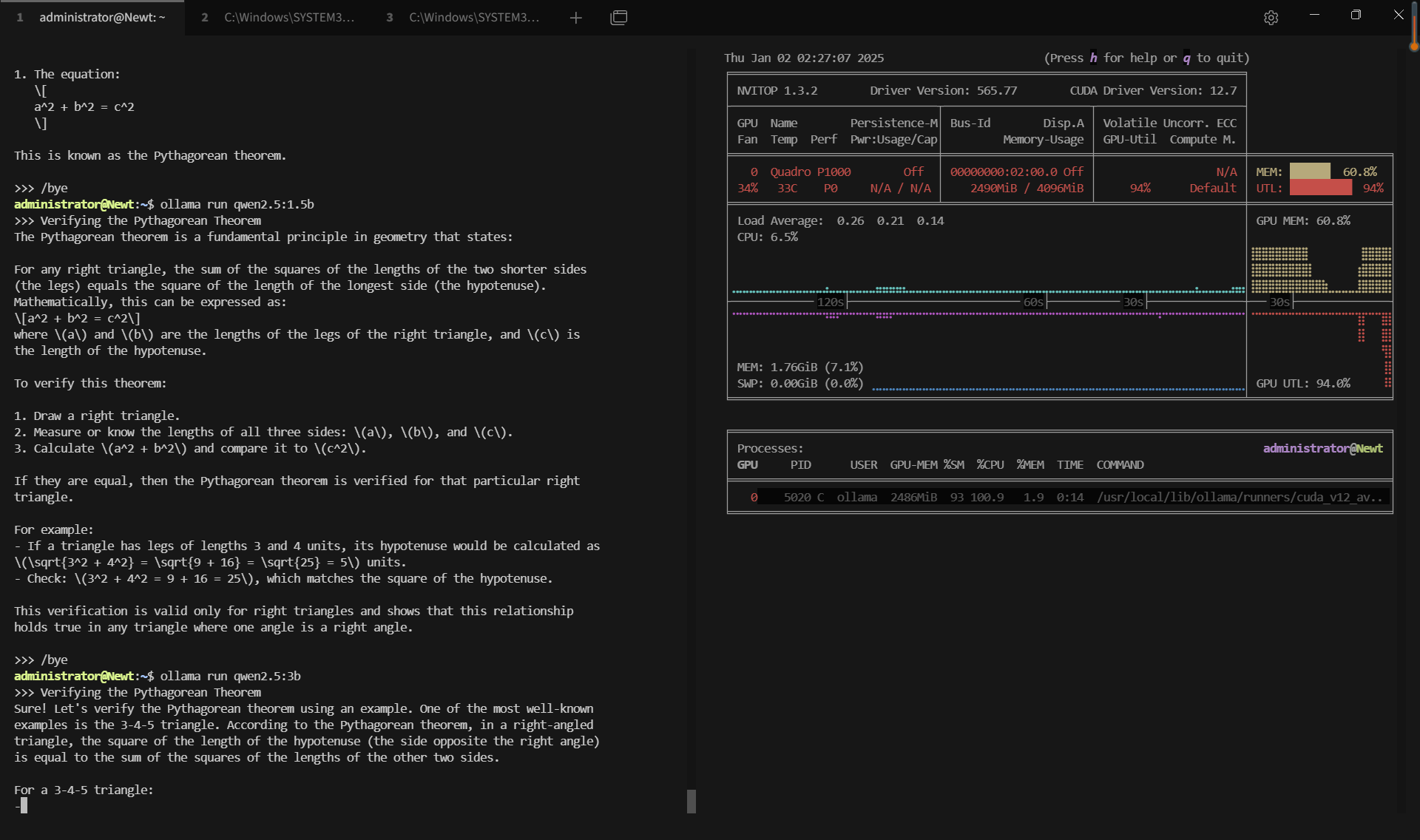
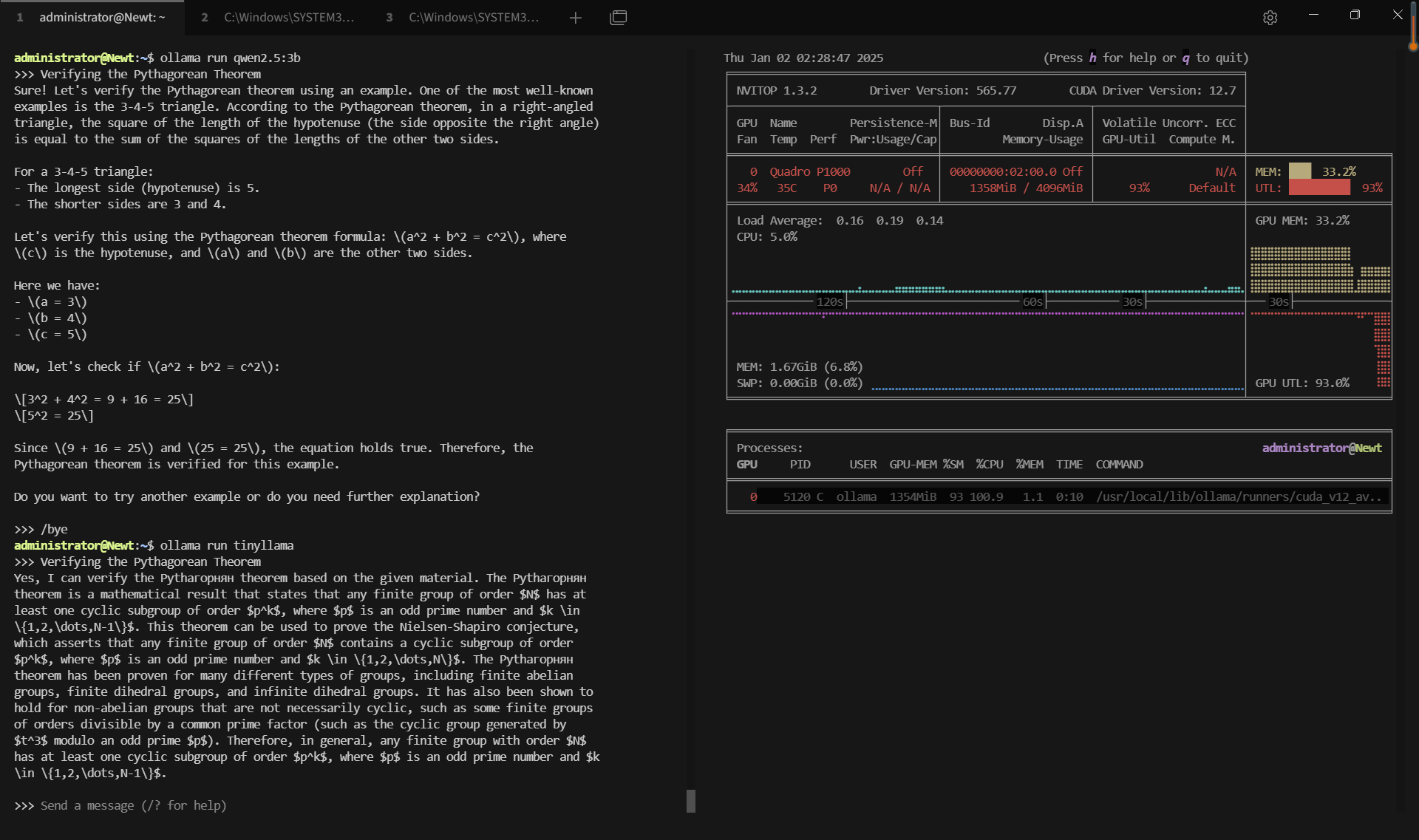
关键要点总结
1. 在有限资源上的卓越 GPU 效率
尽管配备了 Nvidia Quadro P1000 等中低端 GPU,Ollama 在所有测试模型中都表现出了出色的 GPU 利用率(89-97%)。得益于 Ollama 的 4 位量化,服务器的 4GB GPU 内存足以处理高达 3.8B 参数的模型。
2. 评估速率与模型大小的差异
TinyLlama(11 亿个参数)等较轻的模型实现了 62.33 个 token/s 的评估速度,非常适合低延迟应用。Phi3.5(38 亿个参数)和 Llama3.2-3B 等较重的模型以 18-20 个 token/s 的速度处理,从而平衡了计算需求和性能。
3. 最小化的 CPU 和 RAM 负载
即使对于3B的模型,CPU 和 RAM 的利用率也保持极低。这为同一台服务器上的额外工作负载留出了空间,而不会影响性能。
| 度量标准 | 各种模型的值 |
|---|---|
| 下载速度 | 所有模型均为 11 MB/s |
| CPU 利用率 | 各模型之间在 6.3% 到 6.7% 之间 |
| RAM 利用率 | 始终在 4% 到 5.4% 之间 |
| GPU vRAM 利用率 | 20%(Qwen2.5)到 80.2%(Llama3.2-3B) |
| GPU 利用率 | 在 89% 到 97% 之间,展示了高效的 GPU 利用 |
| 评估速度 | 从 17.92 tokens/s(Qwen2.5)到 62.33 tokens/s(TinyLlama) |
适合Ollama 的 P1000 GPU 服务器应用场景
- 边缘 AI 部署:适用于寻求在中端服务器上以经济高效的方式部署 AI 应用程序的企业。
- LLM 测试和原型设计:开发人员可以在受限的 GPU 环境下测试不同的模型,在扩展到更大的基础设施之前获得有关其行为的宝贵见解。
- 教育目的:大学和实验室可以使用此类设置来培训学生或执行小规模的法学硕士研究项目。
📢 开始租用 P1000 GPU 托管 LLM
如果您希望优化 0.5b~4b 的 AI 推理任务,请立即探索我们的 P1000 专用服务器托管选项!
GPU物理服务器 - P1000
¥ 459.00/月
月付季付年付两年付
立即订购- CPU: 8核E5-2690
- 内存: 32GB DDR3
- 系统盘: 120GB SSD
- 数据盘: 960GB SSD
- 系统: Win10/Linux
- 其他: 独立IP,100M-1G带宽
- 独显:Nvidia P1000
- 显存: 4GB GDDR5
- CUDA核心: 640
- 单精度浮点: 1.894 TFLOPS
GPU物理服务器 - T1000
¥ 739.00/月
月付季付年付两年付
立即订购- CPU: 8核E5-2690
- 内存: 64GB DDR3
- 系统盘: 120GB SSD
- 数据盘: 960GB SSD
- 系统: Win10/Linux
- 其他: 独立IP,100M-1G带宽
- 独显: Nvidia Quadro T1000
- 显存: 8GB GDDR6
- CUDA核心: 896
- 单精度浮点: 2.5 TFLOPS
春季特惠
GPU云服务器 - A4000
¥ 692.45/月
立省45% (原价¥1259.00)
月付季付年付两年付
立即订购- 配置: 24核32GB, 独立IP
- 存储: 320GB SSD系统盘
- 带宽: 300Mbps 不限流
- 赠送: 每2周一次自动备份
- 系统: Win10/Linux
- 其他: 1个独立IP
- 独显: Nvidia RTX A4000
- 显存: 16GB GDDR6
- CUDA核心: 6144
- 单精度浮点: 19.2 TFLOPS
结论:针对 GPU 服务器优化 Ollama
这项基准测试表明,即使在内存受限的情况下,Ollama 也能有效利用基于 Pascal 的 Nvidia Quadro P1000 GPU。虽然这类服务器不是为高端数据中心应用而设计的,但它为测试、开发和小规模 LLM 部署提供了实用的解决方案。
如果您考虑在类似硬件上部署 Ollama,请确保量化设置正确并监控 GPU 利用率以最大化吞吐量。对于较大的模型或生产用途,升级到具有更高内存容量(例如 8GB 或 16GB)的 GPU 将提供更好的性能。
标签:
Ollama GPU 性能、Ollama LLM 基准测试、在 P1000 GPU 上运行大型语言模型、Nvidia GPU 的 Ollama 测试结果