
Ollama 基准测试:在 Nvidia T1000 GPU 服务器上运行 LLM 的性能
随着大型语言模型 (LLM) 的普及,越来越多的开发者和研究人员希望在本地或云服务器上运行这些模型。Quadro T1000 搭载 P1000 的 Turing 微架构和 8GB GDDR6 GPU 显存,可提供 2.5 TFLOPS 的 FP32 性能,使其成为 AI 工作负载的理想之选。在本文中,我们将利用 Nvidia Quadro T1000 GPU,对在 Ollama 平台上运行的各种 LLM 的性能进行基准测试。
硬件概述:GPU专用服务器 - T1000
测试的美国服务器配置信息如下:
服务器配置:
- 价格:99.00美元/月
- CPU:八核Xeon E5-2690
- 内存:64GB RAM
- 存储:120GB + 960GB SSD
- 网络:100Mbps-1Gbps
- 操作系统:Windows 11 Pro
GPU详细信息:
- 显卡:Nvidia Quadro T1000
- 微架构:图灵
- CUDA核心:896
- 显存:8GB GDDR6
- FP32 性能:2.5 TFLOPS
该配置对于运行Ollama以及类似的大型语言模型有着不错的性价比,尤其是显卡Nvidia Quadro T1000在计算密集型任务上的表现值得探讨。
测试了几个主流的 LLMs
所有模型均通过 Ollama 运行,使用命令 ollama run 'model',并量化为 4 位以减少虚拟内存使用。
- 羊驼2 (7B)
- 骆驼3.1 (8B)
- 米斯特拉尔 (7B)
- 杰玛 (7B, 9B)
- 拉瓦 (7B)
- 巫师LM2 (7B)
- 奎文(4B,7B)
- Nemotron-Mini (4B)
基准测试结果:Ollama GPU T1000 性能指标
以下是在 Nvidia T1000 GPU 上运行模型时获得的基准测试结果:
| 模型 | llama2 | llama3.1 | mistral | gemma | gemma2 | llava | wizardlm2 | qwen | qwen2 | qwen2.5 | nemotron-mini |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 参数 | 7b | 8b | 7b | 7b | 9b | 7b | 7b | 4b | 7b | 7b | 4b |
| 大小(GB) | 3.8 | 4.9 | 4.1 | 5.0 | 5.4 | 4.7 | 4.1 | 2.3 | 4.4 | 4.7 | 2.7 |
| 量化 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| 正在运行 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 |
| 下载速度(mb/s) | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 |
| CPU 速率 | 8% | 8% | 7% | 23% | 20% | 8% | 8% | 6% | 8% | 8% | 9% |
| 内存速率 | 8% | 7% | 7% | 9% | 9% | 7% | 7% | 8% | 8% | 8% | 8% |
| GPU 虚拟内存 | 63% | 80% | 71% | 81% | 83% | 79% | 70% | 72% | 65% | 65% | 50% |
| GPU 执行时间 | 98% | 98% | 97% | 90% | 96% | 98% | 98% | 95% | 96% | 99% | 97% |
| 评估率(令牌/秒) | 26.55 | 21.51 | 23.79 | 15.78 | 12.83 | 26.70 | 17.51 | 37.64 | 24.02 | 21.08 | 34.91 |
记录实时gpu服务器资源消耗数据:
屏幕截图:点击放大查看
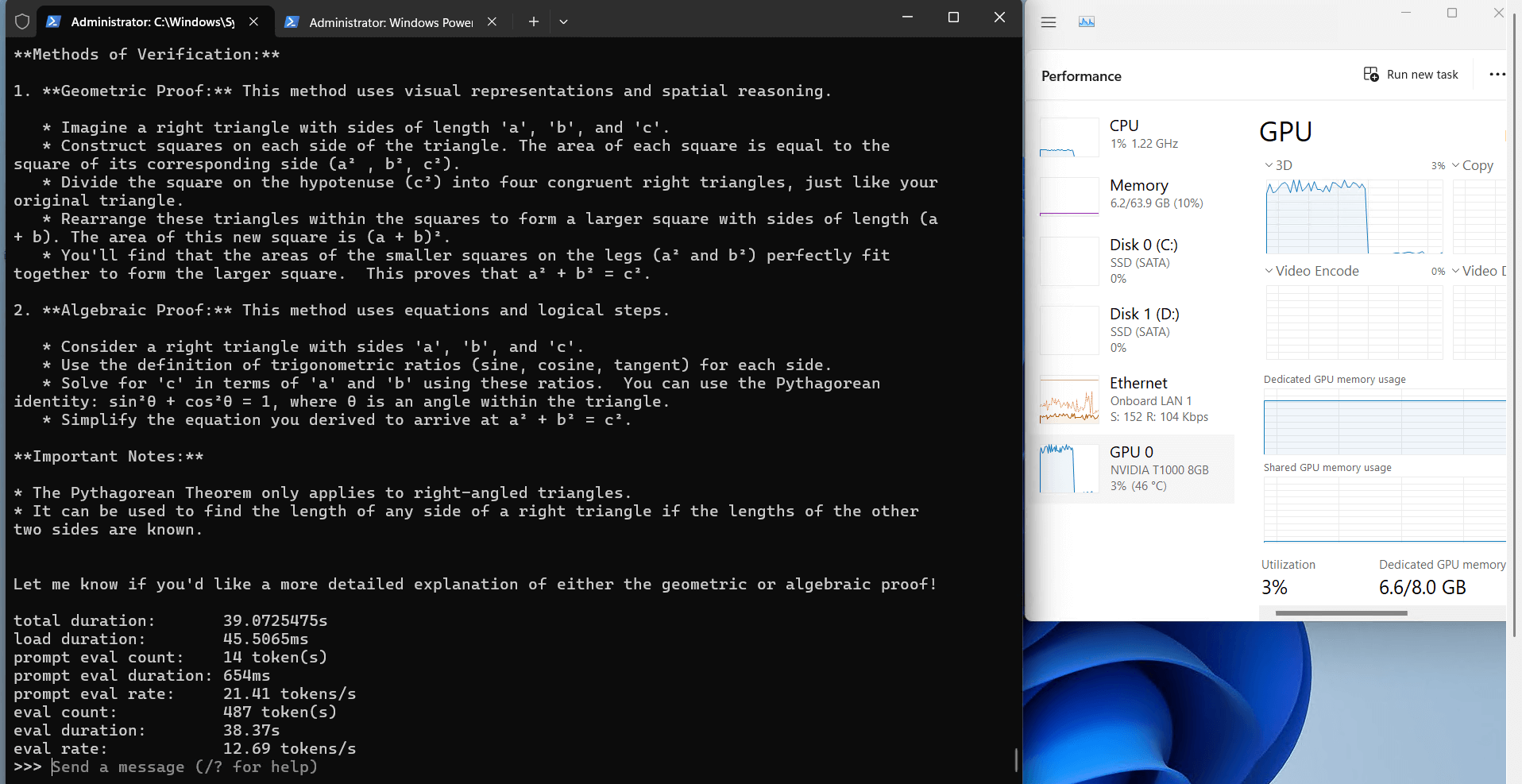
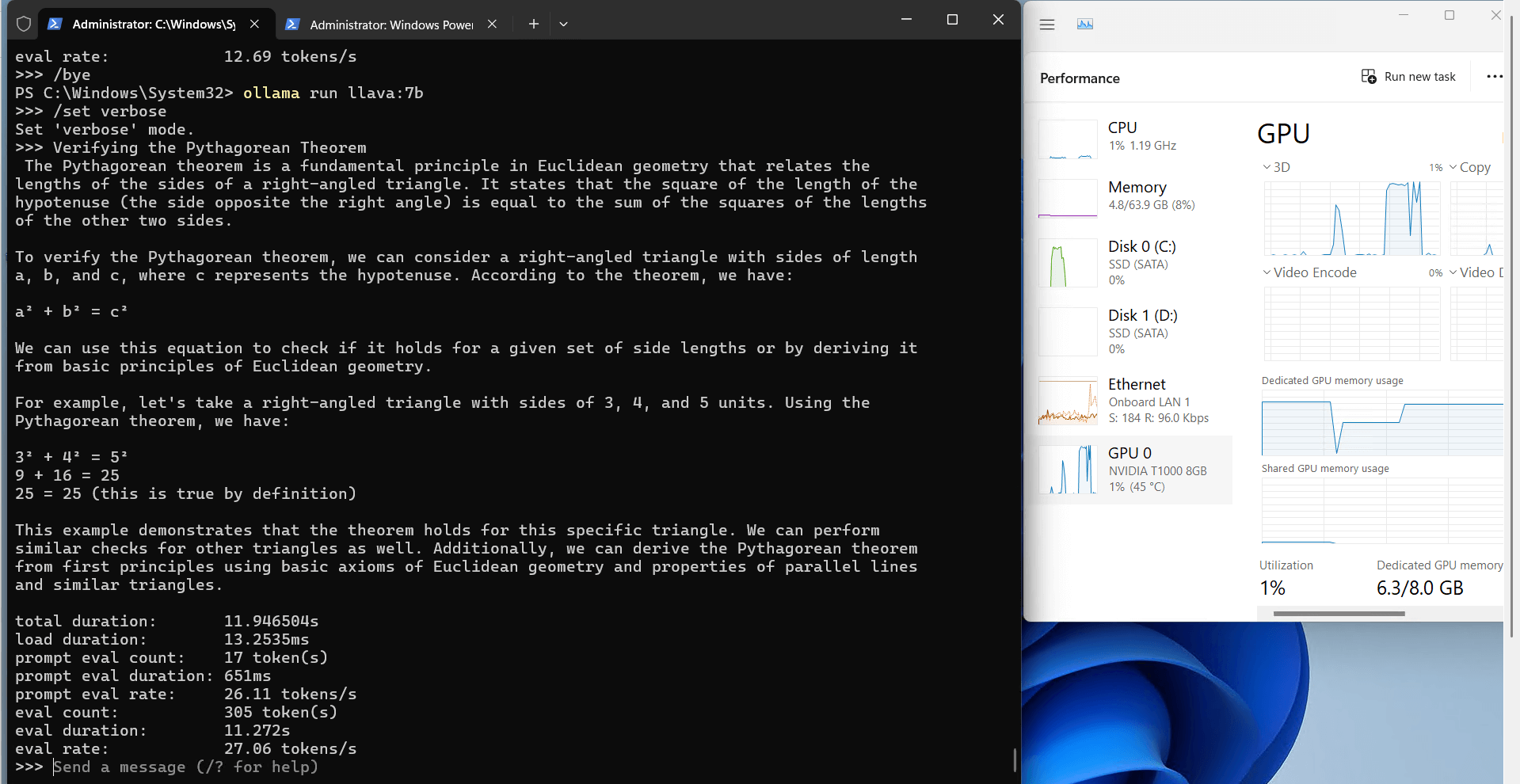
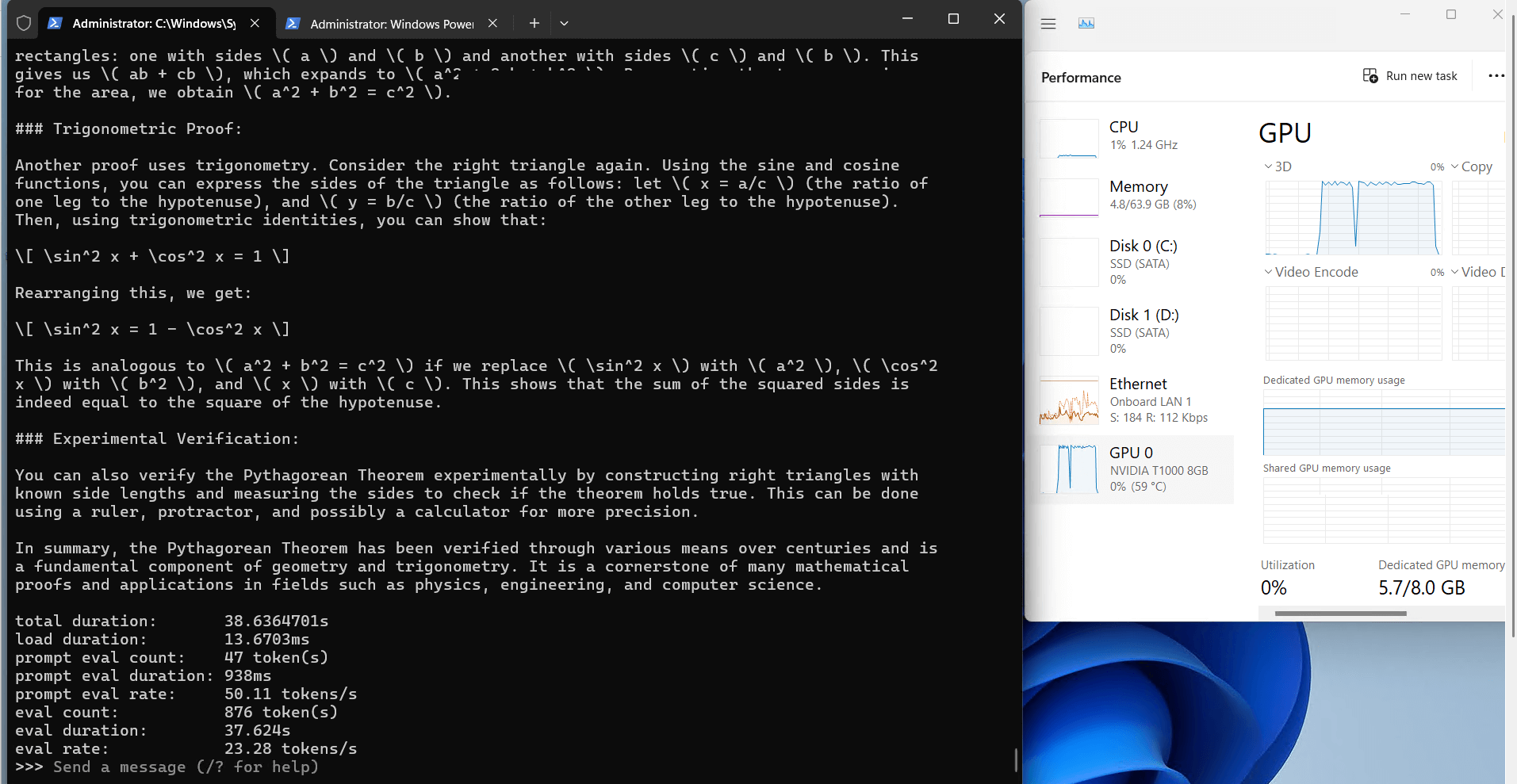
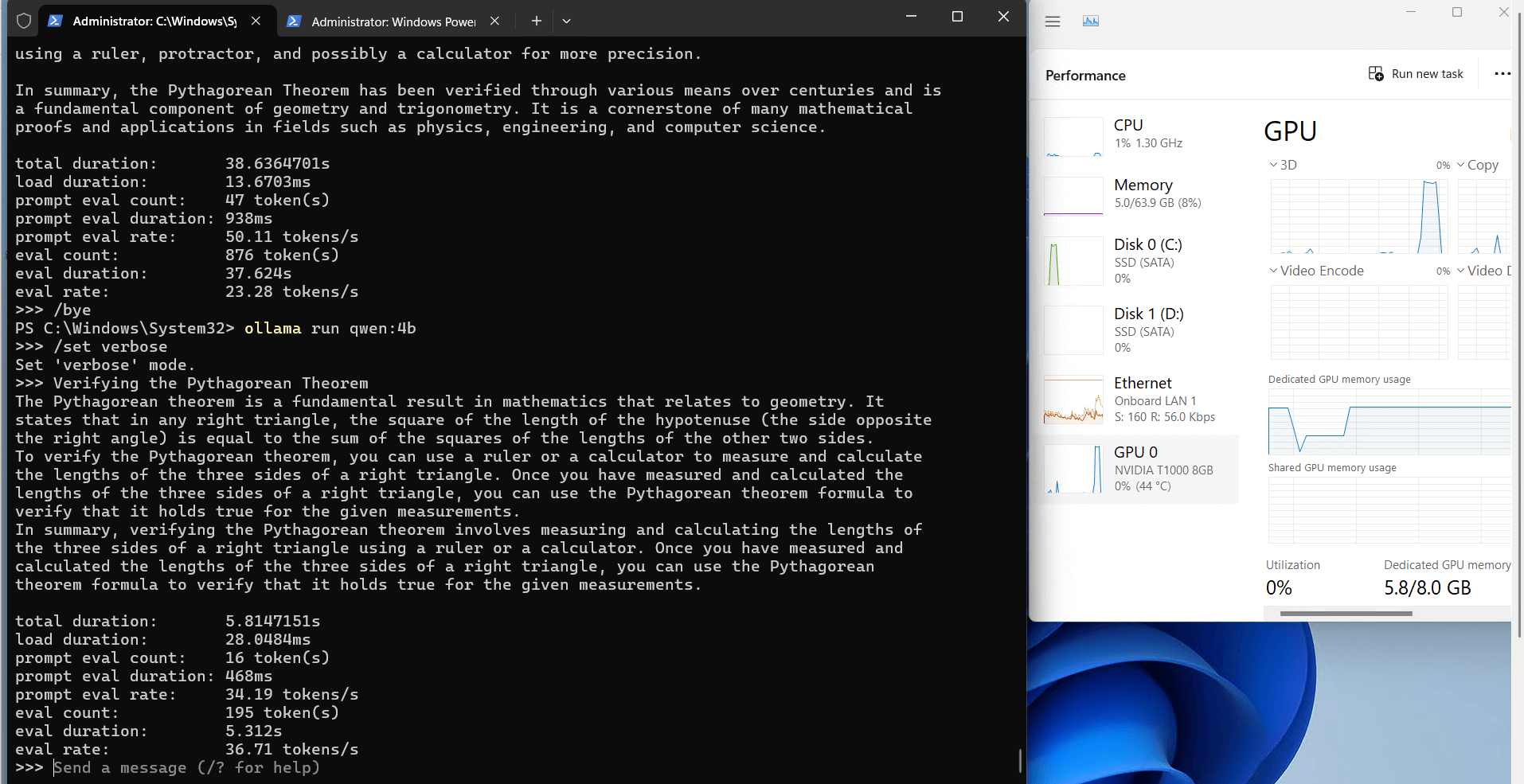
Ollama 对 Nvidia T1000 的性能分析
1. 8GB 视频
T1000 的显存对于 4 位量化模型有很好的表现,甚至可以运行更大的模型(比如 9B 参数的 Gemma2)。相比消费级显卡,T1000 可以更高效地分配显存,减少溢出问题。
2.计算效率
T1000 的 FP32 性能(2.5 TFLOPS)适合 LLM 推理任务,但对于训练模型来说可能略显不足。在运行较小的模型(例如 Qwen 4B)时,其性能几乎接近满载。
3.资源利用
Ollama 在 T1000 上的 CPU 和 RAM 利用率非常低(7%-9%),这使得服务器可用于并行任务,例如同时运行其他服务或工具。
4.速度性能
Qwen 4B和Llama2 7B的评测速度分别为37.64 token/s和26.55 token/s,在同价位显卡中属于优秀水平。
| 公制 | 各种型号的价值 |
|---|---|
| 下载速度 | 所有型号均为 11 MB/s,订购 1gbps 带宽附加组件时为 118 MB/s |
| CPU利用率 | 平均 8% |
| RAM利用率 | 平均 7-9% |
| GPU vRAM 利用率 | 63%-83% |
| GPU利用率 | 95%-99% |
| 评估速度 | 12.83 - 37.64 tokens/秒 |
与其他显卡的比较
与更高端的显卡(例如 RTX 3060 或 A100)相比,T1000 的性能明显逊色,但其低功耗和稳定性是很大的优势。对于预算有限的开发者来说,T1000 是一个理想的选择,尤其是对于运行 Ollama 的 4 位模型量化而言。
GPU物理服务器 - T1000
¥ 739.00/月
月付季付年付两年付
立即订购- CPU: 8核E5-2690
- 内存: 64GB DDR3
- 系统盘: 120GB SSD
- 数据盘: 960GB SSD
- 系统: Win10/Linux
- 其他: 独立IP,100M-1G带宽
- 独显: Nvidia Quadro T1000
- 显存: 8GB GDDR6
- CUDA核心: 896
- 单精度浮点: 2.5 TFLOPS
GPU物理服务器 - GTX 1660
¥ 989.00/月
月付季付年付两年付
立即订购- CPU: 16核E5-2660*2
- 内存: 64GB DDR3
- 系统盘: 120GB SSD
- 数据盘: 960GB SSD
- 系统: Win10/Linux
- 其他: 独立IP,100M-1G带宽
- 独显: Nvidia GTX 1660
- 显存: 6GB GDDR6
- CUDA核心: 1408
- 单精度浮点: 5.0 TFLOPS
春季特惠
GPU物理服务器 - RTX 3060 Ti
¥ 789.13/月
立省53% (原价¥1679.00)
月付季付年付两年付
立即订购- CPU: 24核E5-2697v2*2
- 内存: 128GB DDR3
- 系统盘: 240GB SSD
- 数据盘: 2TB SSD
- 系统: Win10/Linux
- 其他: 独立IP,100M-1G带宽
- 独显:RTX 3060 Ti
- 显存: 8GB GDDR6
- CUDA核心: 4864
- 单精度浮点: 16.2 TFLOPS
总结和建议
这篇评测表明,Nvidia Quadro T1000 是运行 Ollama 最具成本效益的 GPU 之一,尤其适合以下场景:
- 运行小型和中型大型语言模型(4B-9B 参数)。
- 开发人员希望以低功耗测试 LLM 的推理能力。
- 预算有限,但需要高性能 GPU 专用服务器。
如果您正在寻找一款可靠且价格实惠的显卡来运行 Ollama,不妨试试 GPU 专用服务器 - T1000。对于更复杂的训练任务,您可能需要更高端的 GPU,但在推理任务中,T1000 的性能足够令人满意。
希望本文能帮助您更好地了解 Nvidia T1000 基准测试和 Ollama 基准测试的实际性能!
标签:
Ollama GPU 性能、Ollama 基准、Nvidia T1000 基准、Nvidia Quadro T1000 基准、Ollama T1000、GPU 专用服务器 T1000、Ollama 测试、Llama2 基准、Qwen 基准、T1000 AI 性能、T1000 LLM 测试、Nvidia T1000 AI 任务、在 T1000 上运行 LLM、适合 LLM 的经济实惠的 GPU。