视频: 基于vLLM 使用H100离线推理Hugging Face LLMs

H100 vLLM 基准测试结果: 离线与在线测试Hugging Face上的大语言模型
本文基于 NVIDIA H100 80GB GPU 和 vLLM 后端,对 Hugging Face 上的多个大语言模型进行了离线与在线推理性能测试。测试涵盖了不同模型规模、输入输出长度以及请求数量的组合。以下是对测试结果的详细分析,旨在为使用 H100 服务器进行大语言模型推理的用户提供有价值的参考。
H100 GPU详细信息
- GPU:英伟达H100
- 微架构:Hopper
- 计算能力:9.0
- CUDA核心:14592
- 张量核心:456
- 内存:80GB HBM2e
- FP32性能:183 TFLOPS
一. 测试概述
1. 测试项目代码来源:
- 我们使用了该git项目搭建环境(https://github.com/vllm-project/vllm)。
2. 测试了Hugging Face上的如下模型:
- google/gemma-2-9b-it
- google/gemma-2-27b-it
- deepseek-ai/DeepSeek-R1-Distill-Llama-8B
- deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
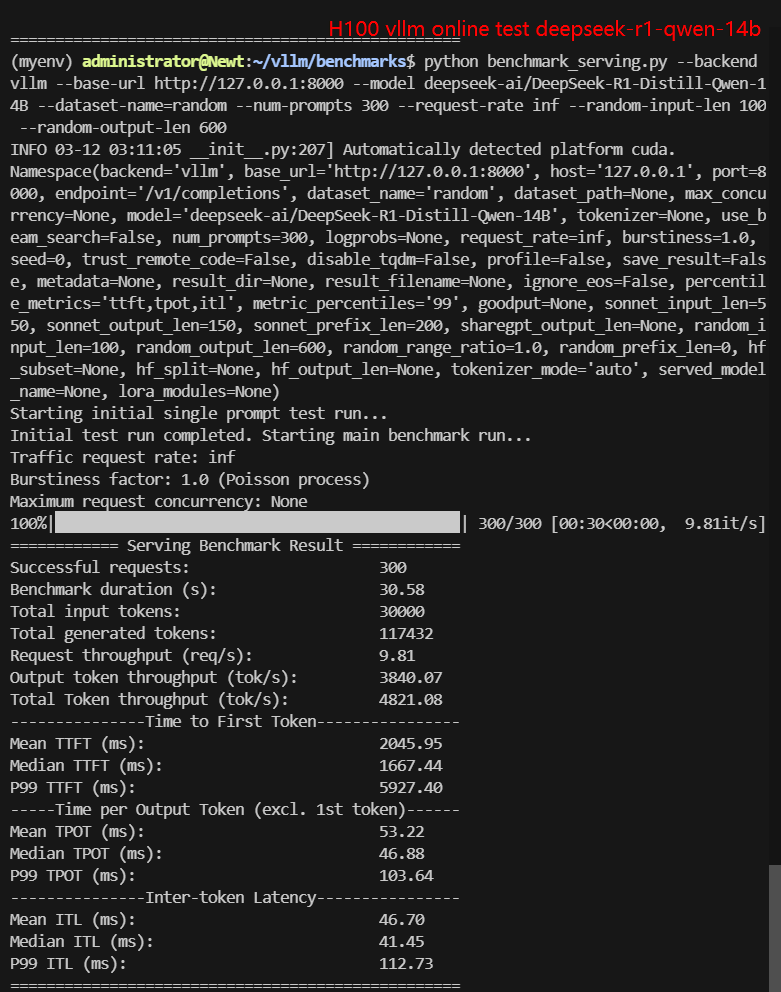
- deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
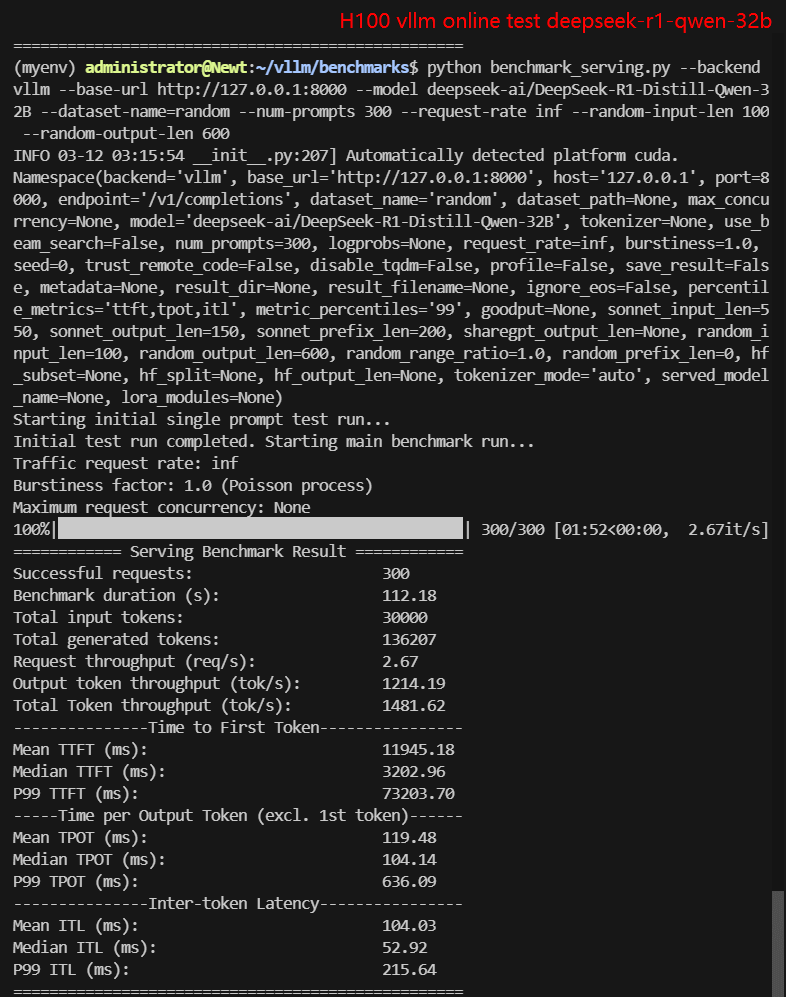
- deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
3. 测试参数预设为:
- 输入长度(Input length): 100 tokens
- 输出长度(Output length): 600 tokens
- 请求数量(Request Numbers): 300个
4. 测试分为两种模式:
- 离线测试: 使用 benchmark_throughput.py 脚本。
- 在线测试: 使用 benchmark_serving.py 脚本,模拟真实客户端请求。
二、测试结果数据展示
1. 离线测试结果:
| 模型 | gemma-2-9b-it | gemma-2-27b-it | DeepSeek-R1-Distill-Llama-8B | DeepSeek-R1-Distill-Qwen-7B | DeepSeek-R1-Distill-Qwen-14B | DeepSeek-R1-Distill-Qwen-32B |
|---|---|---|---|---|---|---|
| 量化 | 16 | 16 | 16 | 16 | 16 | 16 |
| 大小(GB) | 18.5GB | 54.5GB | 16.1GB | 15.2GB | 29.5GB | 65.5GB |
| 后端/平台 | vLLM | vLLM | vLLM | vLLM | vLLM | vLLM |
| CPU 使用率 | 1.4% | 1.4% | 1.5% | 1.4% | 1.4% | 1.4% |
| RAM 使用率 | 5.5% | 5.8% | 4.8% | 5.7% | 5.8% | 4.8% |
| GPU RAM使用率 | 90% | 91.4% | 90.3% | 90.3% | 90.2% | 91.5% |
| GPU 利用率 | 80-86% | 88-94% | 80-82% | 80% | 72-87% | 91-92% |
| 每秒请求数量 (req/s) | 5.99 | 2.62 | 9.27 | 10.45 | 6.15 | 1.99 |
| 时长 | 49s | 1min54s | 32s | 28s | 48s | 2min30s |
| 输入 (tokens/s) | 599.06 | 262.45 | 926.91 | 1044.98 | 614.86 | 198.66 |
| 输出 (tokens/s) | 3594.38 | 1574.67 | 5561.45 | 6269.87 | 3689.21 | 1191.95 |
| 总吞吐量 (tokens/s) | 4193.44 | 1837.12 | 6488.36 | 7314.85 | 4304.07 | 1390.61 |
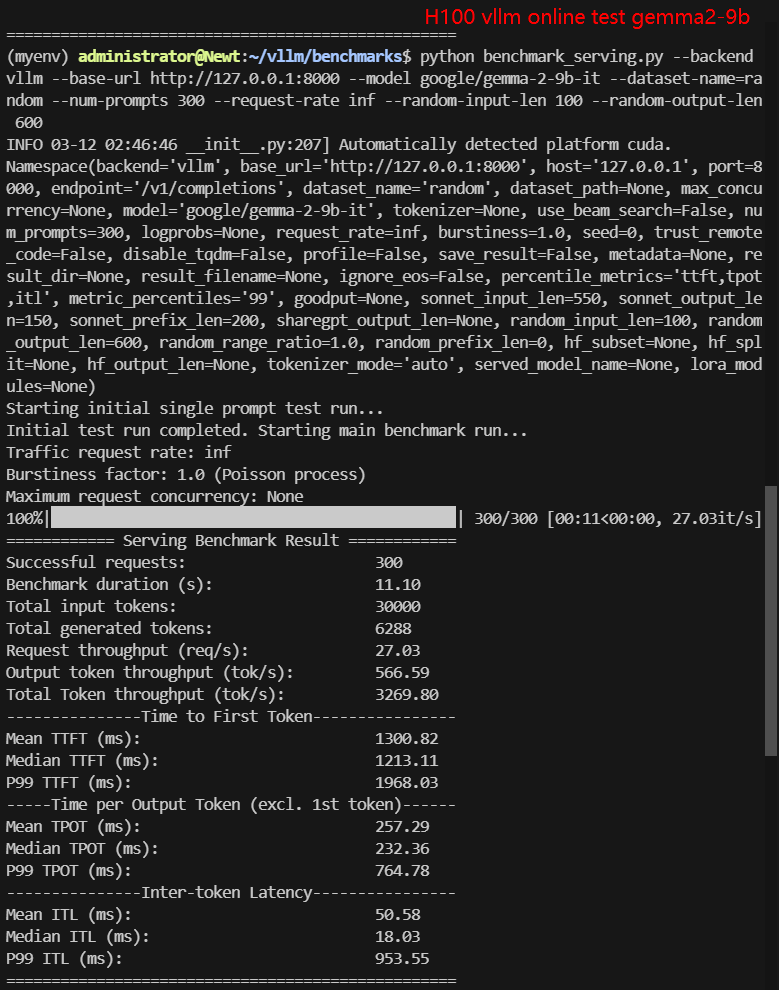
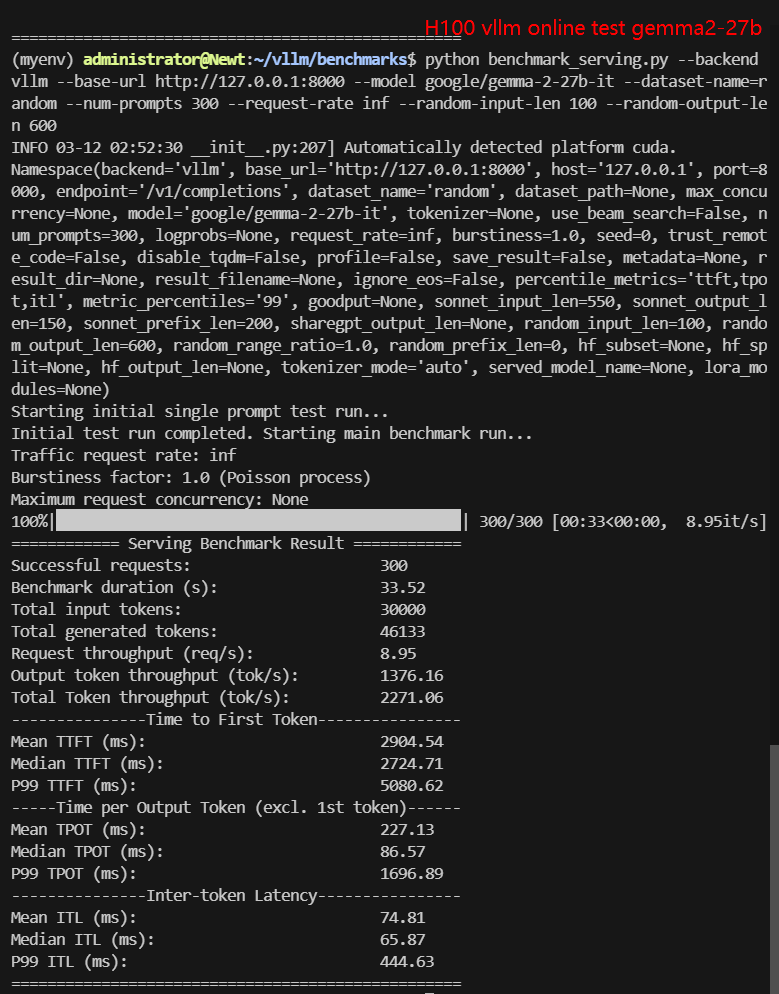
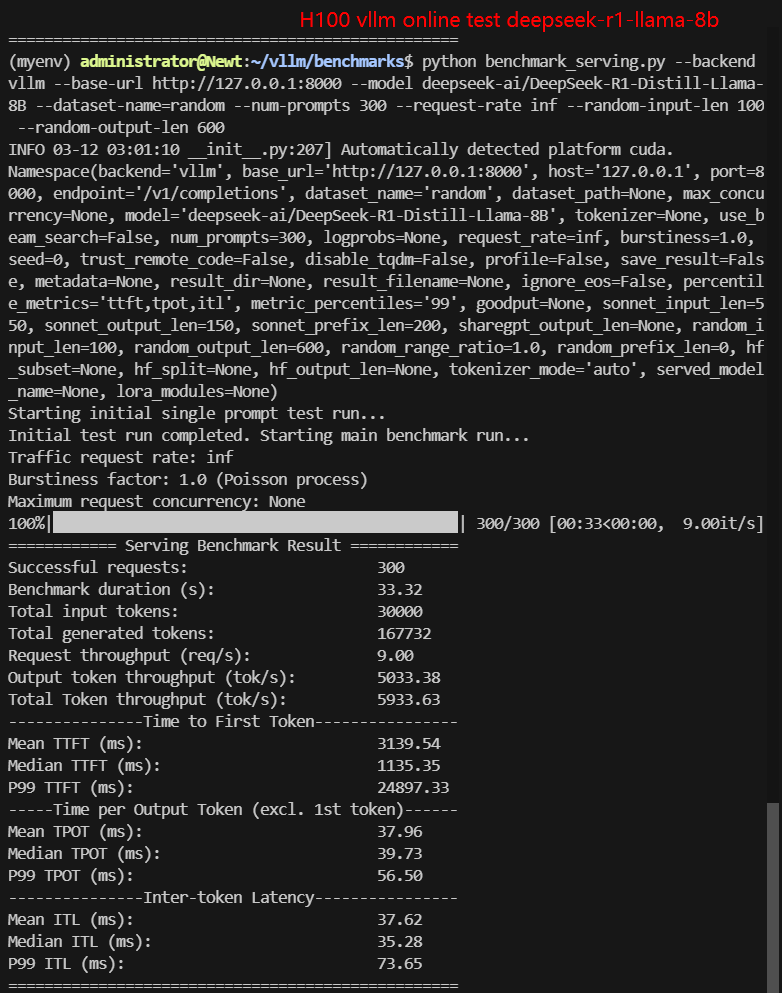
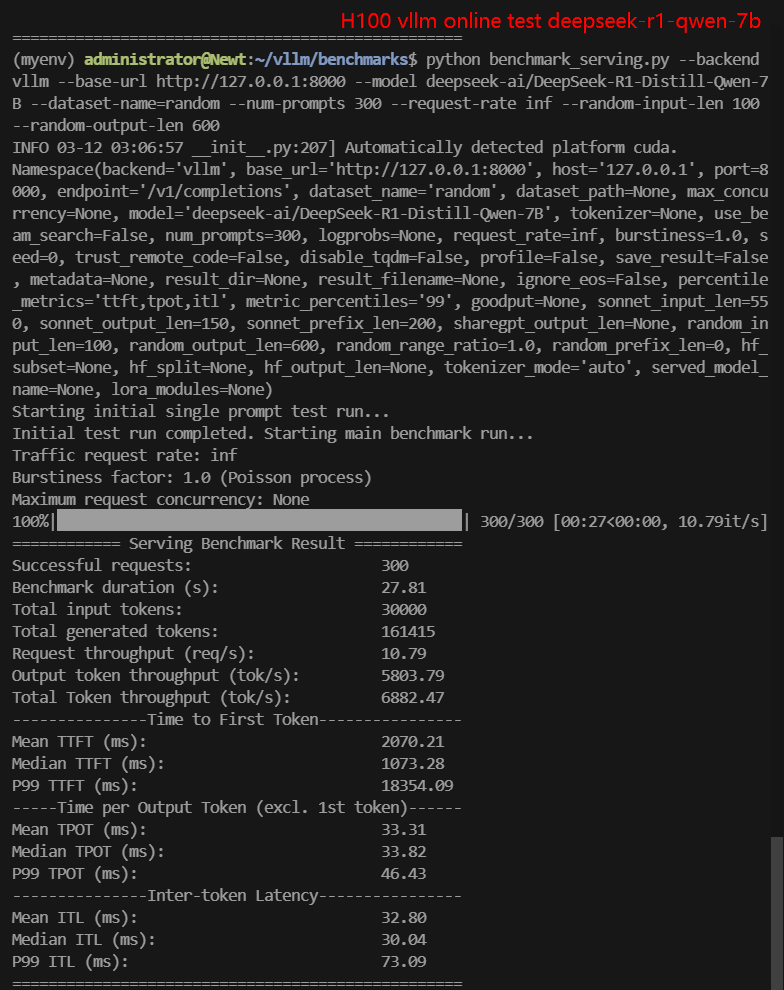
2. 在线测试结果:
| 模型 | gemma-2-9b-it | gemma-2-27b-it | DeepSeek-R1-Distill-Llama-8B | DeepSeek-R1-Distill-Qwen-7B | DeepSeek-R1-Distill-Qwen-14B | DeepSeek-R1-Distill-Qwen-32B |
|---|---|---|---|---|---|---|
| 量化 | 16 | 16 | 16 | 16 | 16 | 16 |
| 大小(GB) | 18.5GB | 54.5GB | 16.1GB | 15.2GB | 29.5GB | 65.5GB |
| 后端/平台 | vLLM | vLLM | vLLM | vLLM | vLLM | vLLM |
| CPU 使用率 | 1.4% | 1.4% | 2.8% | 3% | 2.5% | 2.0% |
| RAM 使用率 | 13.9% | 15.4% | 11.5% | 18% | 15.9% | 11.8% |
| GPU RAM使用率 | 90.2% | 90.9% | 90.2% | 90.3% | 90% | 90.3% |
| GPU 利用率 | 93% | 86%-96% | 83%-85% | 50%-91% | 80-90% | 92%-96% |
| 每秒请求数量 (req/s) | 27.03 | 8.95 | 8.80 | 10.79 | 9.81 | 2.67 |
| 时长 | 11s | 33s | 33s | 27s | 30s | 1min52s |
| 输入 (tokens/s) | 2703.21 | 894.9 | 900.25 | 1078.68 | 981.01 | 267.43 |
| 输出 (tokens/s) | 566.59 | 1376.16 | 5033.38 | 5803.79 | 3840.07 | 1214.19 |
| 总吞吐量 (tokens/s) | 3269.80 | 2271.06 | 5933.63 | 6882.47 | 4821.08 | 1481.62 |
3. 数据项解释:
以下是表格中各数据项的含义:
- Quantization: 量化位数,本次测试均为 16 位, 满血版模型。
- Size (GB): 模型大小,单位为 GB。
- Backend: 使用的推理后端,本次测试均为 vLLM。
- CPU Rate: CPU 使用率。
- RAM Rate: 内存使用率。
- GPU vRAM: GPU 显存使用率。
- GPU UTL: GPU 利用率。
- Request Numbers: 请求数量。
- Request (req/s): 每秒处理的请求数量。
- Total Duration: 完成所有请求的总时间。
- Input (tokens/s): 每秒处理的输入 tokens 数量。
- Output (tokens/s): 每秒生成的输出 tokens 数量。
- Total Throughput (tokens/s): 每秒处理的总 tokens 数量(输入 + 输出)。
三、测试结果解读
1. 离线测试:
- 模型规模(Size)对性能的影响:模型规模越小,请求吞吐量和总吞吐量越高。7B 和 8B 模型的性能显著优于 14B 和 32B 模型。
- GPU 利用率(GPU UTL): 模型规模越大,GPU 利用率越高。32B 模型的 GPU 利用率接近满载。
- 显存使用(GPU vRAM):所有测试中,GPU 显存使用率均接近 90%,表明显存接近满载。
2. 在线测试:
- 模型规模(Size)对性能的影响:在线测试中,7B 和 8B 模型的性能仍然显著优于 14B 和 32B 模型。
- GPU 利用率(GPU UTL): 在线测试中,GPU 利用率普遍较高,尤其是较大模型。
- 显存使用(GPU vRAM):所有测试中,GPU 显存使用率均接近 90%,表明显存接近满载。
结论: 模型越大,对GPU的要求越高,显存是性能的主要瓶颈之一,尤其是在处理较大模型时。
四、离线测试与在线测试
从测试结果中可以看到,在参数设定为一样的情况下,在线测试的请求吞吐量(req/s)和总吞吐量(tokens/s)普遍高于离线测试。以下是可能的原因:
1. 离线测试与在线测试的区别
离线测试:
- 使用 benchmark_throughput.py 脚本,模拟批量请求。
- 通常是一次性发送所有请求,系统需要同时处理大量请求,可能导致资源竞争和显存压力。
- 更适合评估系统的最大吞吐量和极限性能。
在线测试:
- 使用 benchmark_serving.py 脚本,模拟客户端请求。
- 请求是逐步发送的,系统可以更灵活地分配资源,减少资源竞争。
- 更适合评估系统在实际生产环境中的表现。
2. 在线测试优于离线测试的原因
资源分配更高效:
- 在线测试中,请求是逐步发送的,系统可以根据当前负载动态分配资源(如显存和计算资源)。
- 离线测试中,所有请求一次性发送,系统需要同时处理大量请求,可能导致资源竞争和显存压力,从而降低性能。
显存利用率更优:
- 在线测试中,显存可以更灵活地分配给每个请求,减少显存碎片化。
- 离线测试中,显存可能被大量请求同时占用,导致显存不足或需要频繁重计算(如 PreemptionMode.RECOMPUTE),从而降低性能。
请求处理更平滑:
- 在线测试中,请求是逐步处理的,系统可以更好地平衡计算和 I/O 操作。
- 离线测试中,大量请求同时到达,可能导致计算和 I/O 的瓶颈。
GPU 利用率更高:
- 在线测试中,GPU 利用率通常更稳定,系统可以更好地利用 GPU 的计算能力。
- 离线测试中,GPU 利用率可能因资源竞争而波动,导致性能下降。
因此,在线测试更适合评估系统在实际生产环境中的表现,而离线测试更适合评估系统的极限性能。
五、注意事项与感悟
✅ 测试参数的影响
- 不同的输入输出长度对性能影响很大。较长的序列会增加显存占用和计算复杂度,从而降低吞吐量和增加延迟。用户在实际项目中应根据任务需求调整输入输出长度,以优化性能。
- 请求数量的增加会提高系统的吞吐量,但也可能导致显存不足或资源竞争。用户应根据硬件配置和任务需求调整请求数量,以平衡性能和资源使用。
✅ 模型规模的选择
- 模型规模越大,显存占用和计算需求越高。建议用户根据硬件配置选择合适的模型规模。例如,H100 80GB GPU 适合运行 7B 到 32B 的模型,而 40B以上 模型可能需要多 GPU 并行或更高显存的硬件支持。
- 如果模型大小超过 GPU 显存容量(如 80GB),会导致显存不足,性能显著下降。建议用户在测试和生产环境中避免使用超过硬件显存容量的模型。
✅ 硬件配置的优化
- 显存是性能的主要瓶颈之一。用户应监控显存使用情况,避免显存不足导致的性能下降。可以通过调整 --gpu-memory-utilization 参数来优化显存使用。
- 较高的 GPU 利用率表明硬件资源得到充分利用,但如果利用率接近 100%,可能会导致性能瓶颈。用户应根据测试结果调整模型和参数,以优化 GPU 利用率。
✅ 实际项目中的调整
- 离线测试适合评估系统的极限性能,而在线测试更适合模拟实际生产环境。用户应根据项目需求选择合适的测试模式。
✅ 测试模式的适用性
- 用户在实际项目中应根据任务需求和硬件配置调整测试参数(如输入输出长度、请求数量等),以达到更好的性能。
- 在部署模型时,建议实时监控系统资源使用情况(如显存、GPU 利用率等),及时发现和解决性能瓶颈。
六、附件: 视频记录使用H100基于vLLM推理Hugging Face大语言模型
视频: 基于vLLM 使用H100在线推理Hugging Face LLMs
截屏:H100 vLLM 离线测试结果






截屏:H100 vLLM 在线测试结果
标签:
H100 服务器租用,vllm h100 参数优化,h100 vllm 显存管理,vllm 模型规模选择,h100 大语言模型性能调优,vllm 在线测试 vs 离线测试,h100 服务器性能优化,vllm 生产环境部署,h100 深度学习推理优化