



















在 Ollama 上对 LLM 进行基准测试:Nvidia RTX 4060 GPU 服务器的性能
随着大型语言模型 (LLM) 的持续发展,如何在消费级 GPU 上高效运行它们已成为热门话题。在本基准测试中,我们在专用的 Nvidia RTX 4060 服务器上测试了 Ollama,以评估其在 LLM 推理方面的表现。如果您正在寻找高性能且价格实惠的 LLM 托管解决方案,那么这份 RTX 4060 基准测试将帮助您确定它是否适合您的 AI 工作负载。
测试服务器配置
在深入研究 Ollama 4060 基准测试之前,让我们先来看看服务器规格:
服务器配置:
- 价格:1259.00 元/月
- CPU:Intel 八核 E5-2690
- RAM:64GB
- 存储:120GB SSD + 960GB SSD
- 网络:100Mbps 不限流量
- 操作系统:Windows 11 Pro
GPU 详情:
- GPU:Nvidia GeForce RTX 4060
- 计算能力:8.9
- 微架构:Ada Lovelace
- CUDA 核心:3072
- Tensor 核心:96
- 内存:8GB GDDR6
- FP32 性能:15.11万亿次浮点运算
此设置使 Nvidia RTX 4060 托管成为可行选择,可在控制成本的同时高效运行 LLM 推理工作负载。
Ollama 基准测试:在 NVIDIA RTX4060 服务器上测试 LLM
对于此 Ollama RTX 4060 基准测试,我们使用了最新的 Ollama 0.5.11 运行时并测试了各种流行的 LLM,并使用 4 位量化来优化 8GB VRAM 限制。
| 模型 | deepseek-r1 | deepseek-r1 | deepseek-coder | llama2 | llama3.1 | codellama | mistral | gemma | gemma2 | codegemma | qwen2.5 | codeqwen |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 参数 | 7b | 8b | 6.7b | 13b | 8b | 7b | 7b | 7b | 9b | 7b | 7b | 7b |
| 大小(GB) | 4.7 | 4.9 | 3.8 | 7.4 | 4.9 | 3.8 | 4.1 | 5.0 | 5.4 | 5.0 | 4.7 | 4.2 |
| 量化 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| 运行 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 |
| 下载速度(mb/s) | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 |
| CPU 速率 | 7% | 7% | 8% | 37% | 8% | 7% | 8% | 32% | 30% | 32% | 7% | 9% |
| RAM 速率 | 8% | 8% | 8% | 12% | 8% | 7% | 8% | 9% | 10% | 9% | 8% | 8% |
| GPU UTL | 83% | 81% | 91% | 25-42% | 88% | 92% | 90% | 42% | 44% | 46% | 72% | 93% |
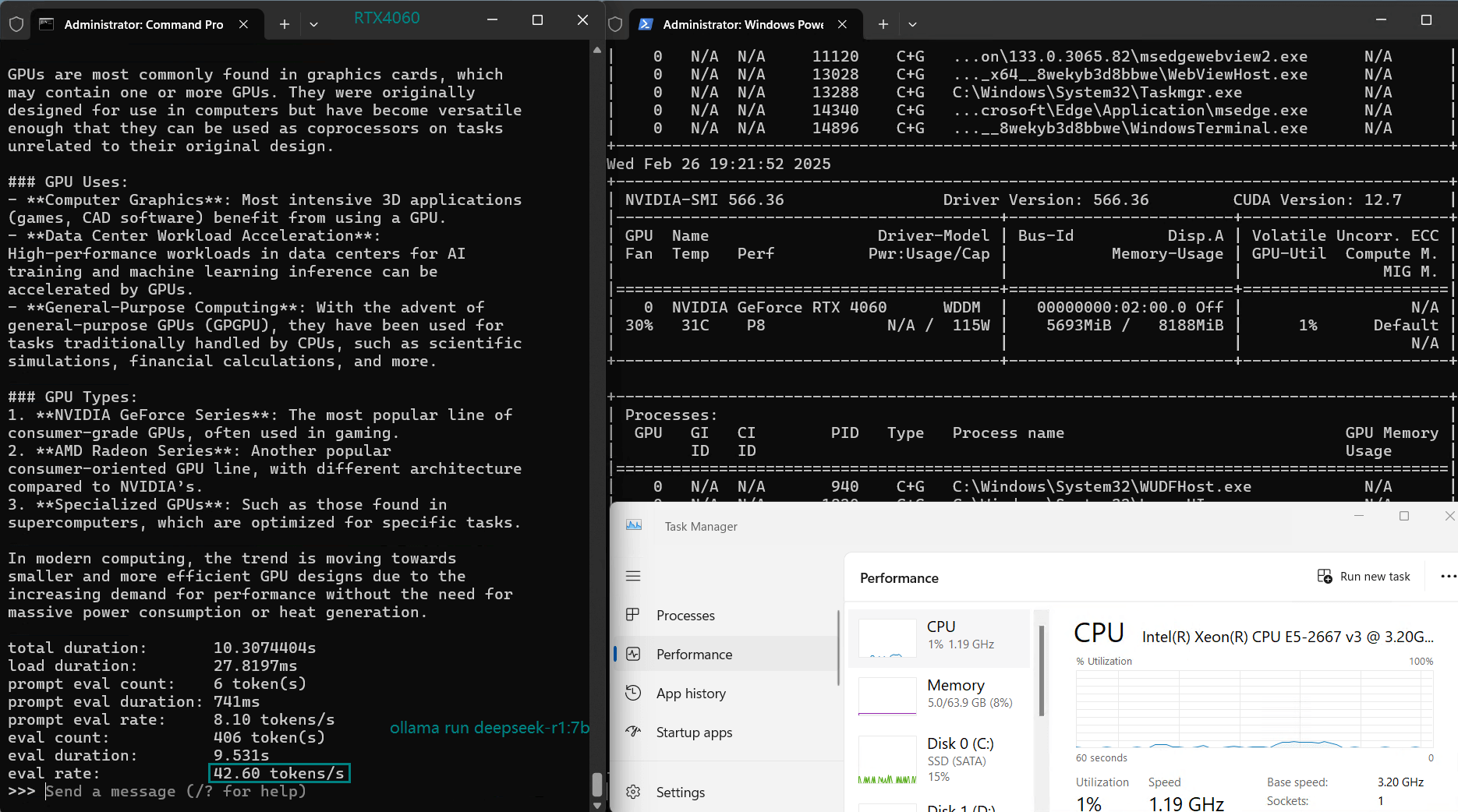
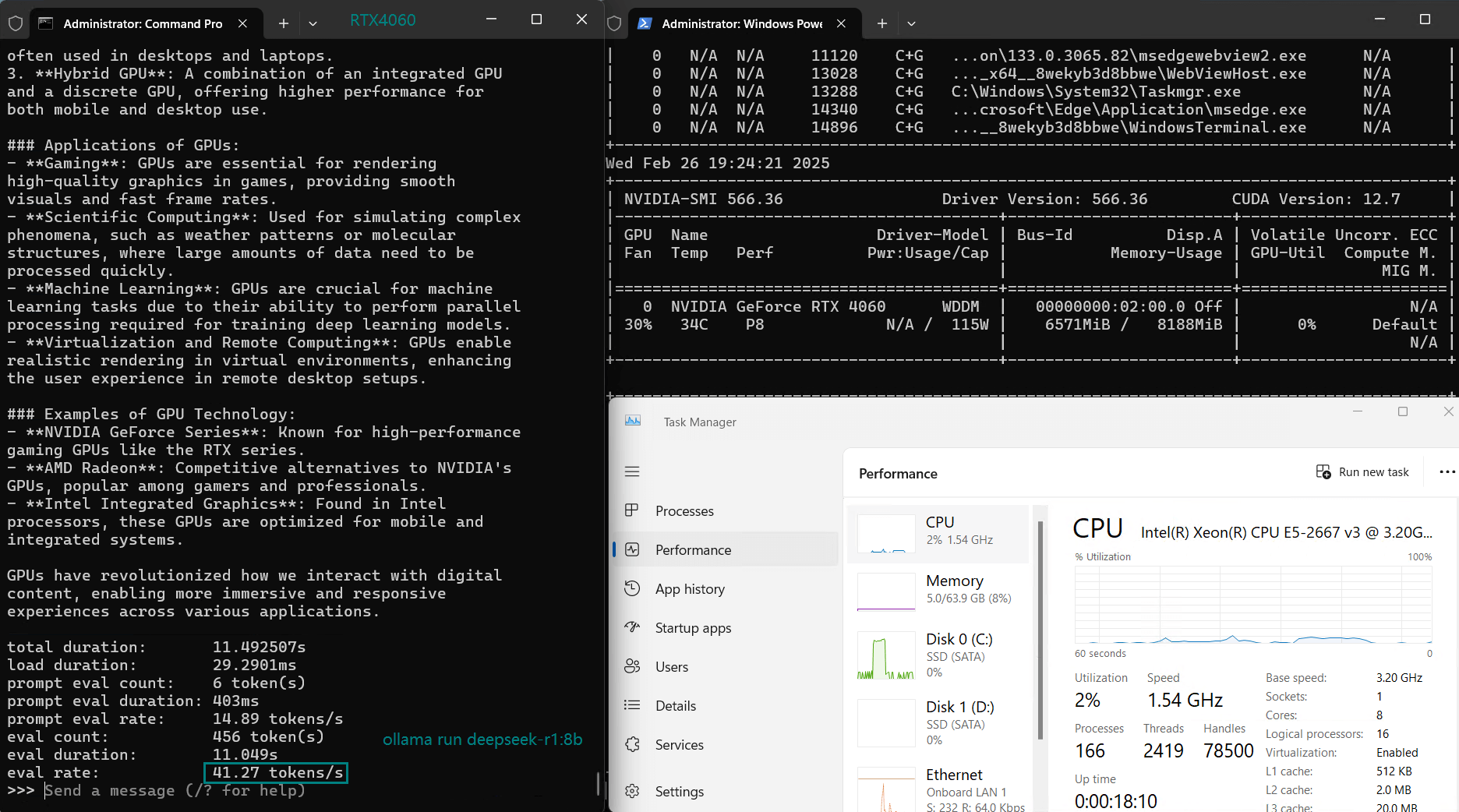
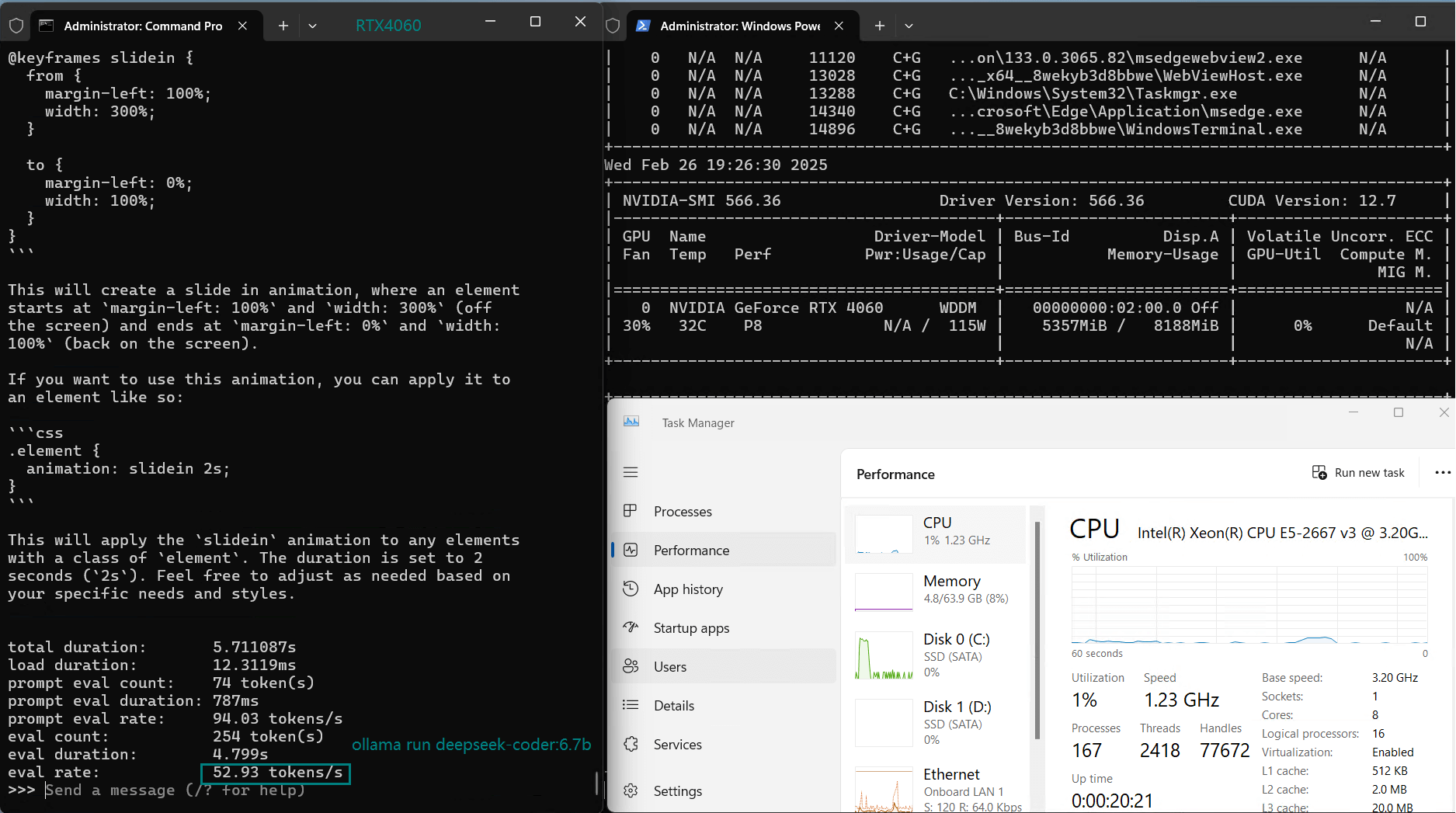
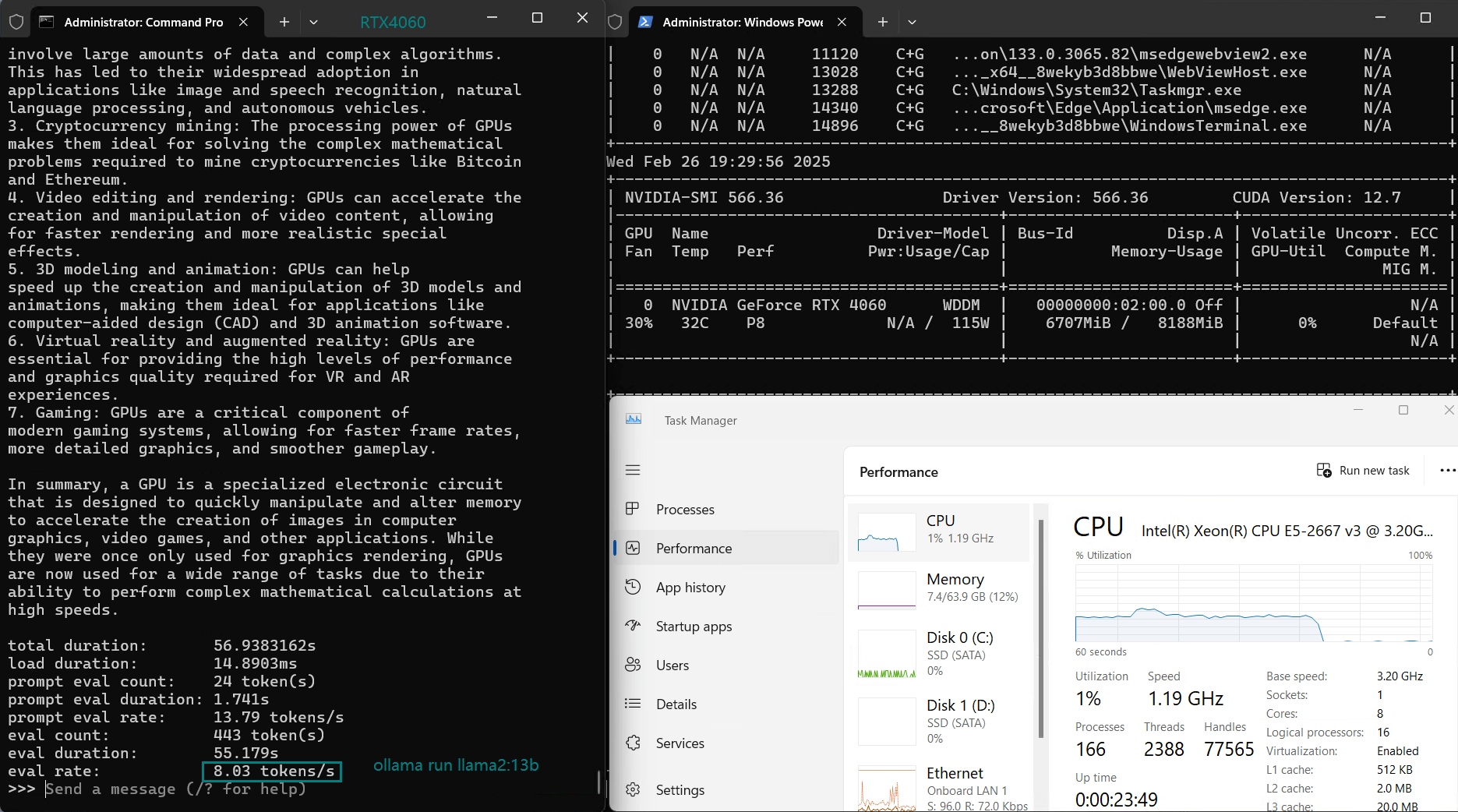
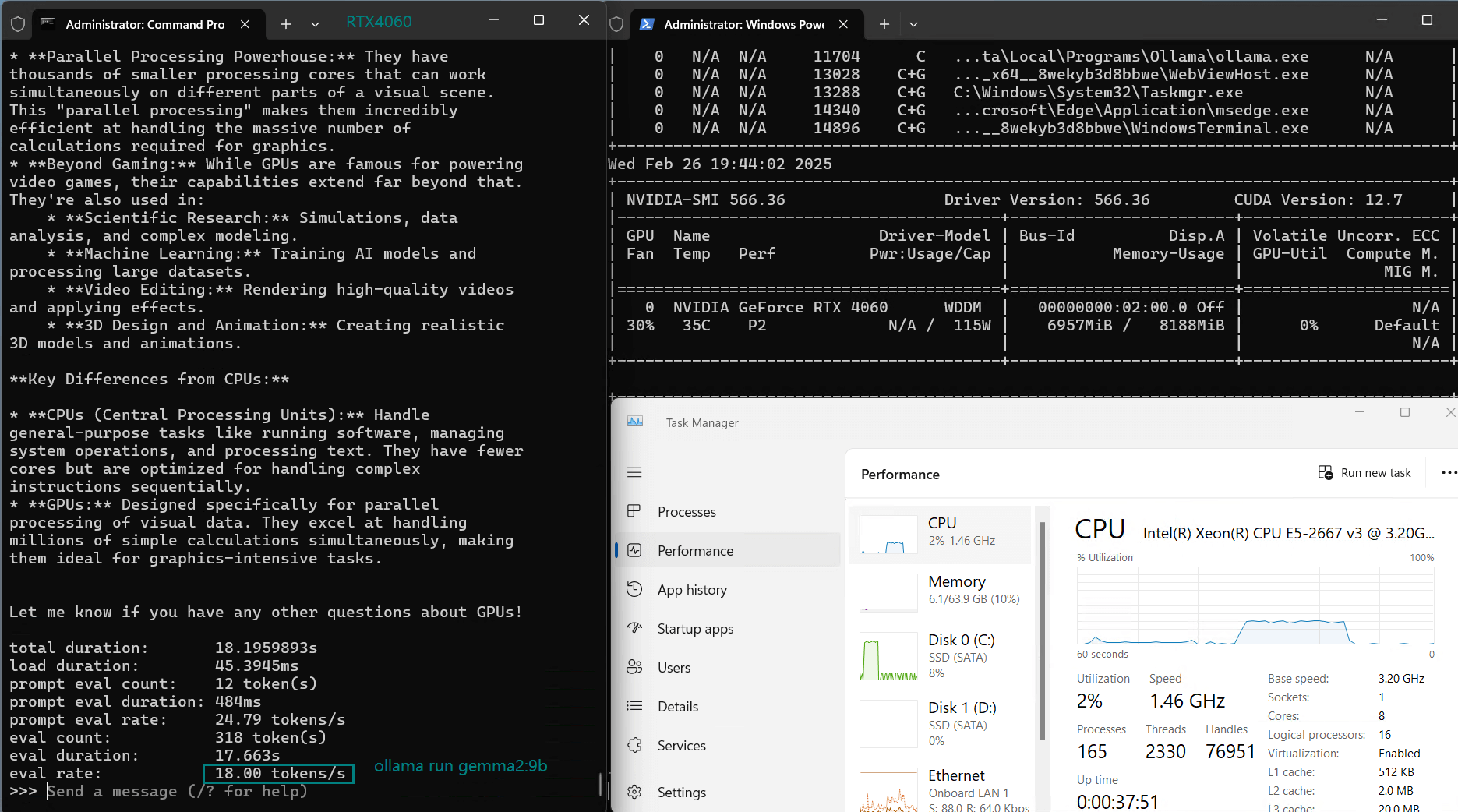
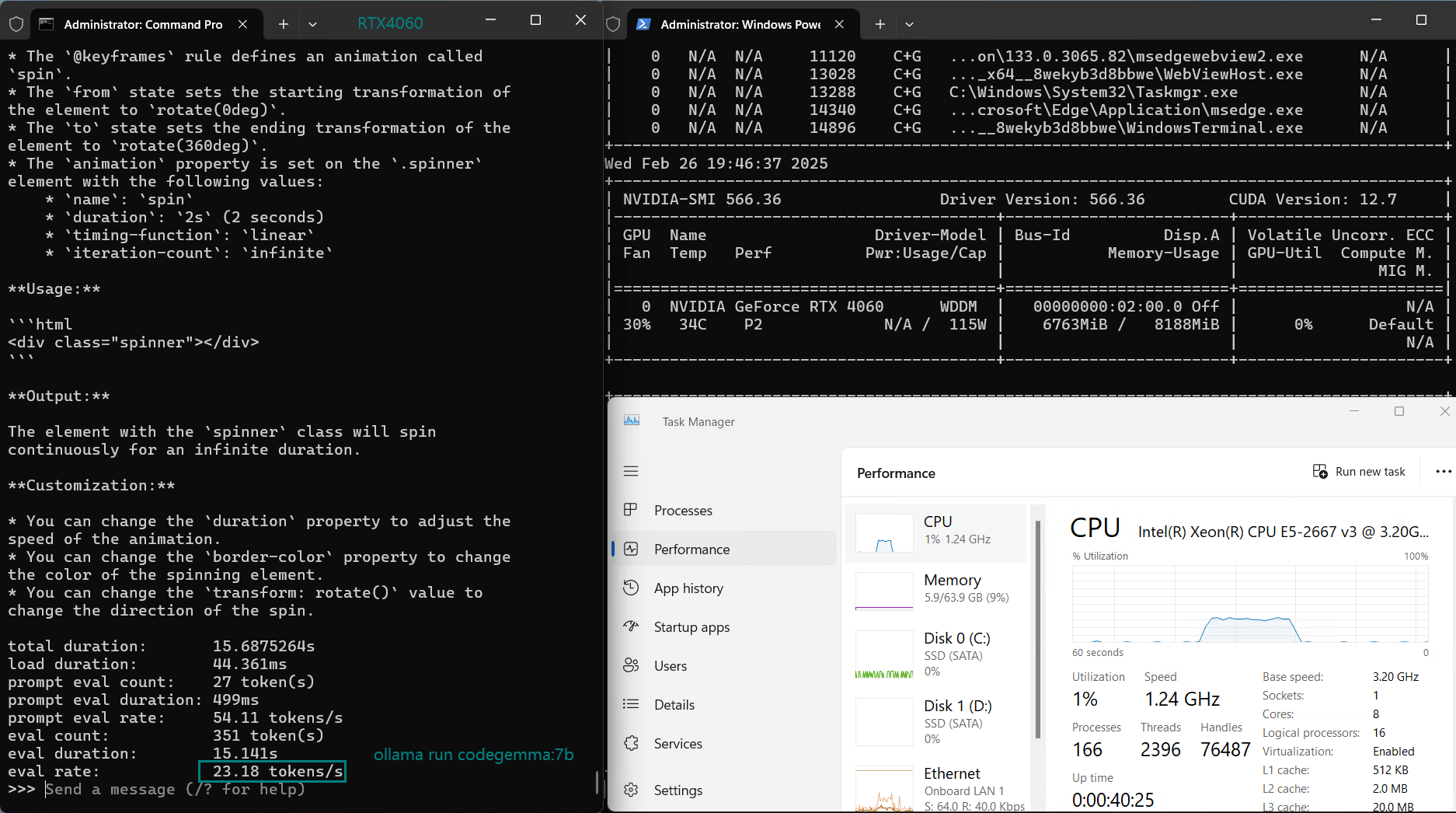
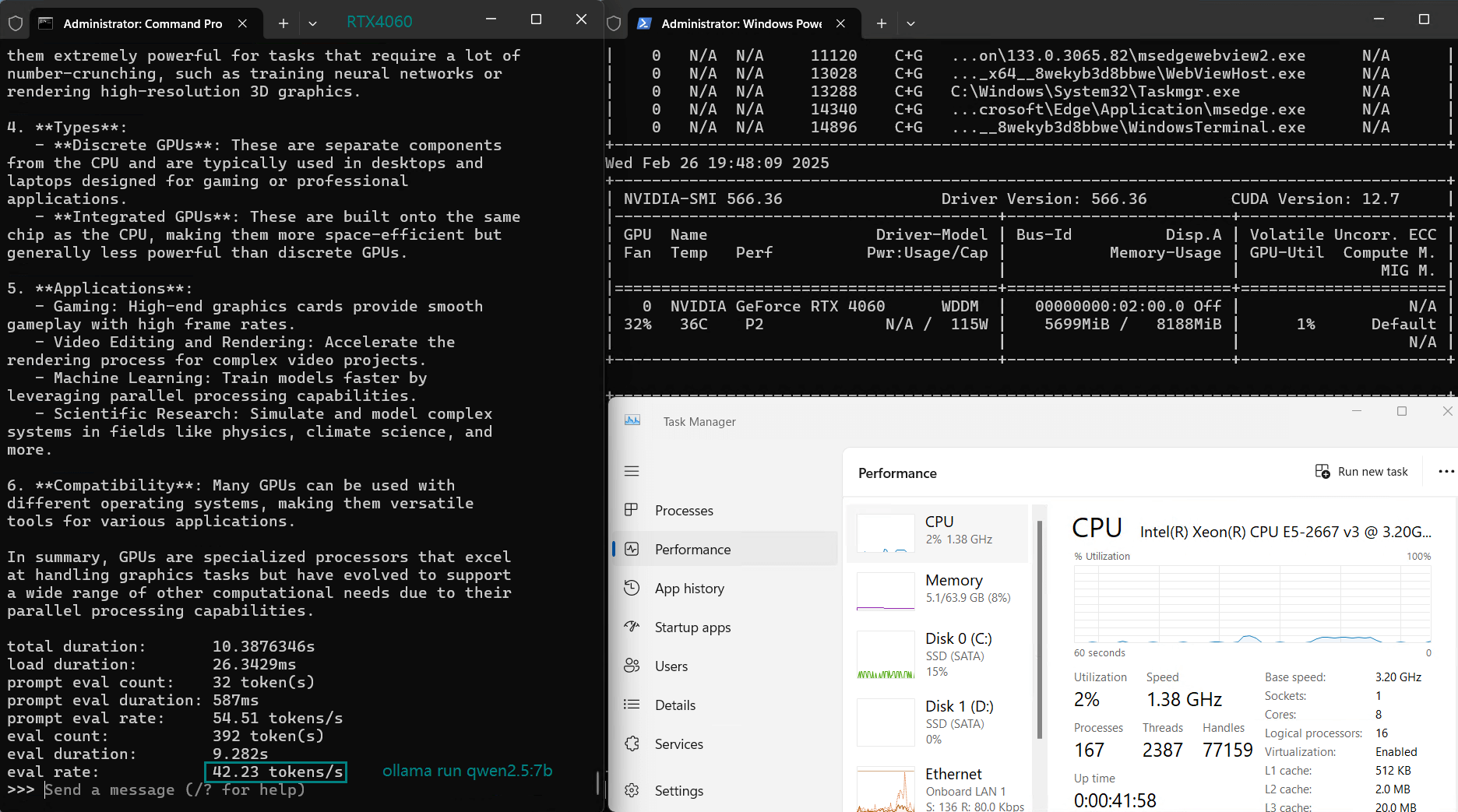
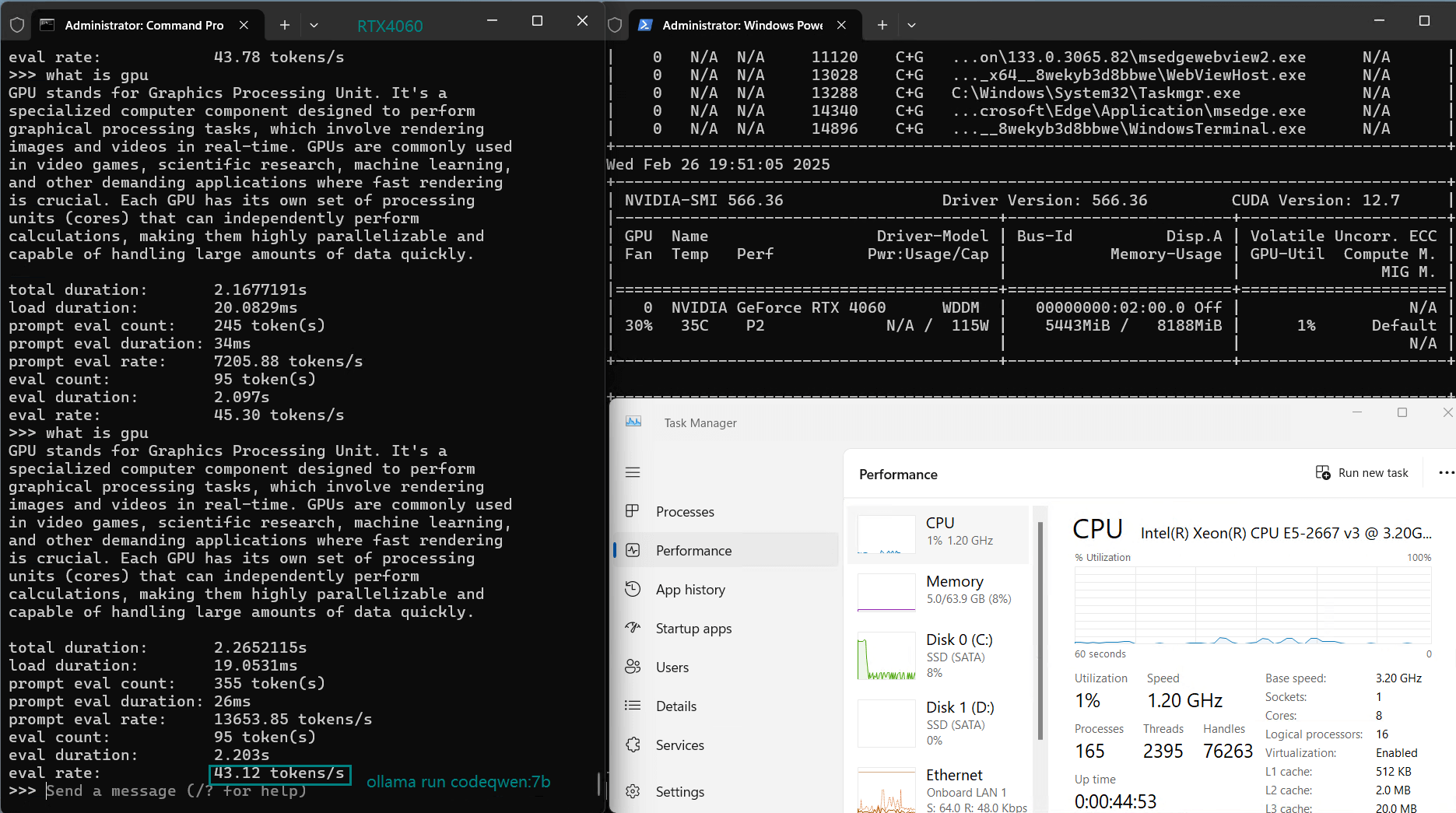
| 评估率(tokens/s) | 42.60 | 41.27 | 52.93 | 8.03 | 41.70 | 52.69 | 50.91 | 22.39 | 18.0 | 23.18 | 42.23 | 43.12 |
一段记录实时 RTX 4060 GPU 服务器资源消耗数据的视频:
使用 Nvidia RTX 4060 GPU 服务器在 Ollama 上对 LLM 进行基准测试的屏幕截图
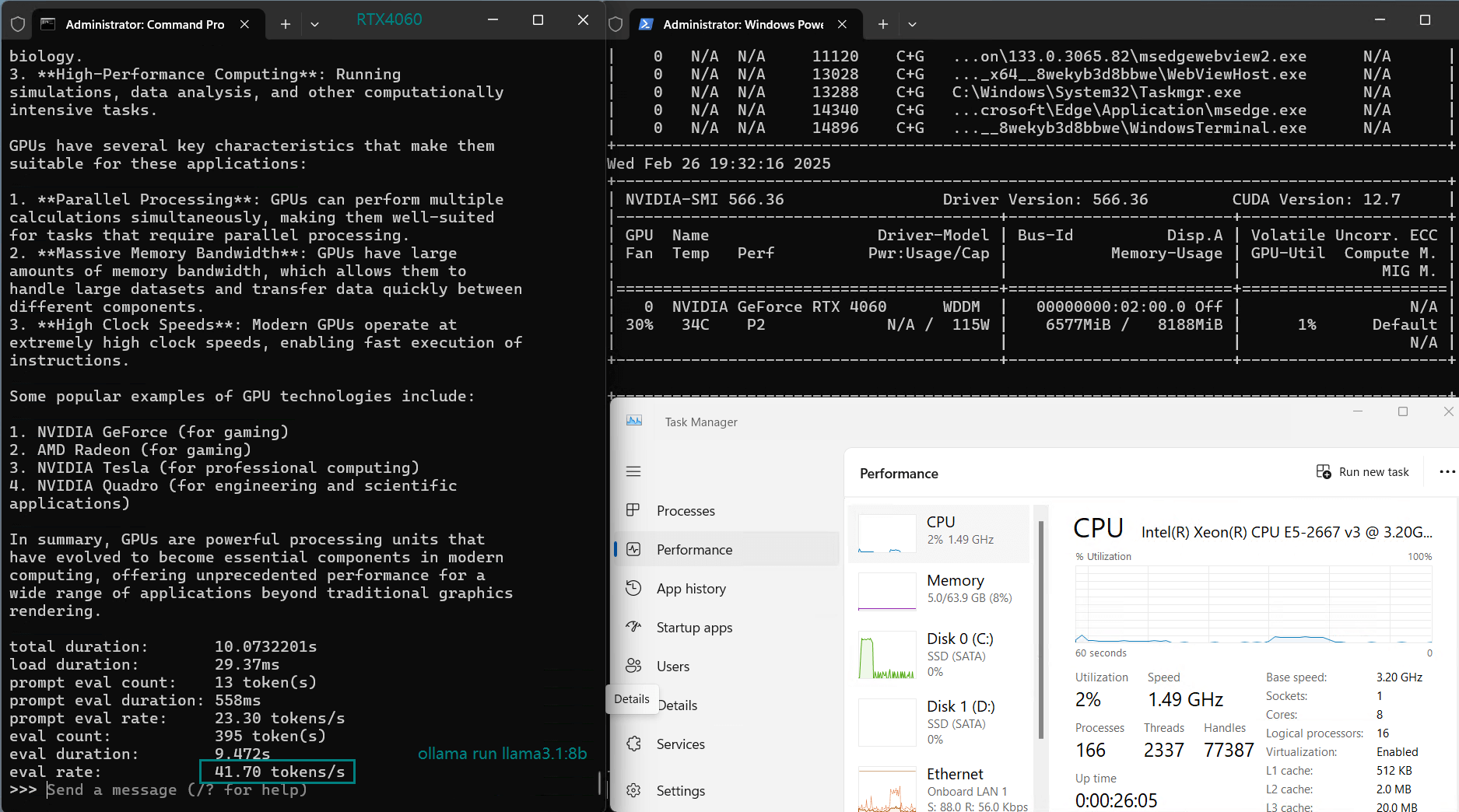
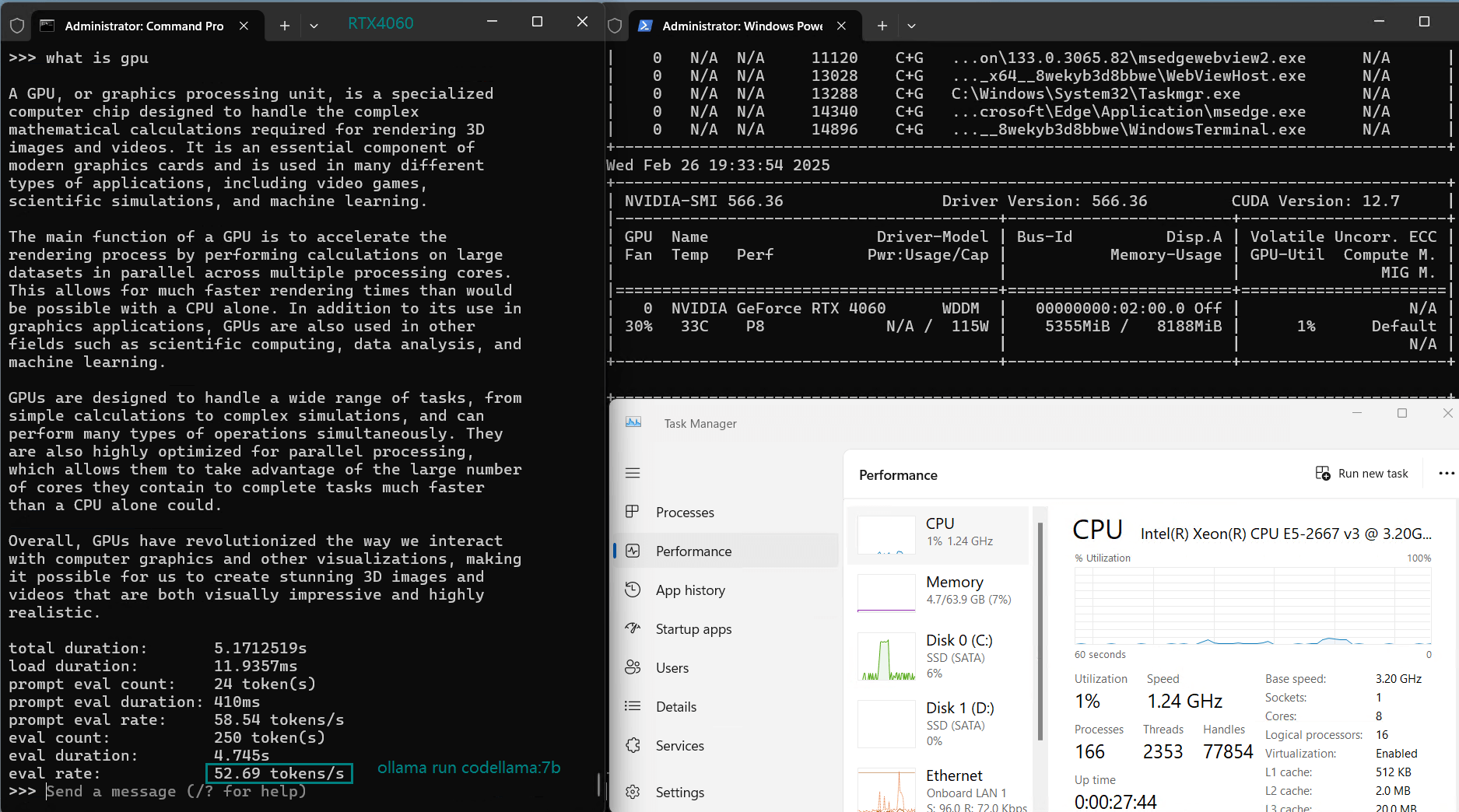
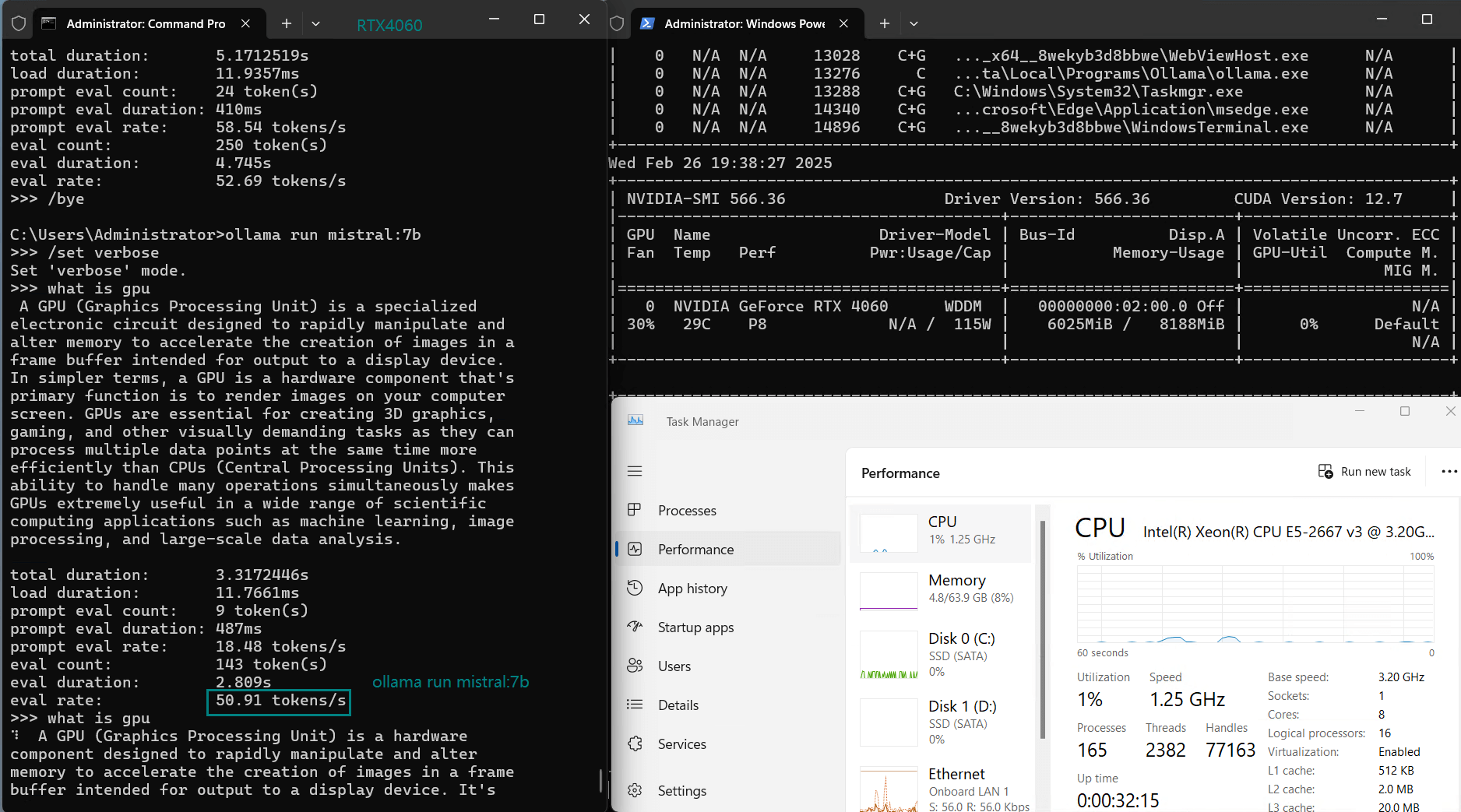
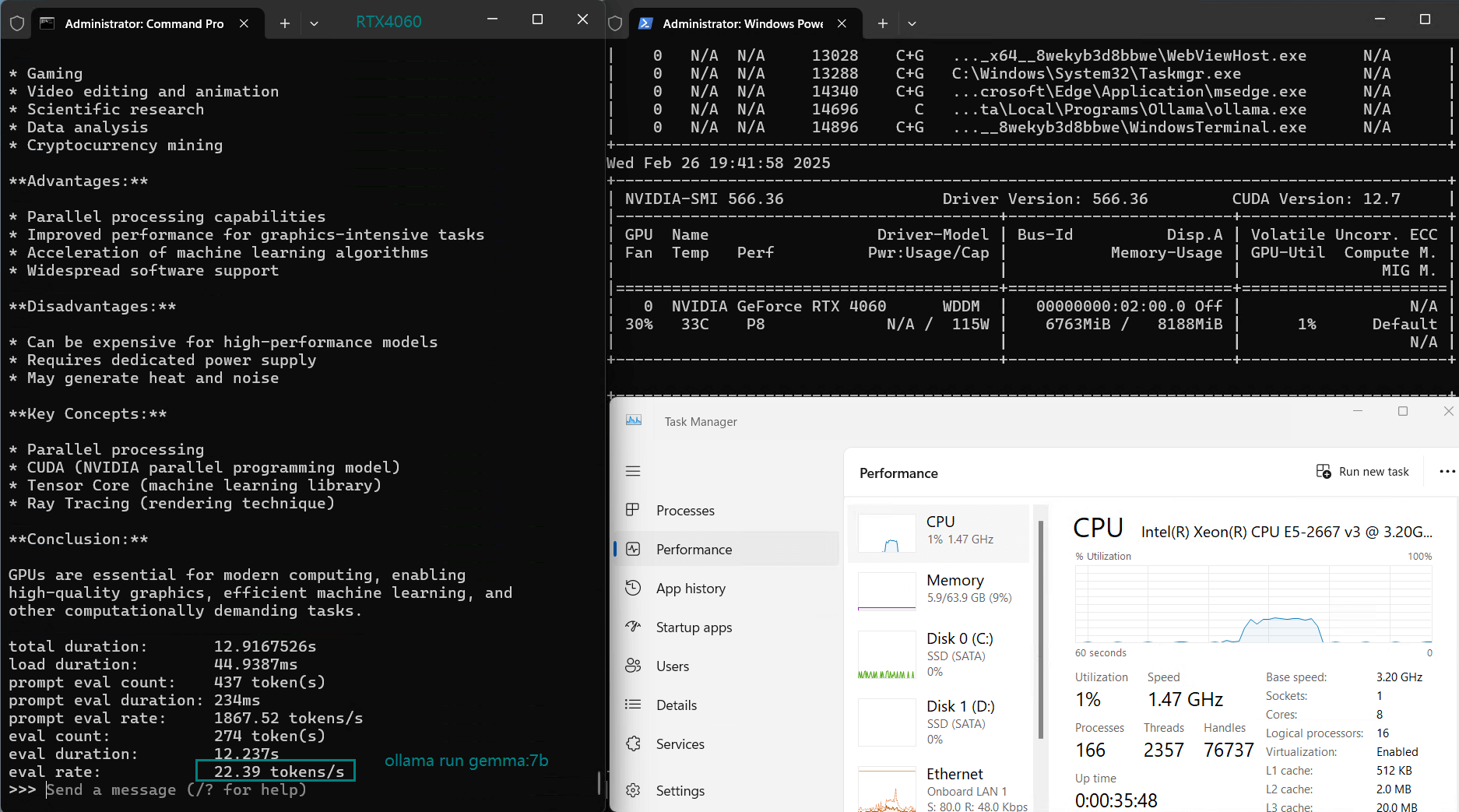
基准测试的性能分析
1️⃣. 5.0GB 以下机型的最佳选择
经过 4 位量化后,5.0GB 以下的模型可以实现 40+ token/s 的推理速度,其中 DeepSeek-Coder 和 Mistral 在 Ollama 基准测试中以 52-53 token/s 领先,非常适合高速推理。
2️⃣. 不适用于 13b 及以上型号
由于内存限制,LLaMA 2(13B)在 RTX 4060 服务器上的表现不佳,GPU 利用率较低(25-42%),这表明 RTX 4060 无法用于推断 13b 及以上的模型。
3️⃣. 当模型大小达到 5.0GB 后,速度从 40+ token/s 下降到 20+ token/s
CodeGemma 和 Gemma 2 的 CPU 利用率较高(30-32%),这表明它们可能不是高效 GPU 推理的最佳选择,可能是因为它们的模型大小超过 5.0gb,导致推理速度降低。
4️⃣. 8b及以下车型的高性价比之选
7B-8B及以下机型大多能达到较高速度运行,GPU利用率可达70%-90%,稳定在40+token/s的性能。
Nvidia RTX 4060 服务器适合 LLM 推理吗?
✅ 使用 Nvidia RTX 4060 或 Ollama 的优点
- 每月 1259.00 元即可享受 RTX 4060 主机托管服务
- 7B-8B 型号性能良好
- DeepSeek-Coder 和 Mistral 运行高效,每秒 50+ 个令牌
❌ Nvidia RTX 4060 服务器对 Ollama 的限制
- 有限的 VRAM (8GB) 难以支持 13B 型号
- LLaMA 2 (13B) 未充分利用 GPU
如果您运行的是 7B-8B 模型,那么用于 LLM 推理的 RTX 4060 是一个经济实惠的绝佳选择。但是,对于 13B 以上的模型,您可能需要具有更高 VRAM 的 Nvidia V100 或 A4000 主机。
开始使用 RTX4060 托管 LLMs
对于在 Ollama 上部署 LLM 的用户,选择合适的 NVIDIA RTX4060 托管解决方案可以显著提升性能和成本。如果您使用的是 7B-9B 及以下型号,RTX4060 是价格实惠的 AI 推理的可靠选择。
GPU云服务器 - A4000
¥ 1109.00/月
月付季付年付两年付
立即订购- 配置: 24核32GB, 独立IP
- 存储: 320GB SSD系统盘
- 带宽: 300Mbps 不限流
- 赠送: 每2周一次自动备份
- 系统: Win10/Linux
- 其他: 1个独立IP
- 独显: Nvidia RTX A4000
- 显存: 16GB GDDR6
- CUDA核心: 6144
- 单精度浮点: 19.2 TFLOPS
GPU物理服务器 - V100
¥ 1849.00/月
月付季付年付两年付
立即订购- CPU: 24核E5-2690v3*2
- 内存: 128GB DDR4
- 系统盘: 240GB SSD
- 数据盘: 2TB SSD
- 系统: Win10/Linux
- 其他: 独立IP,100M-1G带宽
- 独显: Nvidia V100
- 显存: 16GB HBM2
- CUDA核心: 5120
- 单精度浮点: 14 TFLOPS
概括
对于 9B 及以下型号,Nvidia RTX 4060 是经济实惠的选择。7B-8B 及以下型号大多数运行流畅,GPU 利用率达到 70%-90%,推理速度稳定在 40+ token/s。它是一款经济高效的 LLM 推理解决方案。
标签:
Ollama 4060、Ollama RTX4060、Nvidia RTX4060 托管、RTX4060 基准测试、Ollama 基准测试、用于 LLM 推理的 RTX4060、Nvidia RTX4060 租赁