



















在 Ollama 上使用 NVIDIA V100 GPU 服务器 对大型语言模型(LLMs)进行基准测试
随着大型语言模型(LLM)推理和 AI 模型部署需求的不断增长,寻找最佳的 GPU 托管解决方案变得至关重要。NVIDIA V100 服务器因其计算性能、价格和可用性之间的平衡,而成为 LLM 推理的热门选择。在本次基准测试中,我们在 Ollama 平台上使用 NVIDIA V100(16GB)GPU 服务器对多种 LLM 进行了测试,分析了包括 Token 评估速度、GPU 利用率以及资源消耗等性能指标。
测试服务器配置
在深入 V100 Ollama 基准测试之前,先快速查看一下我们的测试服务器规格:
服务器配置:
- 价格:2099元/月
- CPU:双 12 核 E5-2690v3(24 核 & 48 线程)
- 内存:128GB
- 存储:240GB SSD + 2TB SSD
- 网络:100Mbps
- 操作系统:Windows 11 Pro
GPU详细信息:
- 显卡:NVIDIA V100 16GB
- 计算能力 7.0
- 微架构:Volta
- CUDA 核心数:5,120
- 张量核心:640
- GPU内存:16GB HBM2
- FP32 性能:14 TFLOPS
该 NVIDIA V100 托管配置在成本与性能之间实现了最佳平衡,是 AI 托管、深度学习和 LLM 部署的理想选择。
在 Ollama 上使用 NVIDIA V100 服务器 对大型语言模型(LLMs)进行基准测试
使用 Ollama 0.5.11,我们测试了多种大型语言模型(LLMs),包括 DeepSeek、LLaMA 2、Mistral 和 Qwen。以下是我们基准测试的主要结果。
| 模型 | deepseek-r1 | deepseek-r1 | deepseek-r1 | deepseek-coder-v2 | llama2 | llama2 | llama3.1 | mistral | gemma2 | gemma2 | qwen2.5 | qwen2.5 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 参数 | 7b | 8b | 14b | 16b | 7b | 13b | 8b | 7b | 9b | 27b | 7b | 14b |
| 大小(GB) | 4.7 | 4.9 | 9 | 8.9 | 3.8 | 7.4 | 4.9 | 4.1 | 5.4 | 16 | 4.7 | 9.0 |
| 量化 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| 正在运行 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 |
| 下载速度(mb/s) | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 |
| CPU 速率 | 2% | 2% | 3% | 3% | 2% | 3% | 3% | 3% | 3% | 42% | 3% | 3 |
| 内存速率 | 5% | 6% | 5% | 5% | 5% | 5% | 5% | 6% | 6% | 7% | 5% | 6% |
| GPU 执行时间 | 71% | 78% | 80% | 70% | 85% | 87% | 76% | 84% | 69% | 13~24% | 73% | 80% |
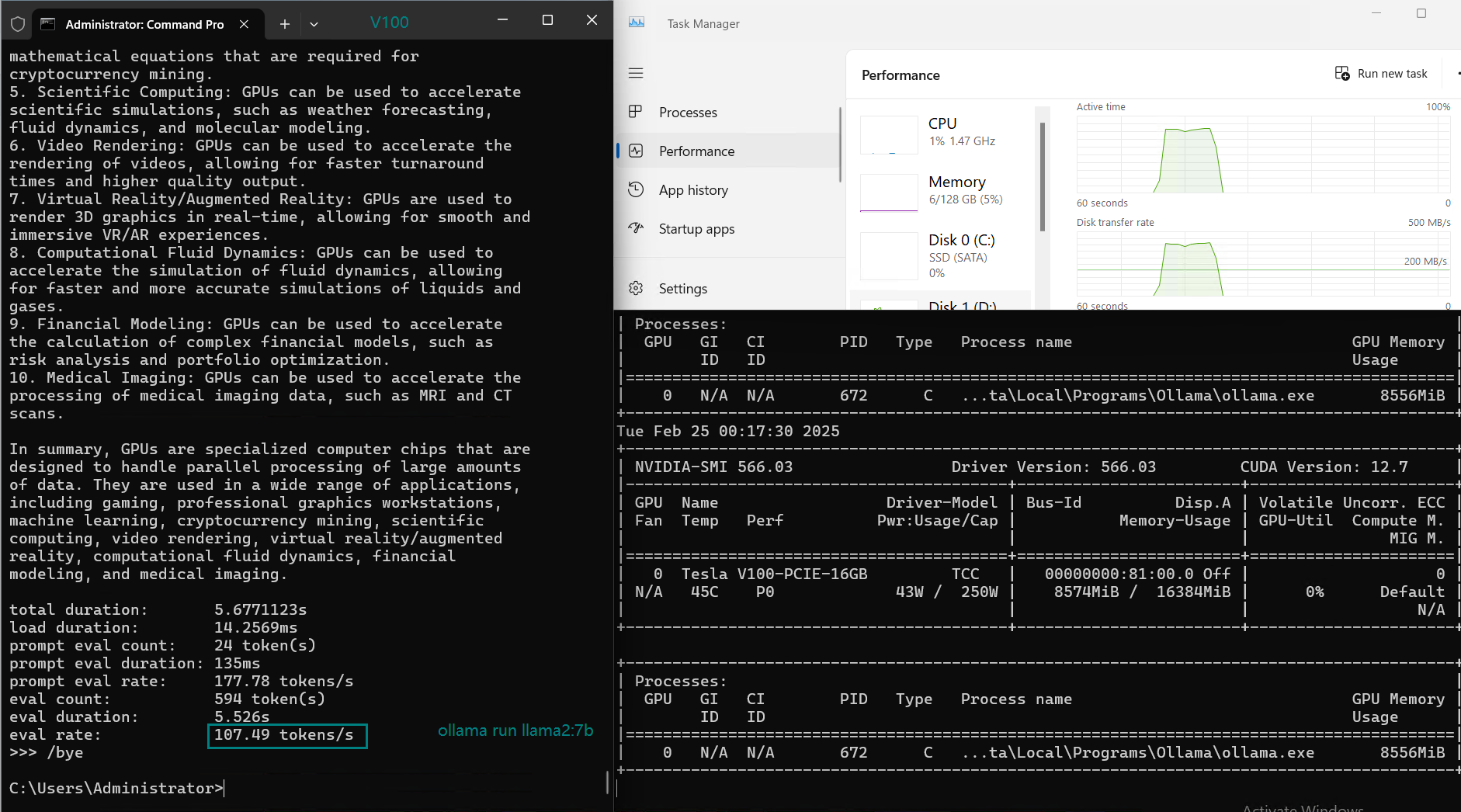
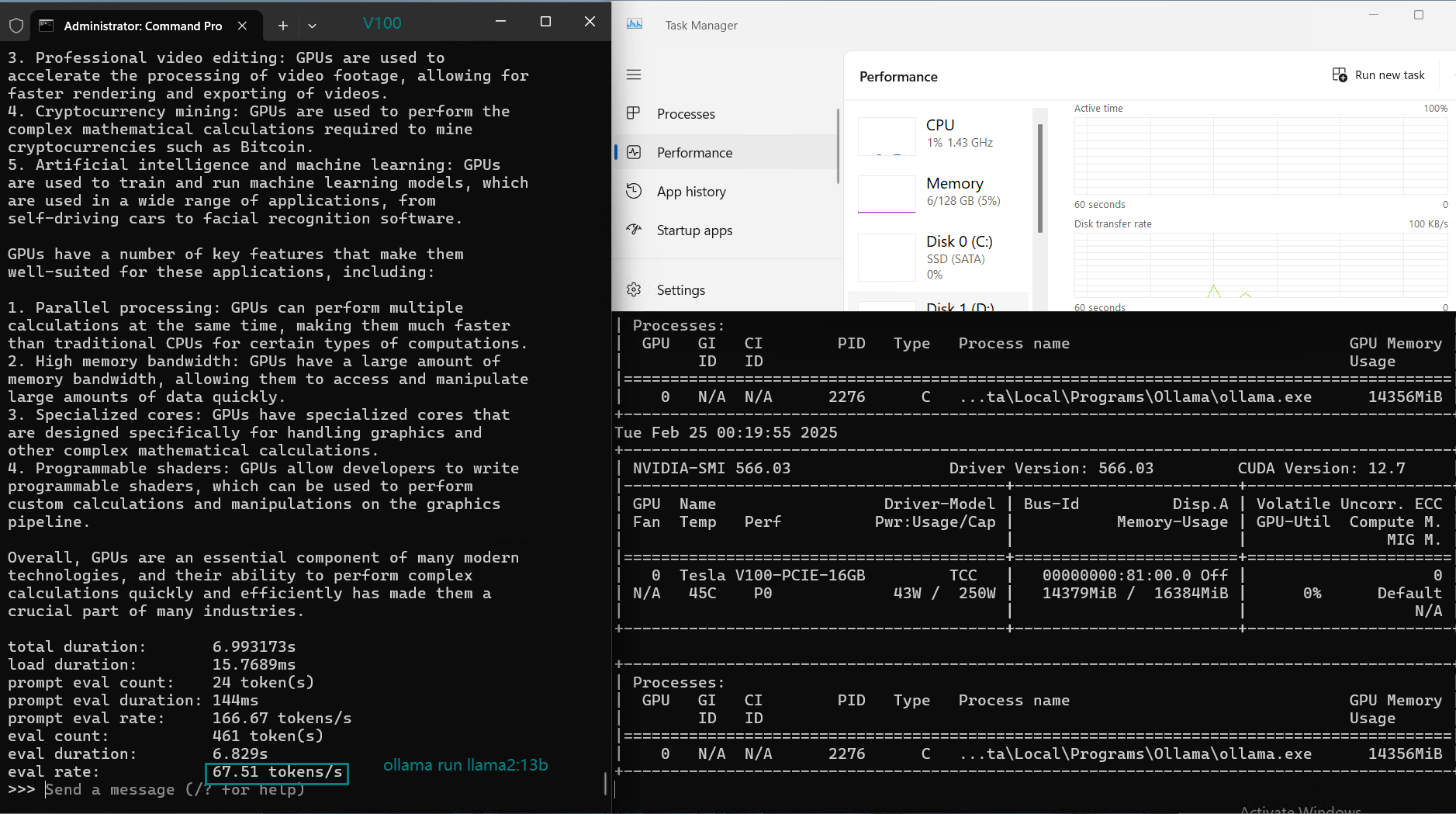
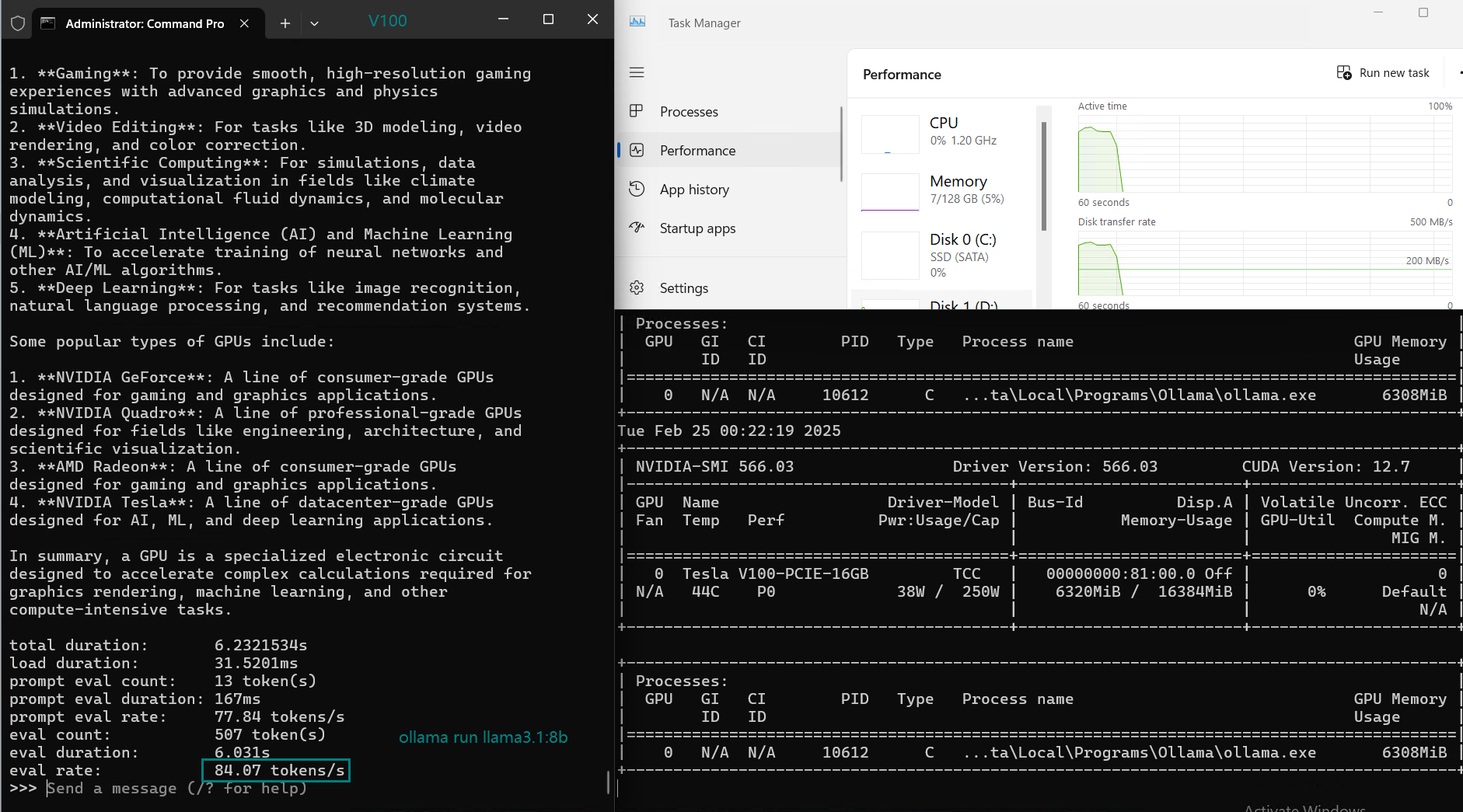
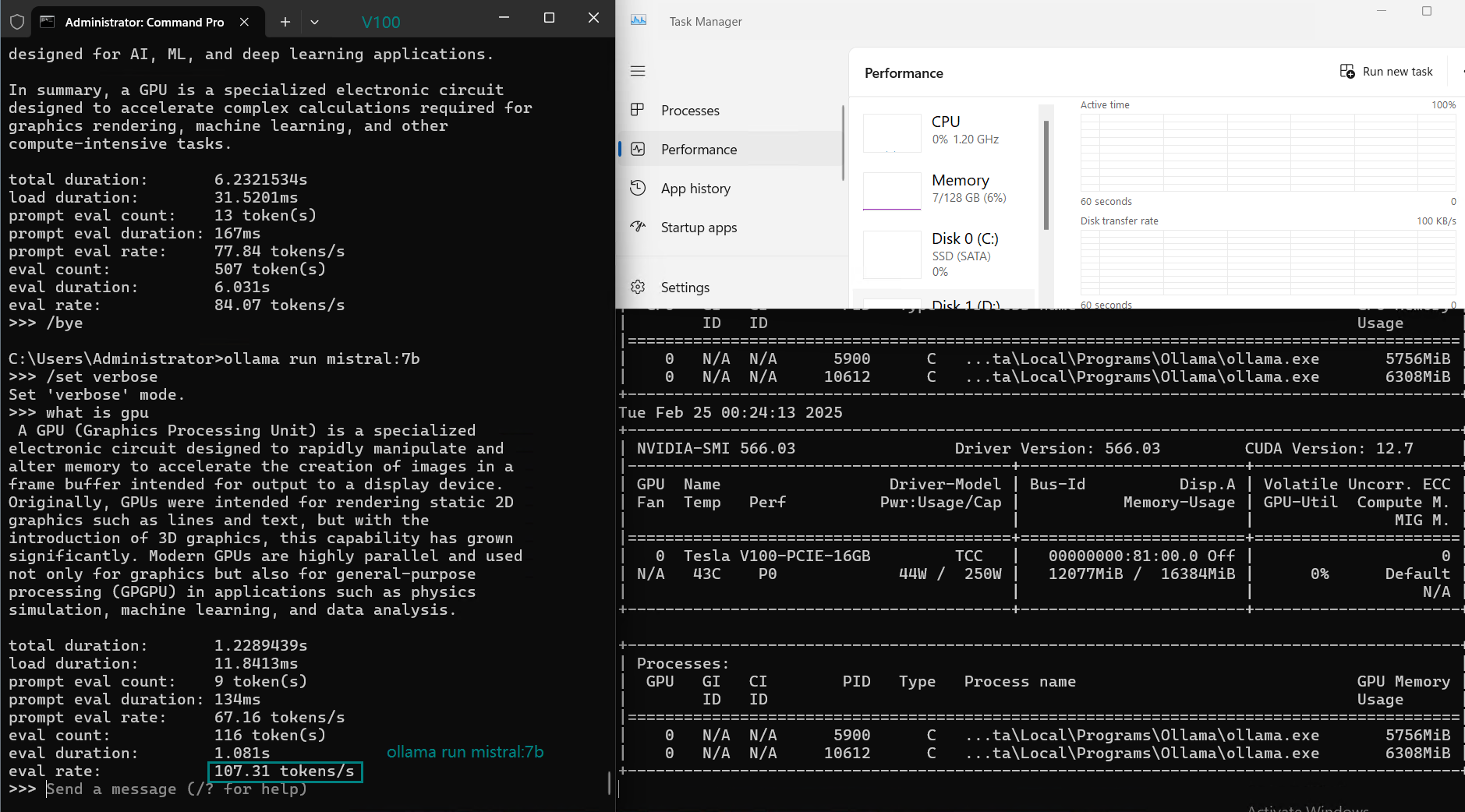
| 评估率(令牌/秒) | 87.10 | 83.03 | 48.63 | 69.16 | 107.49 | 67.51 | 84.07 | 107.31 | 59.90 | 8.37 | 86.00 | 49.38 |
A video to record real-time V100 gpu server resource consumption data:
在 Ollama 上使用 Nvidia V100 GPU 对大型语言模型(LLMs)进行基准测试的截图
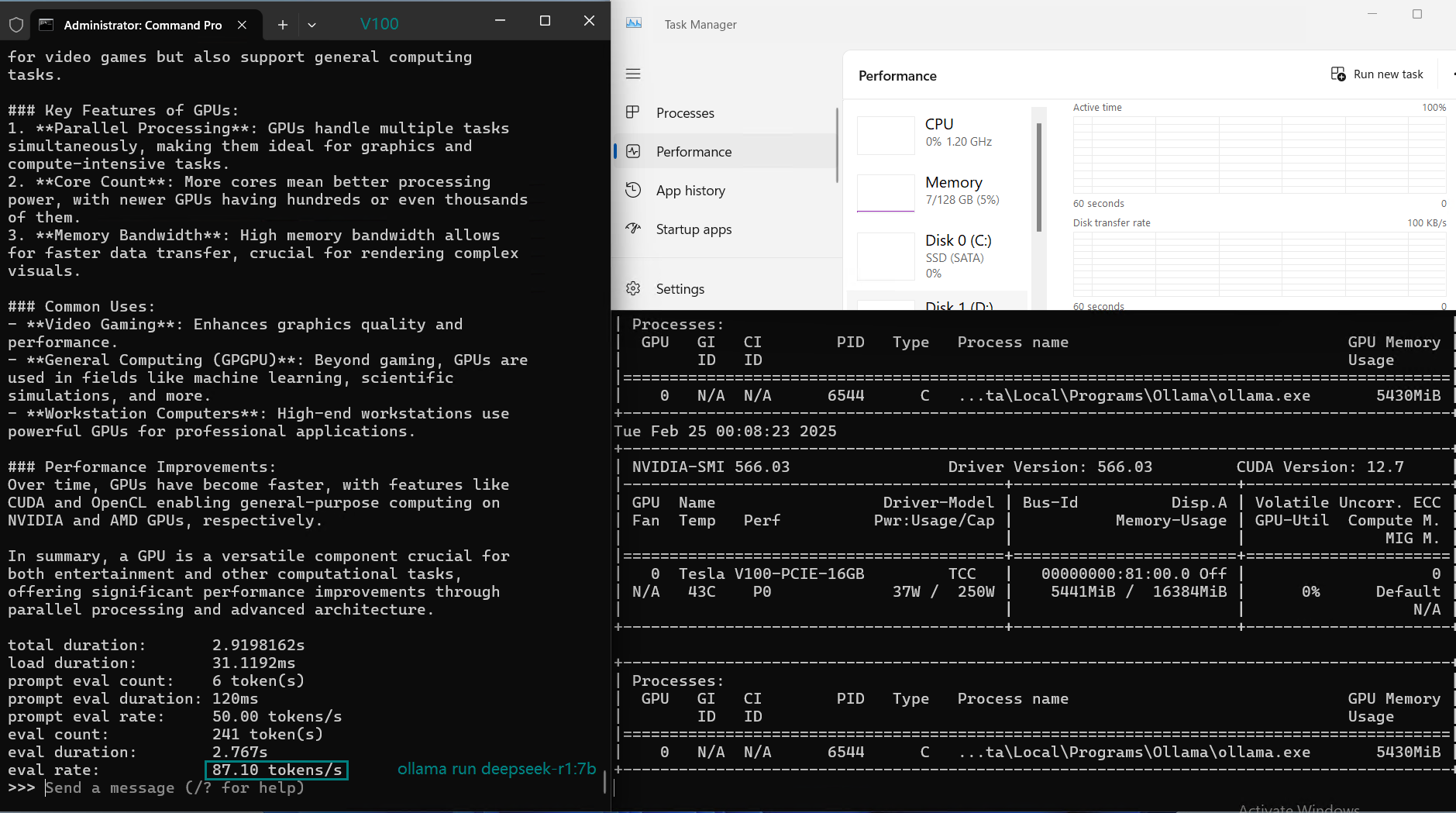
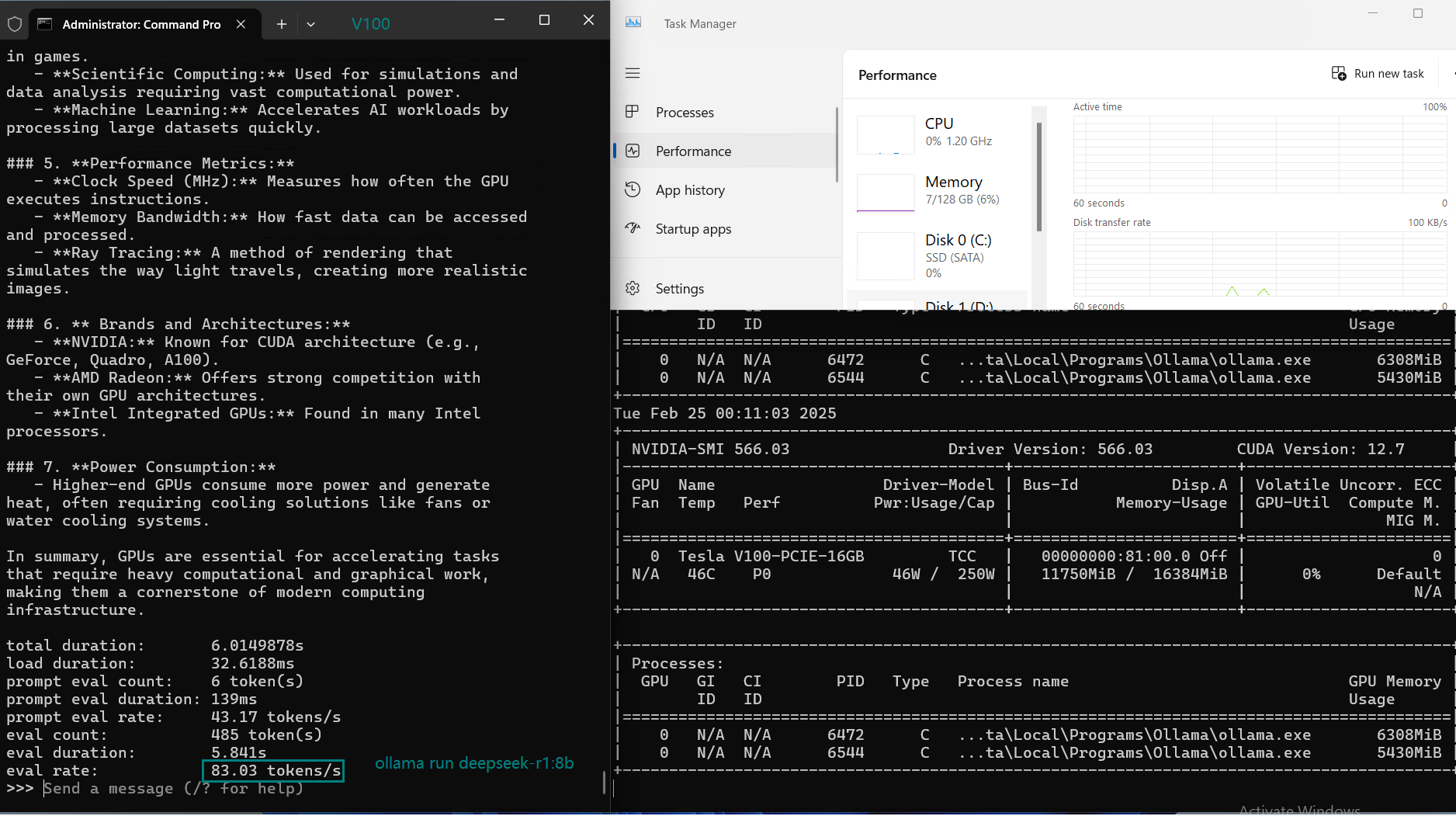
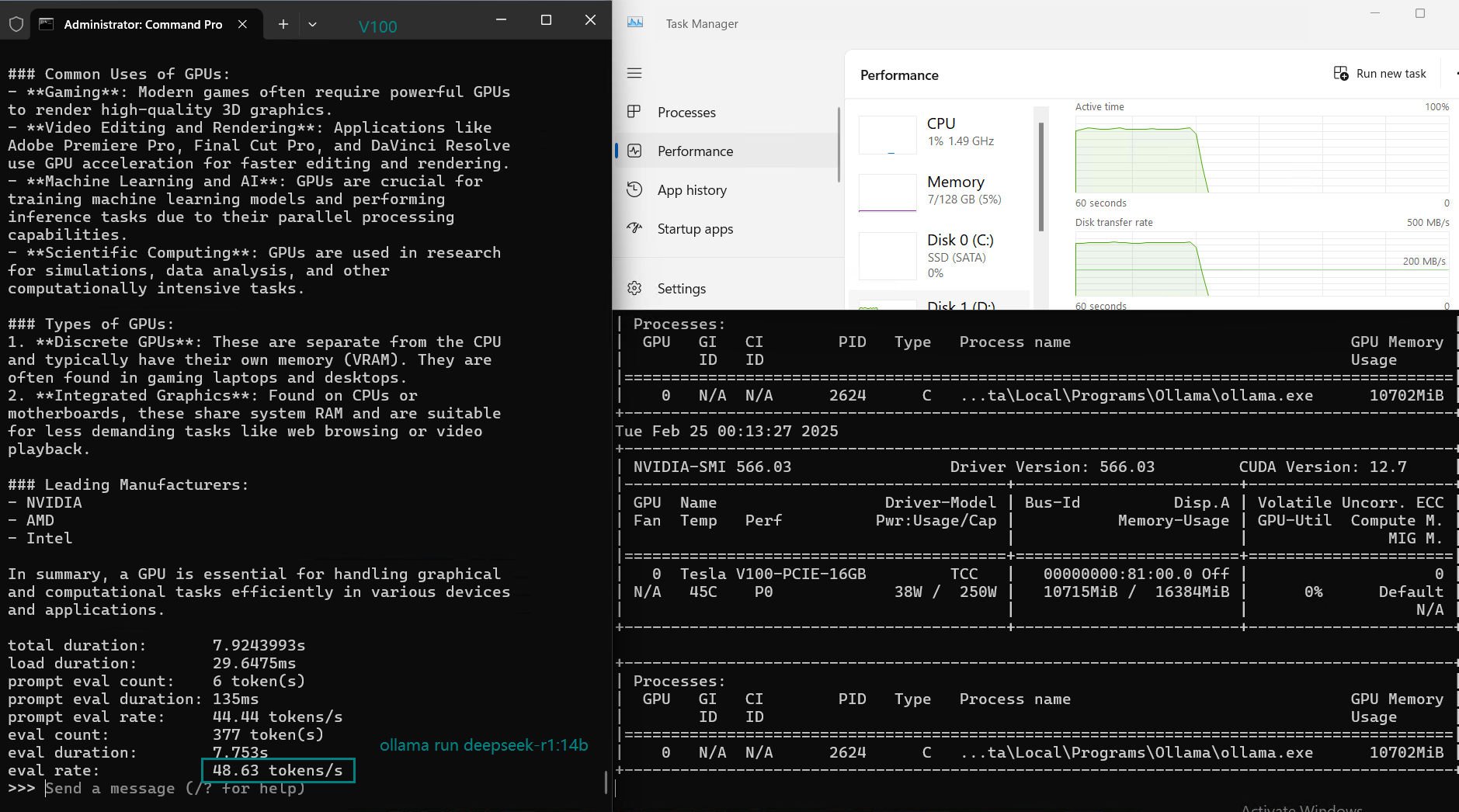
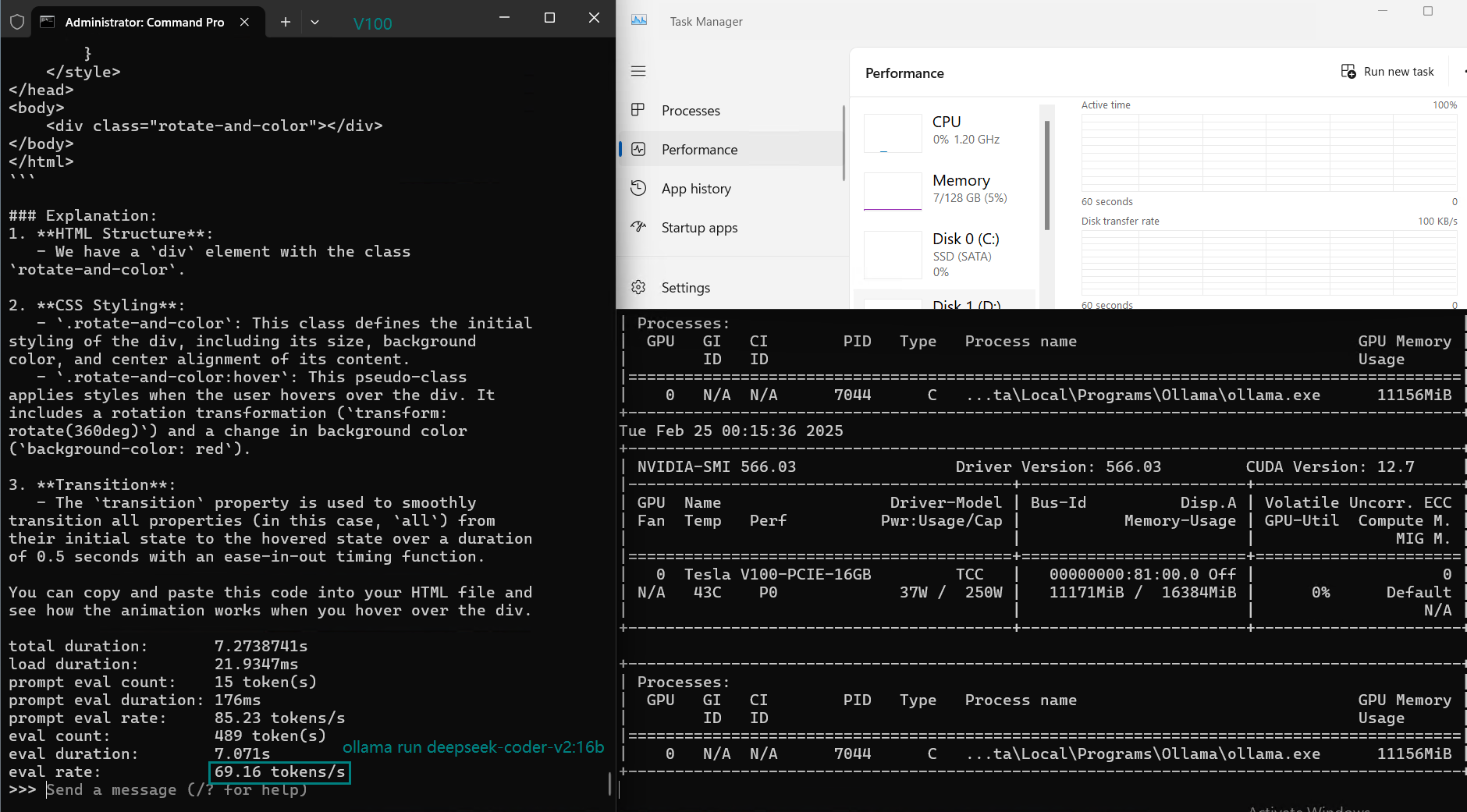
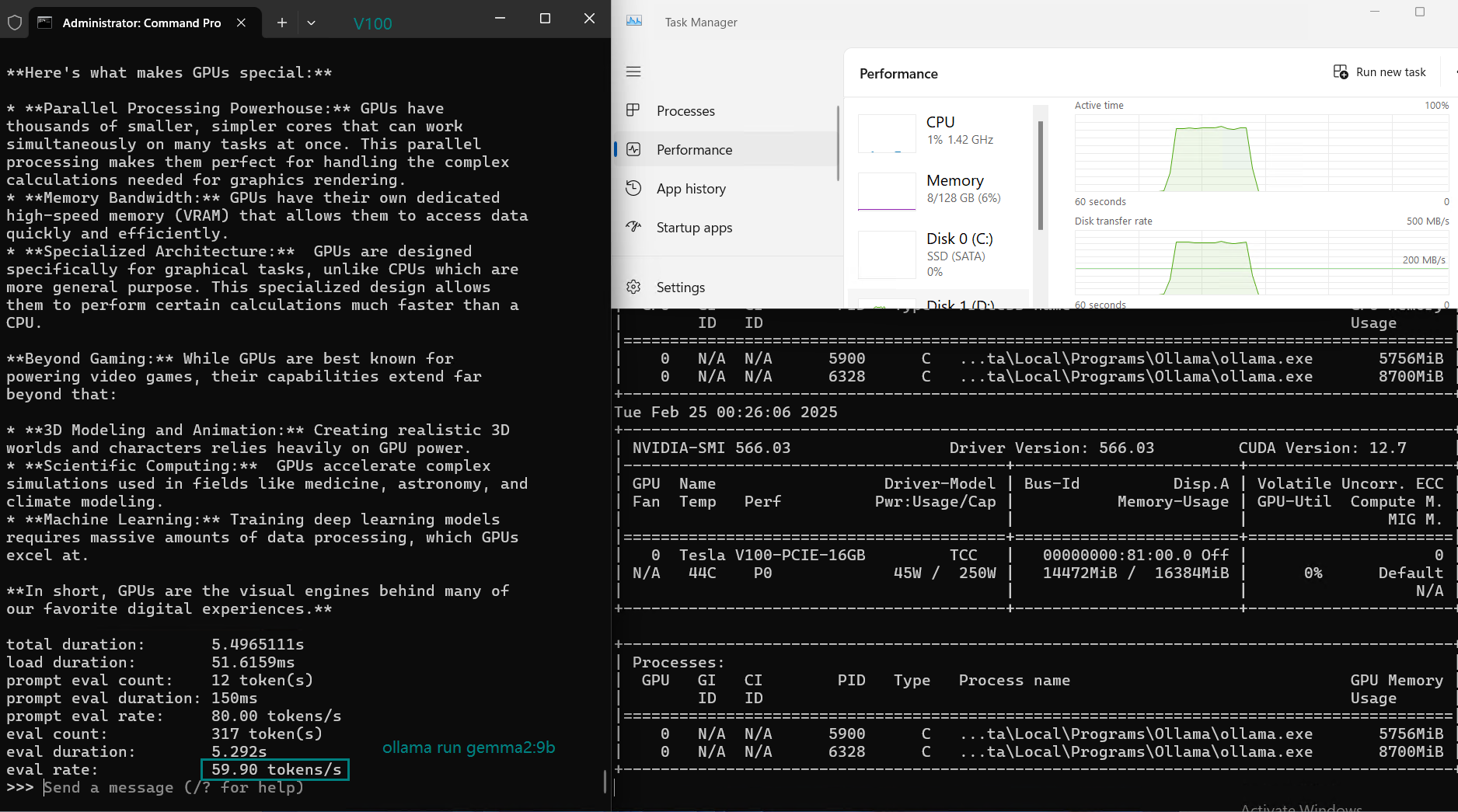
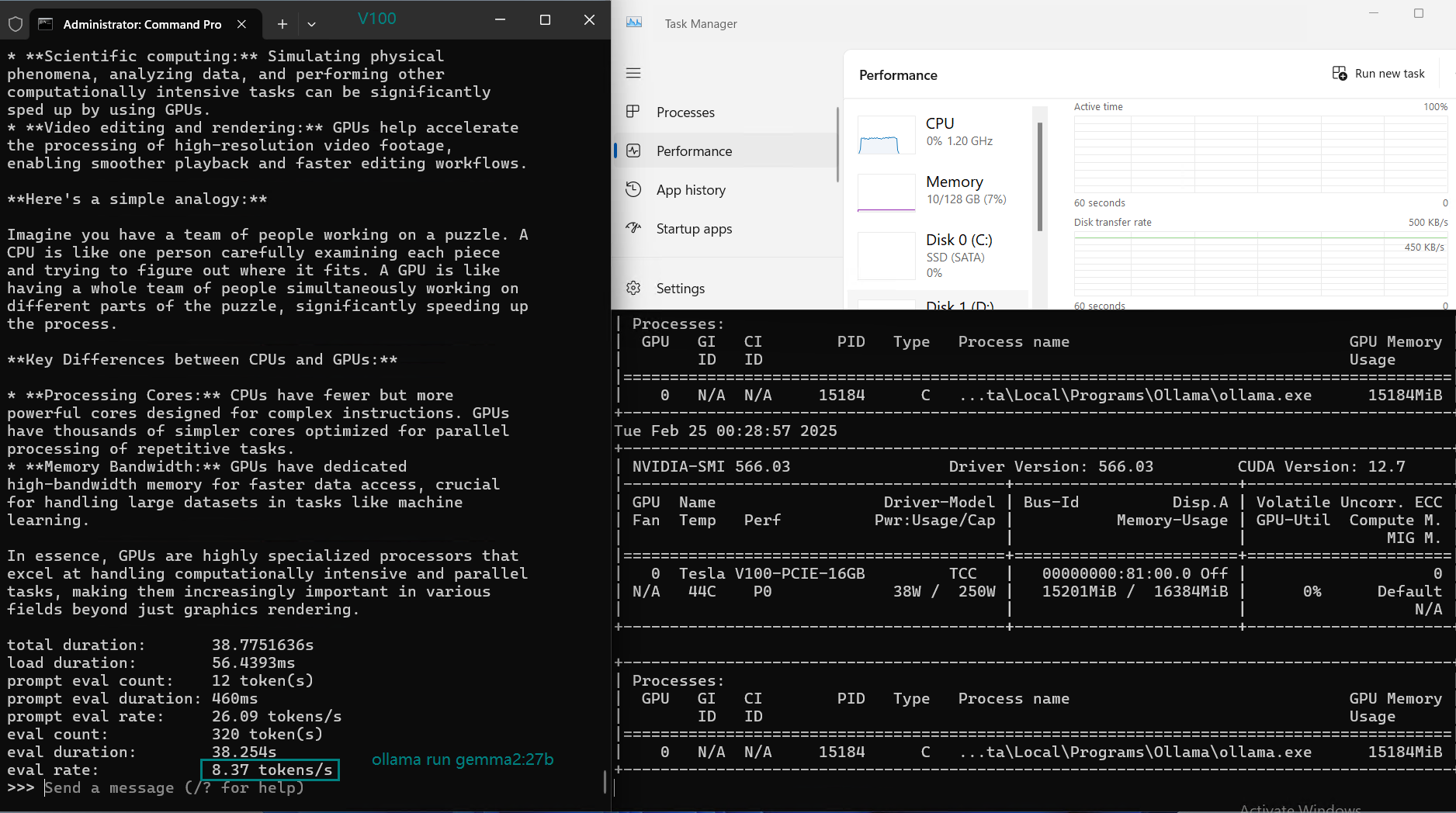
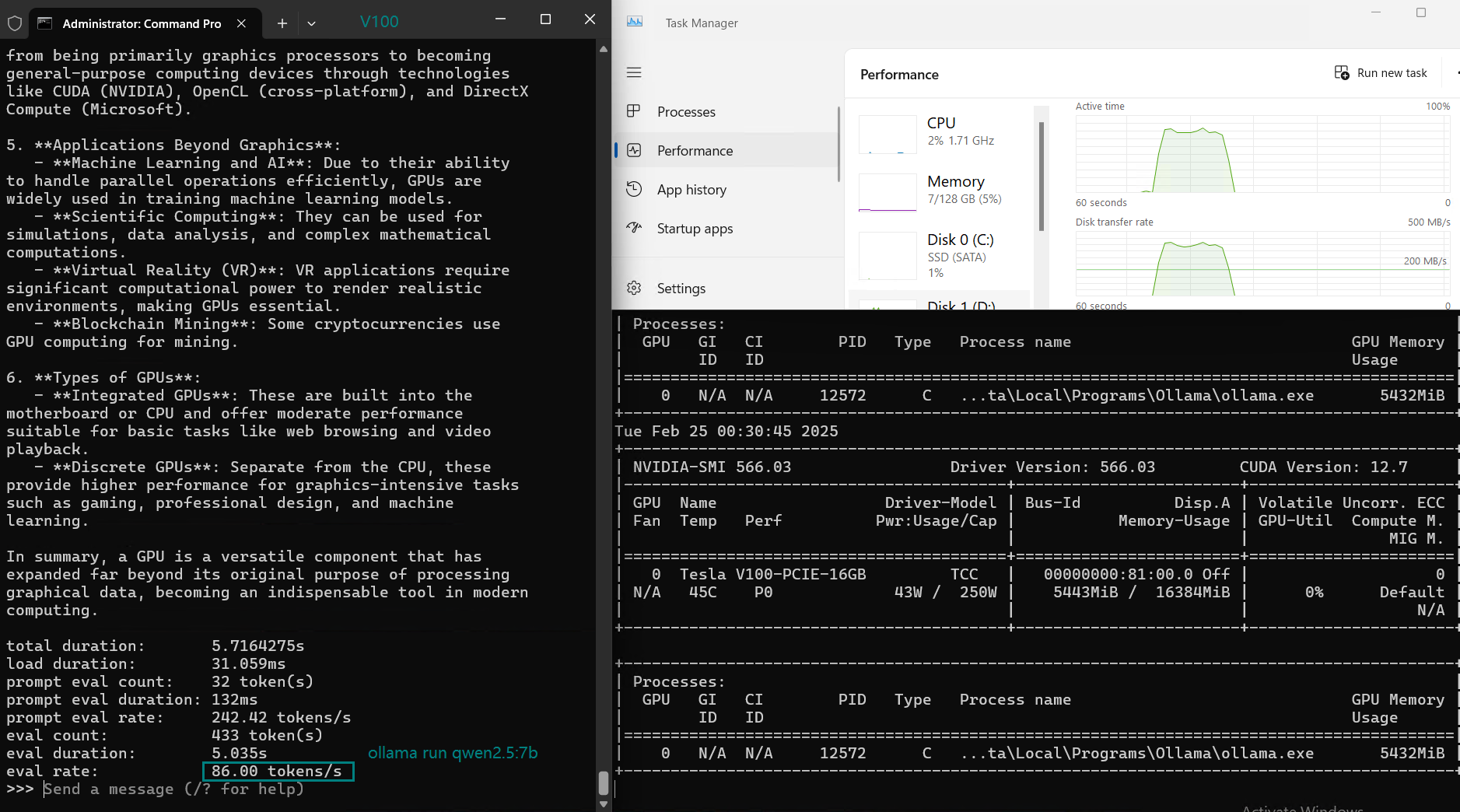
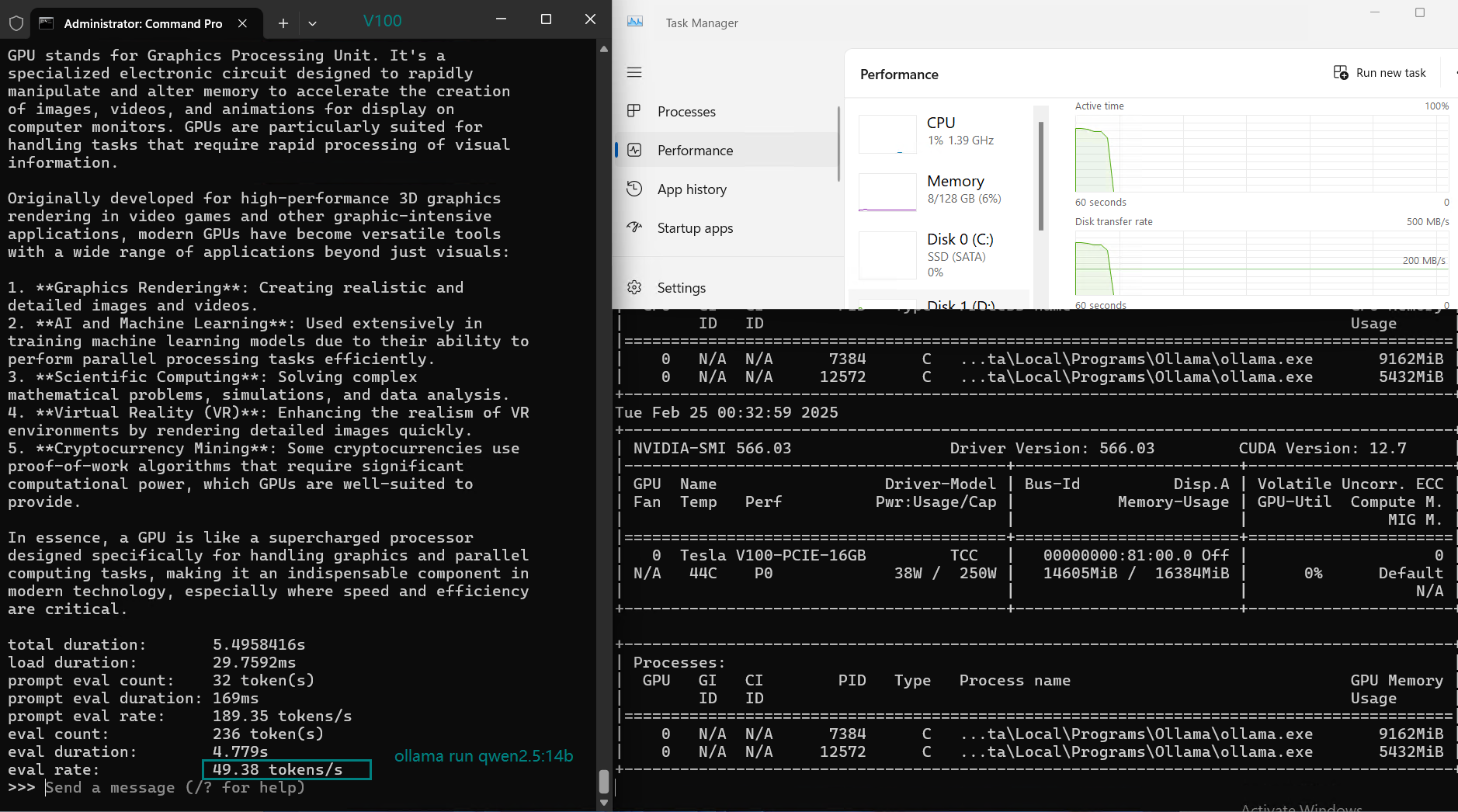
NVIDIA V100 Ollama 基准测试的主要结论
1. 性能最佳的 LLM:LLaMA 2 (7B) 和 Mistral (7B)
- LLaMA 2 (7B) 和 Mistral (7B) 都能提供最高的 Token 评估速度(每秒 107+ 个 Token)。.
- 非常适合实时推理、聊天机器人以及需要快速响应的 AI 应用。
2. 中等规模模型(13-14B)性能略有下降
- DeepSeek 14B、Qwen 14B 和 LLaMA 2 13B 的评估速度有所下降(约 50 tokens/s)。
- 较高的 GPU 利用率(约 80-87%)导致延迟增加。
- 对于 13B-14B 模型,NVIDIA V100 托管仍然是最佳选择。
3. 不适合运行大型模型(27B 以上)
- gemma2:27B 的评估速度降至 8.37 tokens/s,这表明 V100 无法有效推理 27B 以上 的模型。
4. GPU 利用率与资源效率
- GPU 利用率在 70% 到 87% 之间,表明 Ollama 在 V100 上能高效管理工作负载。
- CPU 和内存使用率保持较低(约 2-6%),这为潜在的多实例部署提供了可能。
NVIDIA V100 托管是否适合用于 Ollama 的 LLM 推理?
1. 在 Ollama 上使用 NVIDIA V100 的优势
- 与更新的 A100/H100 服务器相比,性价比高且广泛可用。
- 对于 7B-24B 的模型,内存(16GB)与计算能力之间保持良好平衡。
- 对于经过优化的模型(如 LLaMA 2 和 Mistral),推理速度强劲。
- 由于对 CPU/内存需求适中,可高效运行多个小型模型。
2. 在 Ollama 上使用 NVIDIA V100 的局限性
- 对于大型模型(27B 以上)表现不佳,导致评估速度变慢。
- 16GB 显存限制了多 GPU 扩展能力。
- 不适合训练,仅适用于推理工作负载。
开始使用 V100 服务器托管 LLM
对于在 Ollama 上部署 LLM 的用户,选择合适的 NVIDIA V100 托管方案会显著影响性能和成本。对于 7B-24B 的模型,V100 是进行 AI 推理的高性价比可靠选择。
GPU物理服务器 - V100
¥ 1849.00/月
月付季付年付两年付
立即订购- CPU: 24核E5-2690v3*2
- 内存: 128GB DDR4
- 系统盘: 240GB SSD
- 数据盘: 2TB SSD
- 系统: Win10/Linux
- 其他: 独立IP,100M-1G带宽
- 独显: Nvidia V100
- 显存: 16GB HBM2
- CUDA核心: 5120
- 单精度浮点: 14 TFLOPS
GPU云服务器 - A4000
¥ 1109.00/月
月付季付年付两年付
立即订购- 配置: 24核32GB, 独立IP
- 存储: 320GB SSD系统盘
- 带宽: 300Mbps 不限流
- 赠送: 每2周一次自动备份
- 系统: Win10/Linux
- 其他: 1个独立IP
- 独显: Nvidia RTX A4000
- 显存: 16GB GDDR6
- CUDA核心: 6144
- 单精度浮点: 19.2 TFLOPS
GPU物理服务器 - RTX 3060 Ti
¥ 1499.00/月
月付季付年付两年付
立即订购- CPU: 24核E5-2697v2*2
- 内存: 128GB DDR3
- 系统盘: 240GB SSD
- 数据盘: 2TB SSD
- 系统: Win10/Linux
- 其他: 独立IP,100M-1G带宽
- 独显:RTX 3060 Ti
- 显存: 8GB GDDR6
- CUDA核心: 4864
- 单精度浮点: 16.2 TFLOPS
GPU物理服务器 - P100
¥ 1239.00/月
月付季付年付两年付
立即订购- CPU: 16核E5-2660*2
- 内存: 128GB DDR3
- 系统盘: 120GB SSD
- 数据盘: 960GB SSD
- 系统: Win10/Linux
- 其他: 独立IP,100M-1G带宽
- 独显: Nvidia Tesla P100
- 显存: 16GB GDDR6
- CUDA核心: 3584
- 单精度浮点: 9.5 TFLOPS
最终结论:V100 托管是否值得用于 Ollama?
对于寻求高性价比 LLM 托管方案的用户,NVIDIA V100 租用服务提供了经济实惠的选择,可用于部署 LLaMA 2、Mistral 和 DeepSeek-R1 等模型。借助 Ollama 高效的推理引擎,V100 在 7B-24B 参数 的模型上表现良好,非常适合聊天机器人、AI 助手及其他实时 NLP 应用。
然而,对于更大的模型(24B 以上),需要升级至 RTX4090(24GB) 或 A100(40GB)。请问您在您的 NVIDIA V100 服务器上运行哪些 LLM 模型?欢迎在评论区告诉我们!
标签:
Ollama, LLM, NVIDIA V100, AI, 深度学习, Mistral, LLaMA2, DeepSeek, GPU, 机器学习, AI 推理